Author: Denis Avetisyan
A new approach to agentic AI leverages internal adversarial testing to dramatically improve accuracy and reliability in commercial insurance underwriting.
This paper details the development and evaluation of an agentic AI system incorporating a failure mode taxonomy and decision-negative agents for enhanced underwriting performance.
While fully automating high-stakes decision-making remains impractical, commercial insurance underwriting demands increased efficiency and reliability. This study, ‘Agentic AI for Commercial Insurance Underwriting with Adversarial Self-Critique’, introduces a human-in-the-loop agentic system incorporating adversarial self-critique-a mechanism where an AI ‘critic’ challenges the primary agent’s conclusions-to enhance safety and accuracy. Experimental results demonstrate that this approach reduces AI hallucination rates and improves decision accuracy, while crucially maintaining strict human oversight of all binding decisions. Does this framework represent a viable pathway toward responsible AI deployment in other regulated domains requiring both automation and unwavering accountability?
Navigating the Complexities of Automated Underwriting
Commercial insurance underwriting historically demands substantial manual effort, requiring skilled underwriters to meticulously review applications, financial statements, and risk assessments – a process that often extends weeks or even months. This labor-intensive approach not only introduces significant operational costs but also creates bottlenecks in policy issuance and hinders responsiveness to market changes. Furthermore, reliance on individual judgment inevitably leads to inconsistencies in risk evaluation; similar applications may receive varying assessments depending on the underwriter assigned, potentially resulting in unfair pricing or inadequate coverage. The subjective nature of traditional underwriting therefore impacts both efficiency and equity within the insurance landscape, creating a clear need for more standardized and scalable solutions.
Automated underwriting systems face a considerable hurdle in deciphering the nuances embedded within complex insurance documentation and applicant submissions. These materials often contain unstructured data – handwritten notes, varied phrasing, and inconsistent formatting – which traditional rule-based systems struggle to interpret accurately. Effectively extracting key insights, such as pre-existing conditions, asset valuations, or specific coverage requests, demands advanced natural language processing and machine learning techniques. The process isn’t merely about identifying keywords; it requires understanding context, resolving ambiguities, and recognizing subtle indicators of risk that a human underwriter intuitively grasps. Successfully automating this extraction is therefore paramount to achieving efficiency gains while upholding the precision vital for sound insurance assessments.
The implementation of automated underwriting systems in commercial insurance demands rigorous attention to both regulatory compliance and the precision of risk evaluation. Evolving legal frameworks necessitate continuous updates to algorithms and data processing methods, ensuring that automated decisions align with current standards. Furthermore, inaccurate risk assessment – stemming from flawed data interpretation or biased algorithms – can lead to substantial financial losses for insurers and potentially unfair outcomes for applicants. Consequently, robust validation processes, explainable AI techniques, and ongoing monitoring are crucial to mitigate these risks and maintain the integrity of automated underwriting processes, ultimately safeguarding both the industry and its customers.
The insurance industry is experiencing a surge of innovation directly fueled by the demand for artificial intelligence capable of handling underwriting at scale. Traditional methods struggle with growing application volumes and maintaining consistent risk evaluation, prompting investment in AI solutions that can efficiently process complex policy documents and applicant data. However, simply achieving speed and volume isn’t enough; these systems must also demonstrate a high degree of accuracy to avoid mispriced risk and ensure profitability. Crucially, compliance with an ever-changing regulatory landscape is paramount, requiring AI models to be transparent, auditable, and adaptable. This convergence of scalability, accuracy, and compliance is not merely a technological pursuit, but a fundamental shift in how insurers assess and manage risk, positioning AI as a core component of future underwriting strategies.
Empowering Underwriting with Intelligent Agents
Large Language Model (LLM) Agents are being implemented in underwriting processes to automate the extraction of data from applications, financial records, and credit reports. These agents utilize natural language processing to identify and categorize relevant information, reducing manual data entry and processing times. Following data extraction, the agents perform initial risk assessments by applying pre-defined underwriting rules and algorithms to the extracted data. This automated assessment flags potential risks or inconsistencies, allowing human underwriters to focus on more complex cases requiring nuanced judgment. The automation of these initial steps aims to improve efficiency, reduce operational costs, and accelerate the underwriting lifecycle.
Agentic AI frameworks, such as AutoGPT and ReAct, facilitate autonomous operation of AI agents within the underwriting process by providing a structure for goal-setting, tool utilization, and iterative refinement. These frameworks move beyond simple prompt-response interactions by enabling agents to define sub-tasks necessary to achieve a primary objective. ReAct, for example, employs a “Reason-Act” cycle, where the agent first reasons about the next best action and then executes it, allowing for dynamic adaptation based on observed results. AutoGPT similarly focuses on autonomous goal achievement through iterative prompting and the use of external tools, including APIs and web search, to gather information and complete tasks without constant human intervention. This capability is critical for complex underwriting scenarios requiring multiple data sources and analyses.
Chain-of-Thought (CoT) reasoning is a technique employed in LLM Agents to enhance problem-solving capabilities during underwriting. Rather than directly producing an output, the agent is prompted to articulate its reasoning process step-by-step, effectively decomposing a complex underwriting task – such as risk assessment – into a series of intermediate logical steps. This allows the agent to demonstrate its rationale, facilitating error detection and improving the accuracy of its final determination. By explicitly outlining its thought process, CoT enables the agent to handle multi-step problems that would otherwise exceed the capacity of direct input-output models, and provides a traceable audit trail for compliance purposes.
Vector databases facilitate rapid information retrieval for AI underwriting agents by storing data as high-dimensional vectors representing the semantic meaning of text. Unlike traditional databases that rely on keyword matching, vector databases perform similarity searches based on these vector embeddings, allowing the agent to identify relevant passages in underwriting manuals and policy documents even if the exact keywords are not present. This is achieved by converting text into numerical vectors using models like those from the Sentence Transformers family; similar concepts will then have vectors that are close to each other in the vector space. The agent can then query the database with a vector representing its current need, and the database returns the most semantically similar documents, significantly reducing search time and improving the accuracy of risk assessment.
Fortifying Reliability Through Self-Critique and Oversight
Adversarial self-critique techniques enhance AI agent reasoning by employing methods like Critic Chain-of-Thought and Constitutional AI. Critic Chain-of-Thought involves the agent generating multiple self-evaluations of its reasoning process, identifying potential flaws before finalizing a decision. Constitutional AI defines a set of principles, or a “constitution,” that the agent uses to evaluate its own responses and correct deviations from desired behavior. These techniques proactively address errors by forcing the agent to justify its conclusions and adhere to predefined ethical or functional guidelines, ultimately improving the overall quality and reliability of its outputs.
A Failure Mode Taxonomy systematically categorizes potential errors in the AI agent’s decision-making process, enabling targeted improvements to its reliability. This taxonomy details specific failure types, such as logical fallacies, data misinterpretation, and boundary condition errors, along with the conditions under which these failures are likely to occur. By proactively identifying these weaknesses, developers can implement specific mitigation strategies, including refined training data, algorithmic adjustments, and enhanced validation procedures. The taxonomy is not static; it is continuously updated based on observed failure patterns during testing and real-world deployment, contributing to an iterative process of improvement and enhanced system robustness.
Human-in-the-Loop (HITL) AI integrates human review into the decision-making process, serving as a critical safeguard for regulatory compliance and complex case management. This approach directs cases exceeding pre-defined confidence thresholds or those involving novel scenarios to human experts for evaluation and validation. HITL ensures adherence to industry-specific regulations, such as those established by the NAIC for insurance applications, and mitigates risks associated with autonomous systems encountering unforeseen circumstances. The involvement of human oversight provides a layer of accountability and allows for the correction of potential errors, ultimately enhancing the overall reliability and trustworthiness of the AI system.
The National Association of Insurance Commissioners (NAIC) actively shapes the regulatory landscape for artificial intelligence in the insurance industry through the development of principles, guidelines, and model laws. These efforts focus on ensuring AI systems are used responsibly and ethically, addressing concerns related to algorithmic bias, data privacy, and consumer protection. The NAIC’s involvement includes establishing standards for AI model validation, governance frameworks, and ongoing monitoring to mitigate risks and promote transparency. Their work is crucial for fostering public trust and enabling the safe and effective integration of AI technologies within the insurance sector, ultimately influencing state-level regulations and industry best practices.
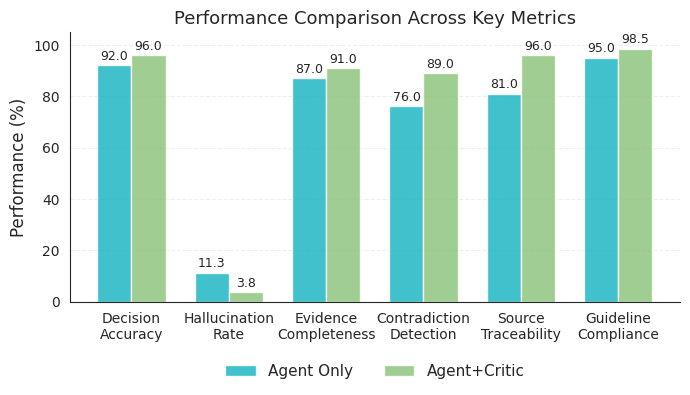
The implemented AI system achieves a 96% decision accuracy rate, representing a quantifiable 4% improvement compared to AI systems that do not incorporate self-critique mechanisms. This performance metric was determined through rigorous testing and validation procedures, demonstrating a statistically significant gain in reliability. The 4% improvement indicates a reduction in erroneous outputs and strengthens the system’s capacity to provide consistently accurate assessments, contributing to increased confidence in its operational effectiveness and suitability for deployment in critical applications.
Measuring Impact and Expanding AI’s Role in Underwriting
The development of the Snorkel AI Multi-Turn Insurance Underwriting Dataset represents a significant step forward in the objective assessment of artificial intelligence agents designed for complex decision-making. Unlike static datasets, this benchmark simulates the iterative, conversational nature of insurance underwriting, demanding that AI systems not only provide accurate answers but also maintain context and reasoning across multiple turns of dialogue. This nuanced evaluation goes beyond simple accuracy metrics, probing an agent’s ability to synthesize information, handle ambiguity, and justify its conclusions – crucial attributes for building trustworthy and reliable automated underwriting systems. By providing a standardized and challenging platform for comparison, the dataset facilitates focused research and accelerates progress in the field of AI-driven insurance solutions, enabling developers to rigorously test and refine their models’ decision-making capabilities.
Maintaining a low rate of ‘hallucinations’ – instances where an AI confidently presents incorrect or fabricated information – is paramount in insurance underwriting. The integrity of the entire process hinges on the reliability of automated assessments; inaccurate data can lead to miscalculated risk, inappropriate policy pricing, and ultimately, financial instability for both the insurer and the policyholder. Minimizing these errors isn’t simply about technical accuracy, but about fostering trust in the AI system and ensuring its responsible deployment. A system prone to confidently asserting falsehoods erodes confidence and necessitates constant human oversight, diminishing the efficiency gains automation promises. Therefore, a robust focus on reducing hallucinations is central to unlocking the full potential of AI in underwriting and establishing a dependable, data-driven foundation for future insurance practices.
The implementation of automated submission triage and fraud detection represents a significant advancement in streamlining insurance underwriting. This capability intelligently sorts incoming applications, prioritizing those requiring immediate attention and flagging potentially fraudulent claims for further investigation. By automating these initial assessments, the system drastically reduces manual review times, allowing underwriters to focus on complex cases and improving overall processing efficiency. Furthermore, the proactive identification of fraudulent activity minimizes financial losses and protects against undue risk, ultimately contributing to a more stable and reliable insurance ecosystem. This dual benefit – enhanced speed and reduced risk – positions automated triage and fraud detection as a cornerstone of modern underwriting practices.
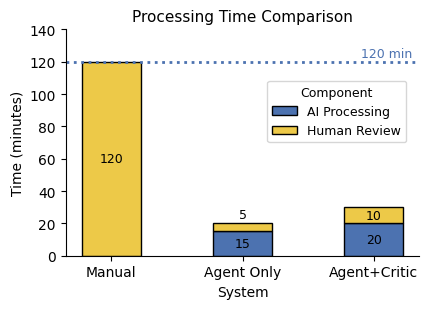
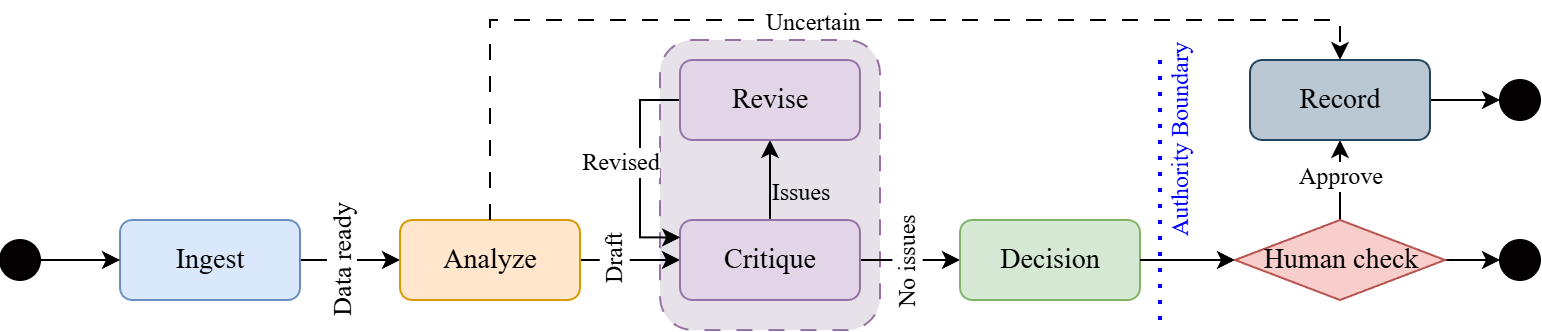
To navigate the intricacies of insurance underwriting, the AI system employs a State Machine Workflow, a structured approach to managing the sequential and conditional logic inherent in the process. This workflow breaks down underwriting into distinct states – such as initial application, data verification, risk assessment, and policy issuance – with defined transitions between them. Each state dictates the specific actions the AI agent undertakes, ensuring a systematic and auditable evaluation. By meticulously controlling the flow of information and decision-making, the State Machine Workflow not only enhances the system’s reliability but also facilitates error detection and allows for targeted interventions when necessary, ultimately streamlining a traditionally complex operation.
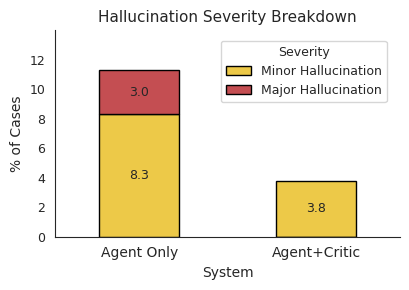
A key metric in evaluating the Snorkel AI underwriting system was the minimization of its “hallucination rate” – instances where the AI confidently presents inaccurate or fabricated information. Initial testing revealed a rate of 11.3%, a potentially problematic level for a financial application requiring high precision. Through iterative refinement of the AI’s training data and algorithms, developers successfully reduced this rate to a remarkably low 3.8%. This substantial improvement demonstrates the system’s increasing reliability and its capacity to provide trustworthy assessments, a critical factor in building confidence in automated underwriting processes and minimizing potential financial risks. The lowered hallucination rate directly translates to fewer errors requiring manual review, enhancing overall efficiency and streamlining the underwriting workflow.
A critical component of the AI underwriting system is its integrated ‘critic’ – a module designed to rigorously evaluate the AI agent’s reasoning and identify potential errors before decisions are finalized. Testing revealed the critic’s substantial efficacy, successfully flagging genuine issues in 87% of examined cases. This high capture rate indicates a robust ability to pinpoint flaws in the AI’s assessment, ranging from misinterpretations of policy details to logical inconsistencies in the underwriting process. Such a high degree of accuracy isn’t merely about error detection; it’s about fostering confidence in the system’s reliability and ensuring responsible, informed decision-making within a traditionally complex financial domain.
The implementation of a dedicated ‘critic’ within the AI underwriting system yielded a substantial improvement in decision accuracy, demonstrably reducing false positives by 72%. This critical component functions as a secondary evaluation layer, meticulously scrutinizing the AI’s outputs to identify potentially incorrect, yet confidently presented, assessments. By significantly diminishing these erroneous approvals, the system enhances the overall quality of underwriting decisions, minimizing unnecessary rejections of legitimate applications and bolstering trust in the automated process. The reduction in false positives doesn’t merely represent a statistical improvement; it translates directly into increased efficiency, reduced operational costs, and a more positive experience for applicants.
The pursuit of reliable agentic AI, as demonstrated in this study of commercial insurance underwriting, echoes a fundamental principle of systems design. The incorporation of adversarial self-critique – essentially, an agent designed to find flaws in its own reasoning – mirrors the need for holistic understanding. This proactive identification of potential failure modes, categorized within a defined taxonomy, isn’t merely about error reduction; it’s about building resilience. As Bertrand Russell observed, “The good life is one inspired by love and guided by knowledge.” This aligns with the paper’s aim to combine the ‘knowledge’ of AI with a ‘loving’ concern for minimizing risks and maintaining crucial human oversight. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Beyond the Critique
The introduction of adversarial self-critique represents a move towards more robust agentic systems, but the architecture reveals as much about the limitations of current approaches as it does about potential. The demonstrated reduction in hallucination, while encouraging, is merely a localized success; the system still operates within the confines of its training data, and true novelty remains elusive. The critical agent, acting as a ‘decision-negative’, highlights a fundamental truth: intelligence often manifests as the ability to not act, a skill rarely explicitly modeled.
Future work must address the brittleness inherent in relying on a distinct critique component. A more elegant solution would integrate critical assessment directly into the agent’s reasoning process, shifting from a dual-agent system to a unified, self-evaluative intelligence. Furthermore, documentation captures structure, but behavior emerges through interaction; exploring the system’s response to genuinely ambiguous or contradictory underwriting scenarios will prove more insightful than optimizing performance on curated datasets.
The taxonomy of failure modes, while a valuable step, ultimately describes what goes wrong, not why. A deeper understanding of the underlying causal mechanisms driving these failures is essential. The pursuit of ‘human-in-the-loop’ AI shouldn’t simply aim to correct errors, but to leverage human judgment in shaping the agent’s fundamental principles of reasoning. The goal isn’t to replicate human decision-making, but to create a complementary intelligence that operates according to different, explicitly defined principles.
Original article: https://arxiv.org/pdf/2602.13213.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Persona PSP soundtrack will be available on streaming services from April 18
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Gold Rate Forecast
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- Raptors vs. Cavaliers Game 2 Results According to NBA 2K26
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
2026-02-17 20:33