Author: Denis Avetisyan
A new review examines the potential – and limitations – of using large language models to predict time series data, revealing when these powerful tools genuinely outperform traditional methods.
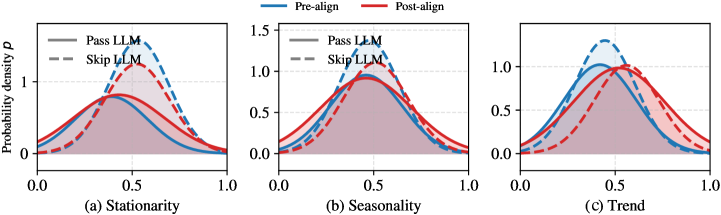
This research investigates the benefits of cross-dataset learning, pre-alignment strategies, and the impact of statistical properties on the performance of language models for time series forecasting.
Despite growing interest in applying large language models (LLMs) to time series forecasting (TSF), questions remain regarding their genuine utility beyond traditional numerical methods. This research, ‘Rethinking the Role of LLMs in Time Series Forecasting’, presents a large-scale investigation-spanning 8 billion observations and 17 forecasting scenarios-demonstrating that LLMs do improve forecasting performance, particularly in cross-domain generalization, when strategically implemented. Our findings reveal that both pretraining and model architecture contribute complementary benefits, and that careful consideration of alignment strategies is crucial for success. Under what conditions can we reliably harness the power of LLMs to unlock new levels of accuracy and robustness in time series analysis?
Discerning Temporal Foundations: The Core of Accurate Forecasting
Accurate time series forecasting isn’t simply about extrapolating past data; it fundamentally depends on discerning the underlying statistical characteristics inherent within the series itself. Before applying any modeling technique, a thorough examination for components like the overall Trend, repeating Seasonality, and the critical property of Stationarity is paramount. A non-stationary series, where statistical properties change over time, necessitates transformations – such as differencing – to stabilize the data before modeling. Identifying these key properties allows for the selection of appropriate forecasting algorithms and parameter tuning, dramatically improving the reliability and precision of predictions. Failing to account for these foundational statistical elements often leads to models that poorly generalize to new data, rendering forecasts inaccurate and potentially misleading.
The predictive power of time series analysis hinges on recognizing fundamental patterns within the data, most notably trend, seasonality, stationarity, and shifting. A trend represents the long-term increase or decrease in the data, while seasonality describes recurring patterns at fixed intervals – think of increased retail sales during the holidays. Crucially, stationarity – the property of a time series with a constant mean and variance over time – is often a prerequisite for many forecasting models; non-stationary data may require transformations to stabilize these characteristics. Finally, abrupt shifts in the data’s underlying process, such as a change in consumer behavior after a major event, must be identified and accounted for to avoid inaccurate predictions. Ignoring these core components can lead to models that fail to capture the true dynamics of the time series, diminishing their effectiveness and reliability.
Robust time series forecasting hinges on a thorough understanding of how a series transitions between states and whether it exhibits stationarity. A time series is considered stationary if its statistical properties, such as mean and variance, remain constant over time; non-stationary series require transformations – like differencing – to achieve stationarity before modeling. Analyzing transition patterns involves identifying shifts in the series’ behavior, potentially revealing underlying regime changes or structural breaks. These transitions can manifest as abrupt level changes, shifts in trend, or alterations in seasonal components. Failing to account for non-stationarity or ignoring critical transition points can lead to inaccurate forecasts and unreliable predictions, as models trained on non-stationary data may extrapolate past trends indefinitely or fail to capture evolving dynamics. Therefore, assessing these characteristics is not merely a preliminary step, but a fundamental requirement for building forecasting models that generalize well to future observations.
LLM4TSF: A Paradigm Shift in Time Series Modeling
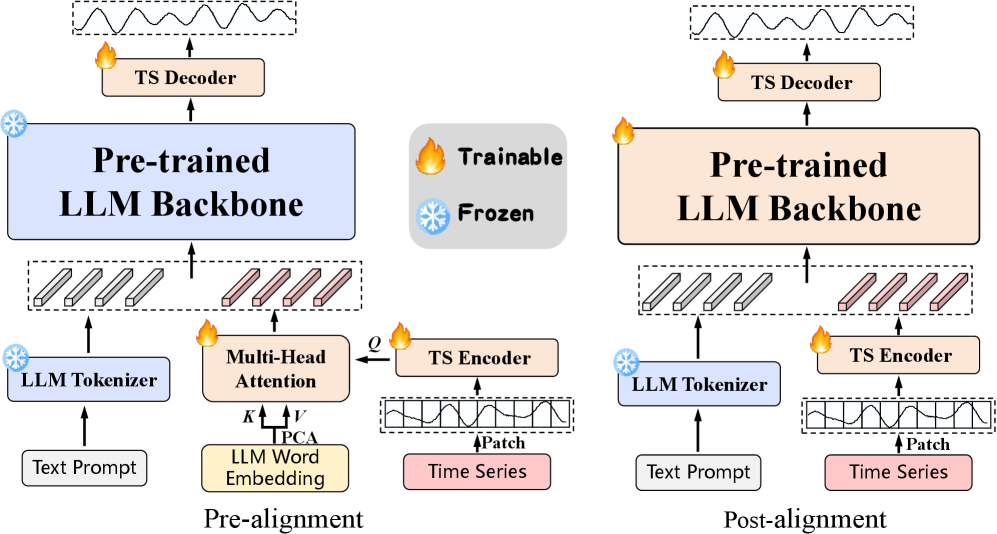
The application of LLM4TSF represents a significant departure from traditional time series forecasting methodologies by utilizing the capabilities of large language models (LLMs). Historically, time series analysis has relied on statistical methods and dedicated machine learning architectures like recurrent neural networks. LLM4TSF instead frames time series data as a sequence amenable to LLM processing, enabling the model to learn complex temporal dependencies and potentially generalize to unseen patterns more effectively. This approach allows for the incorporation of contextual information and external data sources, broadening the scope of analysis beyond purely numerical data and opening possibilities for improved accuracy and interpretability in forecasting tasks.
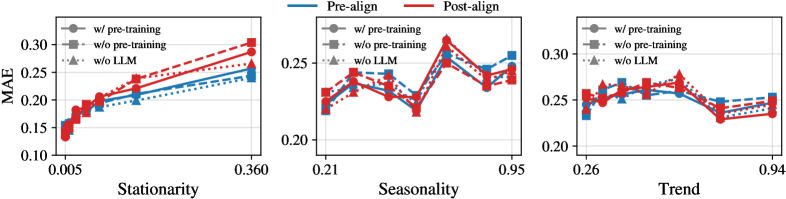
Pre-Alignment is a data preparation technique used to enhance the compatibility of time series data with large language model (LLM) inputs. This involves transforming raw time series values into a textual representation before feeding them into the LLM, allowing the model to better interpret and process the numerical information. Empirical results demonstrate that Pre-Alignment consistently yields superior performance compared to Post-Alignment strategies, which perform alignment of textual and time-series data within the LLM itself. This advantage is attributed to the fact that Pre-Alignment establishes a clearer, more readily understandable input format for the LLM, reducing the computational burden and improving the accuracy of subsequent analysis and forecasting tasks.
Post-Alignment represents an in-model refinement stage where textual prompts and processed time-series data are dynamically aligned within the large language model. This contrasts with pre-processing techniques by allowing the LLM to directly learn the relationships between the textual context and the numerical time-series values. Specifically, the LLM adjusts its internal representations to best correlate the provided text with the embedded time-series data during the forward pass, optimizing for tasks like forecasting or anomaly detection. This internal alignment is achieved through the model’s attention mechanisms and learned weights, enabling a more nuanced understanding of the data compared to solely relying on pre-aligned inputs.
Dynamic Routing: Orchestrating Information Flow for Efficiency
The Routing Mechanism within LLM4TSF governs the distribution of input data across various components of the forecasting model. Rather than a static allocation, this mechanism dynamically adjusts information flow based on the characteristics of the input data and the current state of the model. This dynamic allocation allows the model to prioritize relevant information pathways, improving both the accuracy and efficiency of time series forecasting. The system determines which components of the LLM should process specific parts of the input sequence, effectively creating a customized processing pipeline for each data point or batch.
The routing mechanism utilizes Gumbel-Softmax and the Straight-Through Estimator to address the challenges of discrete routing decisions within a neural network. Gumbel-Softmax introduces a differentiable approximation to categorical sampling, allowing gradients to flow through what would otherwise be a non-differentiable sampling process; this is achieved by adding Gumbel noise to logits before applying a softmax function. The Straight-Through Estimator further facilitates gradient propagation by treating the sampled discrete token as if it were the continuous input during backpropagation, effectively bypassing the non-differentiability of the argmax operation used in discrete routing. This combination enables end-to-end training of the routing component, optimizing routing preferences based on dataset characteristics and improving overall forecasting performance.
The implementation of a Transformer architecture as the foundational component of the dynamic routing mechanism yields improvements in both forecasting performance and model efficiency. This architecture facilitates the capture of complex temporal dependencies within time series data, enabling more accurate predictions. Critically, the routing preferences established within this system are not static; they adapt based on the specific characteristics of the input dataset, allowing the model to prioritize relevant information pathways. This adaptive behavior ensures that the model’s computational resources are allocated effectively, leading to optimized performance across diverse time series datasets and reducing the need for manual hyperparameter tuning for varying data patterns.
Synthetic Data: Establishing Ground Truth for Rigorous Validation
Synthetic Time Series data is generated to facilitate controlled experimentation in time series forecasting. This involves creating datasets with known characteristics, allowing researchers and developers to isolate and test specific aspects of forecasting models. Unlike real-world data, which is subject to unpredictable noise and confounding factors, synthetic data enables systematic manipulation of parameters such as data length, noise levels, and the presence of specific patterns. This capability is critical for evaluating model performance under defined conditions and for debugging issues related to model sensitivity or bias, providing a reproducible and reliable testing environment.
Synthetic time series datasets facilitate the controlled evaluation of model robustness by enabling systematic variation of core time series characteristics. Specifically, parameters governing the Trend component – linear, polynomial, or absent – can be precisely defined. Similarly, Seasonality is configurable through adjustable period lengths and amplitudes. Critically, Transition characteristics – the nature and frequency of shifts in these trends and seasonal patterns – are also manipulable, allowing for the generation of datasets with abrupt changes, gradual drifts, or complex, multi-faceted transitions. This granular control permits researchers to isolate the impact of each property on model performance, identifying vulnerabilities and quantifying resilience across diverse scenarios.
Establishing a performance baseline with synthetic time series data is critical for evaluating the LLM4TSF approach when applied to real-world datasets. This validation process allows for quantifiable assessment of model accuracy and reliability across varied temporal patterns. Specifically, LLM4TSF demonstrates enhanced efficacy in scenarios involving non-stationary data-datasets characterized by shifting trends, evolving seasonality, or complex transitions between states-where traditional time series forecasting methods often exhibit diminished performance. The synthetic data validation provides a controlled environment to isolate and measure LLM4TSF’s ability to accurately model and predict these challenging patterns, thereby increasing confidence in its robustness and generalizability.
Beyond Prediction: Generalization and the Future of Time Series Analysis
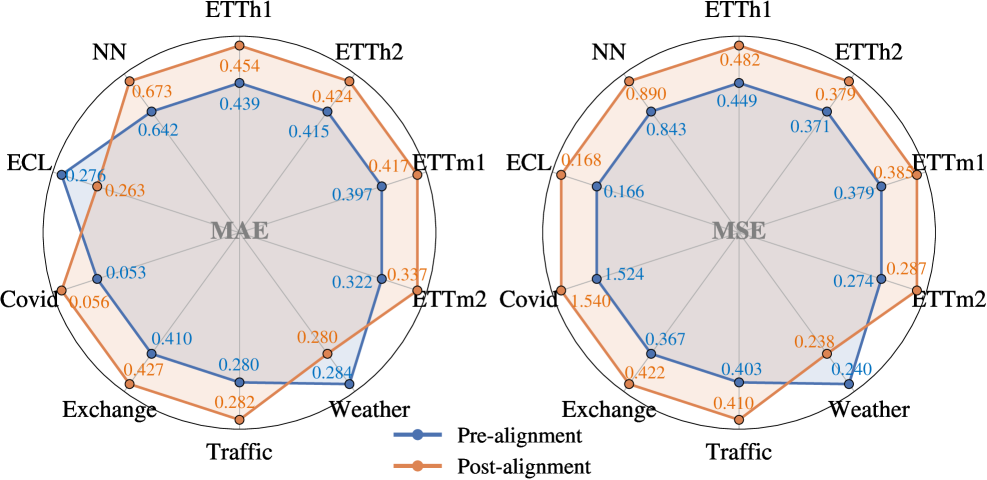
The capacity of Large Language Models for Time Series Forecasting (LLM4TSF) to accurately predict future outcomes is fundamentally strengthened through cross-dataset learning. This technique moves beyond the limitations of training on a single dataset, instead exposing the model to a variety of time series data exhibiting diverse patterns and characteristics. By generalizing across these datasets, LLM4TSF models develop a more robust understanding of underlying temporal dynamics, significantly improving their performance on unseen data. This approach consistently yields reductions in both Mean Squared Error (MSE) and Mean Absolute Error (MAE), demonstrating a measurable increase in predictive accuracy and reliability – a crucial step towards deploying scalable and trustworthy time series forecasting solutions across a wide spectrum of applications.
Recent advancements demonstrate that time series forecasting models achieve significantly improved robustness and accuracy when trained across multiple datasets. This cross-dataset learning strategy equips models to better handle variations in data distribution – the subtle, yet impactful differences in how data is collected and presented – and to recognize unforeseen patterns that might not be apparent within a single dataset. Empirical evidence consistently reveals that this approach leads to substantial reductions in both Mean Squared Error MSE and Mean Absolute Error MAE, key metrics for evaluating forecasting performance. The ability to generalize beyond the specific characteristics of a training dataset is paramount for real-world applications, suggesting that models exposed to diverse time series data are better positioned to deliver reliable predictions across a broader spectrum of scenarios.
The advancement of cross-dataset learning in time series forecasting isn’t merely an incremental improvement, but a foundational shift towards genuinely predictive analytics at scale. Previously constrained by the limitations of single datasets, models now demonstrate the capacity to generalize learned patterns to entirely new and unseen data streams – a crucial step for real-world applications. This broadened capability unlocks opportunities across diverse sectors, from optimizing energy grids and refining financial modeling to enhancing supply chain logistics and even predicting patient health trajectories. The ability to reliably forecast future trends, irrespective of specific dataset origins, promises more informed decision-making and proactive strategies, ultimately enabling organizations to anticipate change and operate with unprecedented efficiency and foresight.
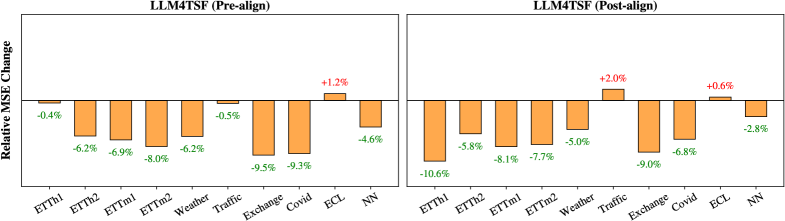
The study meticulously details how Large Language Models navigate the complexities of Time Series Forecasting, highlighting the necessity of pre-alignment and a robust routing mechanism to leverage their potential. This pursuit of demonstrable correctness echoes Blaise Pascal’s assertion: “The eloquence of the tongue consists not in its power to convince, but in its power to reveal.” Just as Pascal valued clarity in revealing truth, the research emphasizes a rigorous examination of when and how LLMs contribute genuine value, moving beyond mere empirical results to a deeper understanding of the underlying statistical properties and limitations. The pursuit isn’t simply about making forecasts, but revealing the mechanics of accurate prediction.
What Lies Ahead?
The exercise of applying Large Language Models to time series forecasting, as this work demonstrates, is not merely a question of achieving incremental gains. It is a fundamental test of whether statistical learning can be divorced from mathematical rigor. The observed benefits of cross-dataset learning, and the necessity of ‘pre-alignment,’ suggest the models are not discovering inherent patterns, but rather, are efficiently memorizing and interpolating existing ones. This is not inherently flawed, but it does necessitate a shift in evaluation. The field must move beyond superficial accuracy metrics and focus on demonstrable generalization to genuinely novel distributions.
A critical, largely unaddressed problem remains: the interpretability-or lack thereof-of these models. Forecasting, at its core, is about understanding causal relationships. LLMs, in their current form, offer little in the way of elucidating these mechanisms. The focus should not be on making the ‘black box’ more accurate, but on developing methods to extract provable, statistically sound insights from its predictions. Otherwise, the pursuit risks becoming an exercise in sophisticated curve-fitting, masquerading as scientific discovery.
Ultimately, the true value of LLMs in time series forecasting may not lie in their predictive power alone, but in their ability to serve as a catalyst for a more principled approach to statistical modeling. A return to first principles – a focus on provability, interpretability, and generalization – is not merely desirable; it is essential if this field is to progress beyond empirical observation.
Original article: https://arxiv.org/pdf/2602.14744.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Persona PSP soundtrack will be available on streaming services from April 18
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- Gold Rate Forecast
- Raptors vs. Cavaliers Game 2 Results According to NBA 2K26
- MLB The Show 26 RTTS Guide – All Perks in Road To The Show
2026-02-18 06:54