Author: Denis Avetisyan
Researchers are leveraging neural networks to automatically calibrate complex labor market models, offering a more efficient path to understanding economic dynamics.
This paper evaluates the SBI4ABM framework for parameter estimation in agent-based labor market models, demonstrating scalability with synthetic data but identifying limitations in data integration and the robustness of learned summary statistics.
Estimating parameters in large-scale agent-based models remains a significant challenge despite advances in computational power. This study, ‘Neural Network-Based Parameter Estimation of a Labour Market Agent-Based Model’, evaluates a simulation-based inference framework leveraging neural networks to address this limitation within the context of a labour market model built on job transition networks. Results demonstrate that this neural network-based approach can efficiently recover original parameters and scale with synthetic datasets, offering improvements over traditional Bayesian methods. However, further investigation is needed to assess its robustness when integrating real-world data and validating the reliability of learned summary statistics for complex system calibration.
Deconstructing Complexity: The Limits of Traditional Modeling
Many conventional modeling approaches rely on aggregated data and assume system-wide averages, which inherently simplify the nuanced behaviors arising from individual components and their interactions. This simplification proves problematic when studying complex systems – from ecological networks and social phenomena to economic markets and immune responses – where emergent patterns are often driven by these very individual-level dynamics. Traditional methods frequently struggle to capture the heterogeneity of agents, the localized nature of their interactions, and the feedback loops that amplify or dampen effects across the system. Consequently, these models can miss critical tipping points, underestimate the impact of rare events, or produce predictions that deviate significantly from observed reality, highlighting the need for approaches that explicitly account for individual agency and interaction.
Agent-based modeling presents a compelling shift from traditional system dynamics by simulating the actions of autonomous, individual entities – agents – and how their interactions generate emergent, large-scale behaviors. Unlike approaches that rely on aggregate variables and equations, ABM allows for the representation of diverse agent characteristics and decision-making processes, offering a more nuanced understanding of complex phenomena. However, this power comes with a significant hurdle: parameterization. Accurately defining the rules governing each agent’s behavior, and the probabilities associated with their interactions, requires substantial data and careful calibration. The sheer number of parameters in a realistic ABM can quickly become computationally intractable, and uncertainty in these values can propagate through the model, impacting the reliability and validity of its results. Consequently, researchers are actively developing innovative techniques to efficiently estimate parameters from observed data, ensuring that the simulated world faithfully reflects the complexities of the real one.
The predictive power of agent-based models hinges significantly on the accuracy of their parameters, as these values dictate how individual agents behave and interact within the simulated system. Simply calibrating a model to reproduce a few observed outcomes is insufficient; true validation requires demonstrating that the model generalizes to unseen conditions and accurately reflects underlying processes. Consequently, researchers are increasingly turning to sophisticated inference techniques – including Approximate Bayesian Computation, machine learning algorithms, and sensitivity analysis – to navigate the high-dimensional parameter spaces inherent in complex ABMs. These methods allow for a more rigorous assessment of parameter uncertainty and enable the identification of key drivers of system behavior, ultimately enhancing the credibility and utility of agent-based simulations for forecasting and policy evaluation.
Bayesian Inference: A Framework for Understanding Uncertainty
Bayesian theory provides a formal structure for parameter estimation by treating parameters as random variables with associated probability distributions. This allows researchers to explicitly incorporate existing knowledge, termed “prior” distributions, into the inference process. Rather than yielding single-point estimates, Bayesian inference produces a “posterior” distribution – a probability distribution over the parameter space conditional on the observed data. This posterior reflects the updated belief about the parameters, accounting for both the prior knowledge and the evidence from the data. Crucially, the posterior also inherently quantifies the uncertainty associated with the parameter estimates via measures like credible intervals, offering a more complete representation of parameter knowledge than traditional frequentist methods. The process is mathematically defined by Bayes’ Theorem: P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)}, where P(\theta|D) is the posterior, P(D|\theta) is the likelihood, P(\theta) is the prior, and P(D) is the marginal likelihood or evidence.
Calculating the likelihood function – the probability of observing the given data given a specific set of model parameters – presents a significant challenge for complex Agent-Based Models (ABMs). This intractability arises from the combinatorial complexity inherent in ABM simulations; each parameter setting requires numerous model runs to generate sufficient data for statistical comparison, and analytically determining the probability distribution of model outputs is often impossible. Traditional methods relying on closed-form likelihood expressions or gradient-based optimization become computationally prohibitive or fail entirely as the number of parameters and model complexity increase. Consequently, alternative inference methods, such as simulation-based inference, are required to estimate parameters without explicitly defining or computing the likelihood function.
Simulation-Based Inference (SBI) circumvents the need for an explicit likelihood function by directly comparing model simulations to observed data. This is achieved through repeated model runs with varying parameter sets, generating a distribution of potential outcomes. SBI then employs statistical methods – such as Approximate Bayesian Computation (ABC) or Sequential Monte Carlo (SMC) – to assess the compatibility of each parameter set with the observed data, effectively creating a posterior distribution of plausible parameter values without requiring a mathematically defined likelihood. The core principle involves quantifying the distance between simulated and observed data, accepting parameter sets that produce simulations closely matching the observations, and rejecting those that do not, ultimately estimating the posterior parameter distribution based on simulation results.
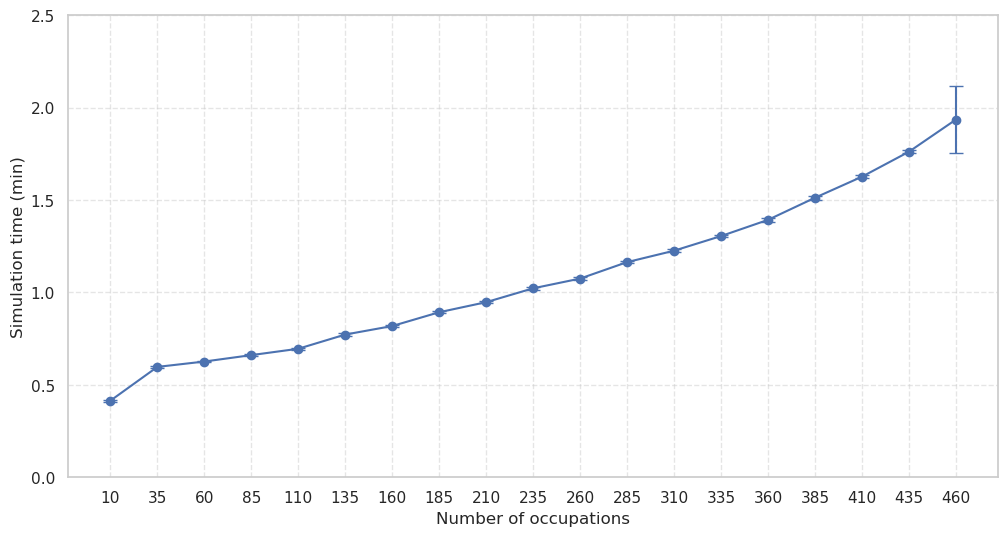
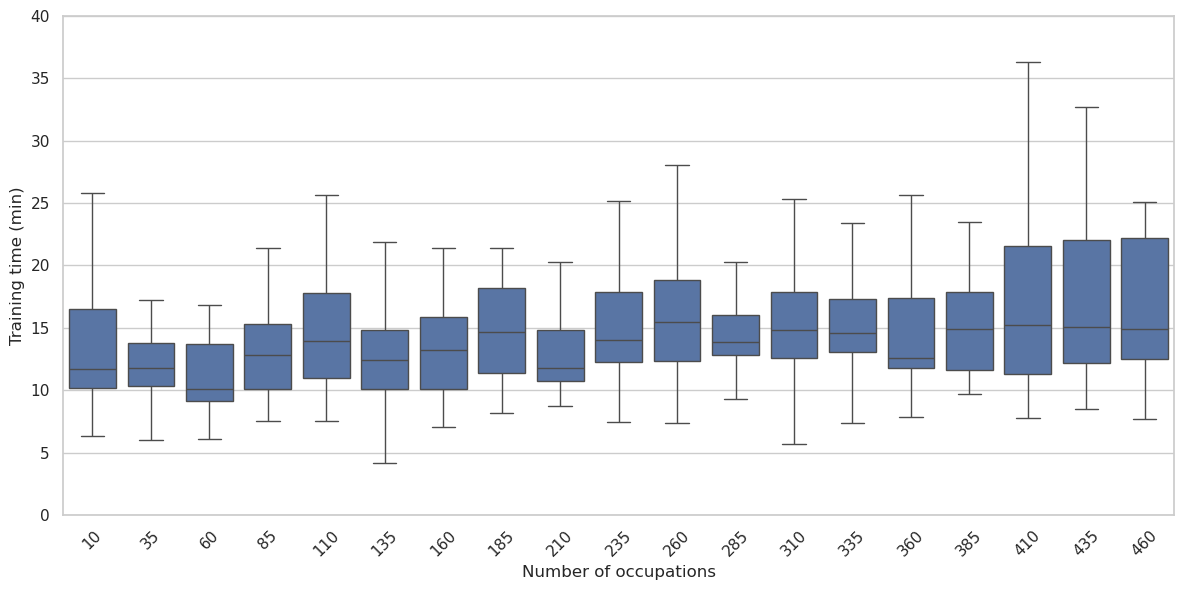
SBI4ABM builds upon Simulation-Based Inference (SBI) to address the challenges posed by high-dimensional parameter spaces common in Agent-Based Models (ABMs). Traditional SBI methods can become computationally prohibitive as the number of parameters increases; SBI4ABM mitigates this through the integration of machine learning techniques, specifically surrogate models, to approximate the forward model and accelerate the inference process. Critically, empirical results demonstrate that SBI4ABM achieves linear scalability with respect to the occupation count – the number of simulated parameter sets required to adequately represent the parameter space – indicating its suitability for ABMs with a large number of tunable parameters. This linear scaling contrasts with the exponential growth often observed in traditional inference methods when applied to high-dimensional problems.
Neural Networks: Approximating Complexity for Efficient Inference
Within the SBI4ABM framework, Neural Networks (NNs) are utilized to approximate the Posterior Distribution, a critical component of Bayesian inference. This is achieved by training NNs to function as surrogate models, effectively learning the complex mapping between model parameters and the resulting simulation outputs. Instead of directly evaluating the computationally expensive Agent-Based Model (ABM) for each parameter candidate, SBI4ABM leverages the trained NN to rapidly predict the corresponding simulation outcome. This allows for efficient sampling and evaluation of the parameter space, enabling the identification of parameter sets that best explain observed data, and ultimately approximating the posterior distribution without repeatedly running the full ABM simulation.
Neural networks within SBI4ABM function as surrogate models, trained on data generated from agent-based model (ABM) simulations to predict model outputs given specific parameter values. This predictive capability allows for the rapid assessment of numerous parameter combinations without requiring repeated execution of the computationally expensive ABM. Consequently, the parameter space can be explored much more efficiently than with traditional methods like Markov Chain Monte Carlo (MCMC), which rely on direct ABM simulation for each parameter evaluation. The NN effectively learns the mapping between parameter inputs and simulation outcomes, enabling a fast approximation of the posterior distribution and accelerating the process of finding parameters that best fit observed data.
SBI4ABM utilizes Neural Networks (NNs) to address computational limitations inherent in conventional parameter estimation techniques for Agent-Based Models (ABMs). Traditional methods, such as Markov Chain Monte Carlo (MCMC), often require numerous model simulations for each parameter candidate, leading to significant processing time for complex ABMs with high dimensionality. NNs, once trained, provide a rapid approximation of the model’s input-output relationship, allowing SBI4ABM to evaluate a larger number of parameter combinations within a given timeframe. This acceleration facilitates efficient exploration of the parameter space and enables parameter estimation for ABMs that would be computationally prohibitive using standard inference approaches.
The study determined that storing a single matrix with dimensions 1000x600x464x468, utilizing the float16 data type, requires 243.34 GB of memory. This calculation is based on the size of a float16, which is 2 bytes, and the total number of elements in the matrix (1000 600 464 * 468). This substantial memory footprint highlights the computational resources necessary when employing large matrices within the parameter estimation process, particularly when utilizing Neural Networks to approximate complex model behaviors.

Bridging Simulation and Reality: Data-Driven Validation and Calibration
The Labour Market Agent-Based Model (ABM) relies heavily on the quality and breadth of input data to generate simulations that accurately reflect real-world economic dynamics. Calibration, achieved through the SBI4ABM framework, isn’t simply a matter of plugging in numbers; it demands a convergence of Microdata – detailing individual worker and firm characteristics – and Macrodata, representing aggregate economic trends. This dual-source approach allows for a nuanced understanding of labour market complexities, moving beyond broad statistical averages to capture heterogeneous behaviours and interactions. Without robust datasets encompassing employment histories, wage distributions, firm sizes, and macroeconomic indicators, the ABM’s predictive power diminishes, and its capacity to inform policy decisions is compromised. The model’s validity, therefore, is fundamentally linked to the comprehensiveness and accuracy of the data used to define its initial conditions and ongoing parameters.
The accuracy of the Labour Market Agent-Based Model (ABM) hinges on its ability to replicate observed economic trends, and the Current Population Survey (CPS) plays a crucial role in achieving this. Serving as a benchmark of real-world employment and demographic data, the CPS allows researchers to compare the ABM’s simulated outcomes – such as unemployment rates, labor force participation, and wage distributions – against established statistical realities. This validation process isn’t merely about confirming the model’s predictions; it’s about identifying discrepancies and refining the ABM’s underlying mechanisms to ensure it accurately reflects the complexities of the labor market. By systematically comparing simulation results with CPS data, researchers can build confidence in the model’s predictive power and use it to explore the potential impacts of various policy interventions or economic shocks with greater reliability.
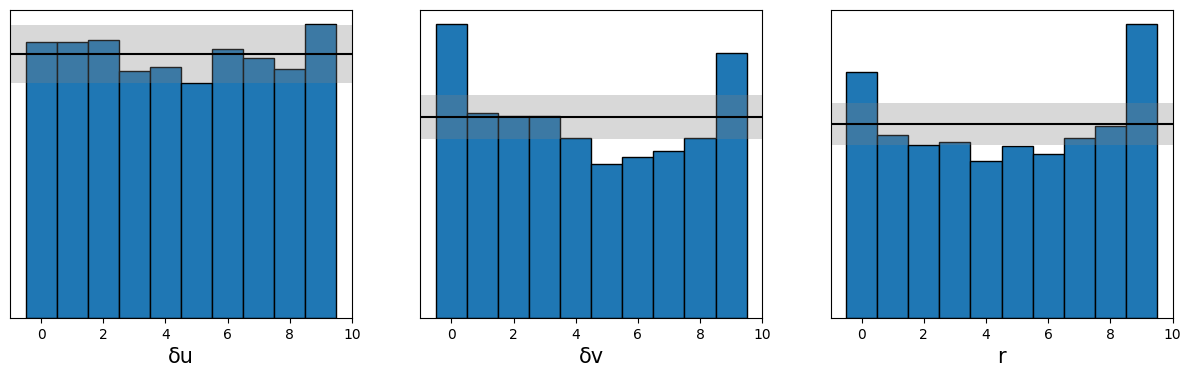
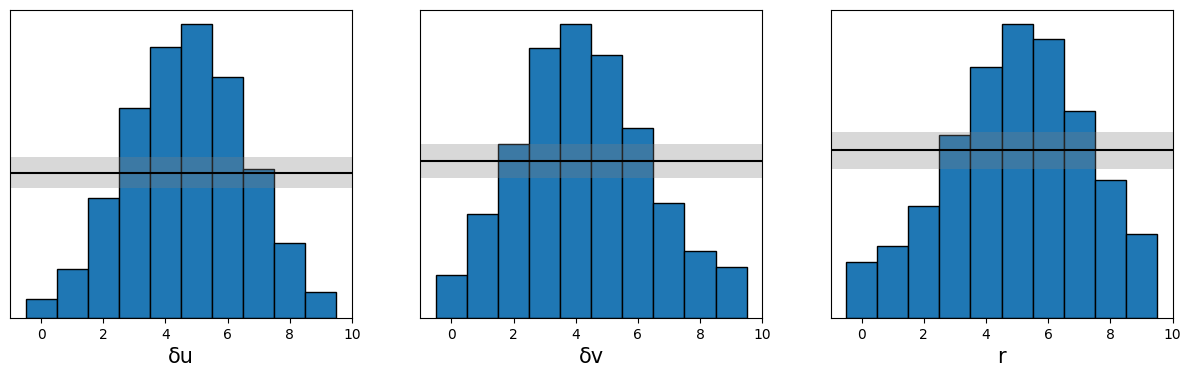
Simulation-Based Calibration (SBC) serves as a critical verification step within the Labour Market Agent-Based Model (ABM) framework, ensuring the reliability of parameter estimation. This technique assesses whether the Bayesian inference process – used to determine the most probable values for model parameters given observed data – is functioning correctly. SBC achieves this by generating numerous simulated datasets from the ABM using proposed parameter values, then comparing these simulations to the original observed data. Discrepancies between the simulated and real-world data indicate potential issues with the inference process or the model itself, allowing researchers to refine the methodology and guarantee that the resulting Posterior Distribution-representing the range of likely parameter values-accurately captures the model’s underlying behavior and predictive capabilities. Essentially, SBC provides a ‘sanity check’ on the Bayesian inference, bolstering confidence in the robustness and validity of the ABM’s results.
Statistical analysis of the labour market agent-based model’s parameters has revealed subtle, yet informative, relationships between key variables. Specifically, a weak positive correlation of 0.24 exists between \delta u and \delta v, suggesting a tendency for these parameters to fluctuate in similar directions. Furthermore, weak negative correlations – approximately -0.21 and -0.19 – were observed between rr and both \delta u and \delta v. These findings, while not strongly indicative of direct causation, offer valuable insights into the interconnectedness of the model’s internal mechanisms and provide a basis for refining parameter estimation and improving the overall realism of the simulated labour market dynamics. The subtle interplay between these parameters underscores the complexity of economic systems and the importance of detailed analysis during model calibration.
The pursuit of robust models necessitates a holistic understanding of interconnectedness. This study, evaluating the SBI4ABM framework for labor market simulations, exemplifies this principle. The challenges encountered with data integration and the reliability of learned summary statistics underscore the importance of recognizing systemic vulnerabilities. As G.H. Hardy observed, “The most powerful proof is the one which convinces the least number of people.” This resonates with the need for rigorous validation in simulation-based inference; a model’s elegance is meaningless if its outputs aren’t demonstrably trustworthy, even – or especially – when facing skeptical scrutiny. The framework’s scalability is promising, yet true strength lies in addressing the inherent weaknesses that arise from complex interactions within the system.
The Road Ahead
The exercise of fitting a complex, agent-based model to data – as demonstrated by this work – reveals a fundamental truth: the map is not the territory. One can construct a beautiful simulation, internally consistent and logically sound, yet the act of inference forces a confrontation with the messy reality of imperfect observation. The demonstrated scalability of SBI4ABM is encouraging, but scalability without reliability is merely a faster path to a flawed conclusion. The bottleneck isn’t necessarily the algorithm, but the very selection of summary statistics used to bridge the gap between model output and empirical data.
Future work must address the fragility inherent in this bridge. A focus on robust statistics, capable of weathering noise and model misspecification, is paramount. More fundamentally, the field needs to grapple with the question of what aspects of the simulated world are truly worth matching to data. To attempt a complete replication of reality is a fool’s errand; a discerning eye, guided by economic theory, must prioritize the essential mechanisms. You cannot replace the heart without understanding the bloodstream, and equally, you cannot calibrate a model without understanding its fundamental purpose.
The long-term challenge, however, is not merely technical. It is conceptual. Agent-based models are, at their core, thought experiments made concrete. Their value lies not just in prediction, but in illuminating the underlying generative processes. To treat them as black boxes, optimized solely for empirical fit, is to miss the forest for the trees. The pursuit of elegant simplicity, coupled with a rigorous understanding of structural interdependence, remains the guiding principle.
Original article: https://arxiv.org/pdf/2602.15572.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Persona PSP soundtrack will be available on streaming services from April 18
- Dungeons & Dragons Gets First Official Actual Play Series
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Spider-Man: Brand New Day LEGO Sets Officially Revealed
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Raptors vs. Cavaliers Game 2 Results According to NBA 2K26
2026-02-18 11:38