Author: Denis Avetisyan
A new framework clarifies why 5G radio access networks might fail, enabling proactive maintenance and improved reliability.
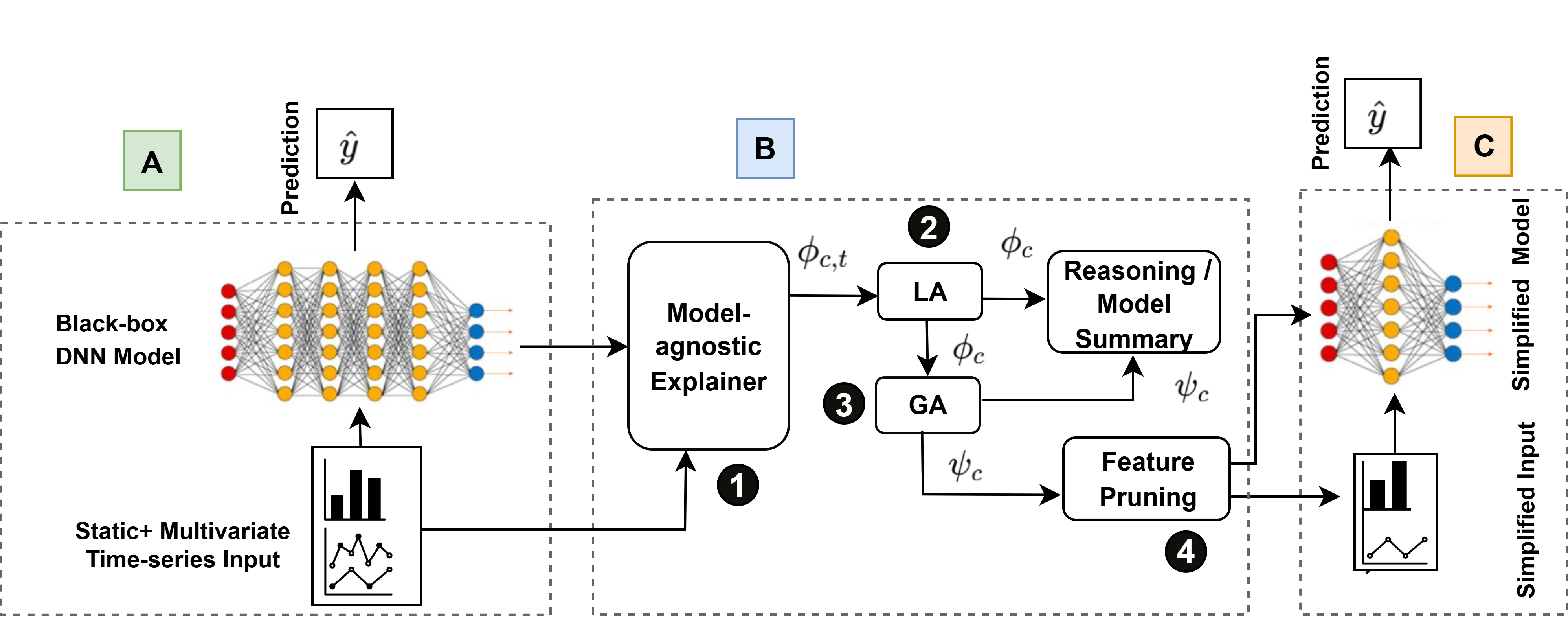
Researchers introduce Prometheus, an explainable AI system that simplifies failure prediction models and pinpoints critical features for 5G RAN performance.
Despite the increasing complexity of neural networks for predicting critical failures in 5G radio access networks, their ‘black box’ nature hinders operational deployment and trust. This work introduces ‘An Explainable Failure Prediction Framework for Neural Networks in Radio Access Networks’-Prometheus-which simplifies these models by identifying and pruning irrelevant features, enhancing both interpretability and predictive accuracy. Through the application of this framework to real-world datasets, we demonstrate that weather data contributes minimally to failure prediction, enabling the creation of leaner models with a 50% reduction in parameters and improved F1 scores. Can this approach to explainable AI unlock further optimization and resilience in future wireless networks?
Understanding Network Fragility in the 5G Era
Modern 5G networks have rapidly become essential to daily life, underpinning critical services from emergency communications and financial transactions to autonomous vehicles and industrial automation. However, the very nature of wireless communication renders these networks inherently vulnerable to Radio Link Failures (RLF), sudden disruptions in the connection between a user device and the network. These failures, triggered by factors like signal interference, network congestion, or even atmospheric conditions, can lead to dropped calls, lost data, and, in critical applications, potentially dangerous consequences. The increasing density of mobile devices and the growing demand for seamless connectivity are exacerbating the risk of RLF, making it paramount to develop strategies for both predicting and mitigating these disruptions to ensure the continued reliability of this vital infrastructure.
Conventional Radio Link Failure (RLF) prediction techniques often fall short in modern networks due to an oversimplified view of link stability. These methods typically rely on static thresholds or basic statistical models, failing to capture the dynamic and interconnected factors that contribute to signal degradation. A single RLF event isn’t usually caused by one isolated issue, but rather a complex interplay of user mobility, network load, interference from neighboring cells, and even environmental conditions. Consequently, predictions based on limited data or simplistic algorithms generate a high number of false alarms or, more critically, fail to anticipate genuine disruptions, impacting service quality and potentially leading to dropped calls or data sessions. The need for more nuanced approaches – those incorporating machine learning and real-time data analysis – is therefore paramount to proactively mitigate RLF events and ensure consistent connectivity.
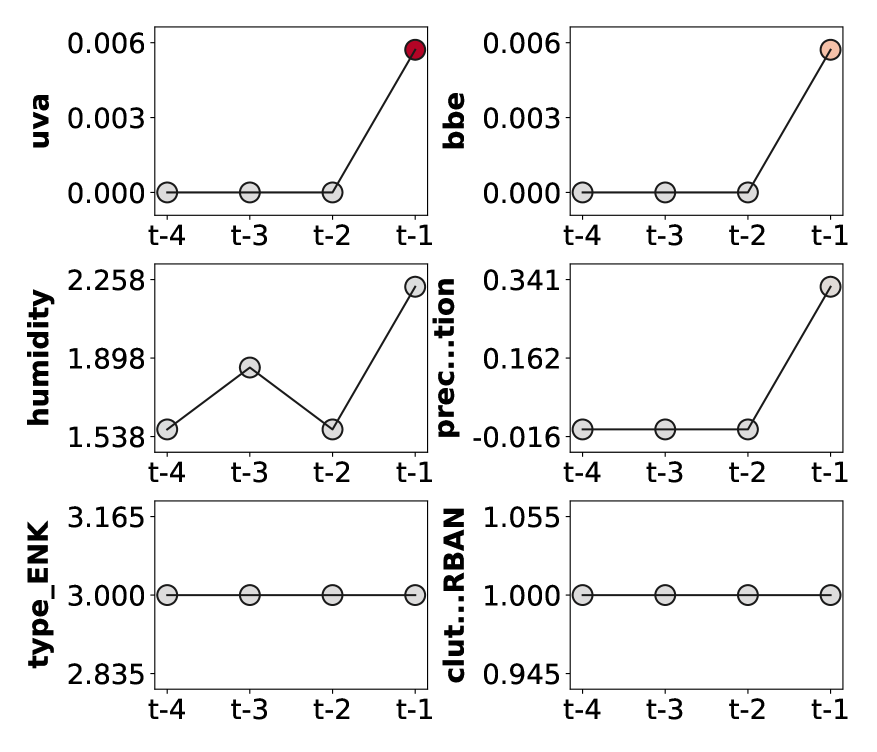
Predicting radio link failures (RLF) in modern 5G networks demands a sophisticated analysis extending beyond simple signal strength indicators. Robust RLF prediction necessitates the processing of multifaceted time series data – encompassing metrics like signal-to-noise ratio, interference levels, and handover performance – alongside the incorporation of external contextual information. Critically, atmospheric conditions significantly influence radio wave propagation; therefore, integrating real-time and forecasted weather data, including precipitation, temperature, and humidity, substantially improves prediction accuracy. This holistic approach allows for a more nuanced understanding of link stability, enabling proactive network adjustments and minimizing service disruptions by anticipating potential failures before they impact users.
Introducing Prometheus: An XAI-Driven Prediction Framework
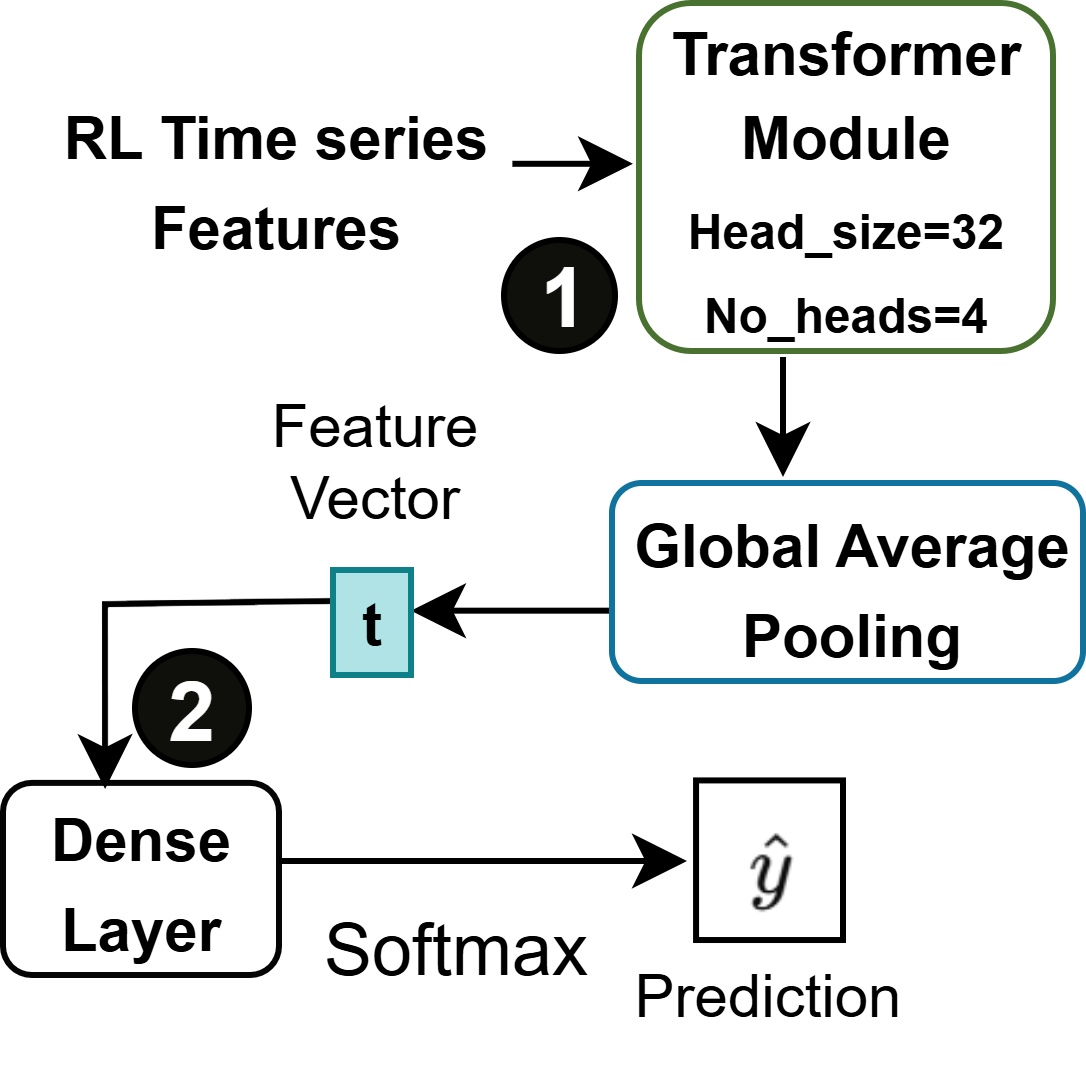
Prometheus is a newly developed framework designed for Reward-Likelihood Forecasting (RLF) prediction. It employs a combination of advanced modeling techniques – including, but not limited to, gradient boosting and neural network architectures – to achieve increased predictive accuracy and a demonstrable reduction in false positive rates. This framework distinguishes itself through its capacity to reliably forecast reward likelihoods, which is crucial for applications requiring precise and dependable predictions. Performance metrics, as evaluated in initial deployments, indicate significant improvements over existing baseline models, particularly in complex environments.
Feature pruning within the Prometheus framework systematically reduces model complexity by identifying and removing statistically insignificant input features. This optimization process decreases computational load, leading to faster prediction times essential for real-time applications. The technique assesses feature importance based on their contribution to the overall model accuracy; features demonstrating minimal impact are then excluded. This not only improves processing speed but also mitigates overfitting, enhancing generalization performance on unseen data. The resulting streamlined model maintains a high degree of predictive power while requiring fewer resources for deployment and operation.
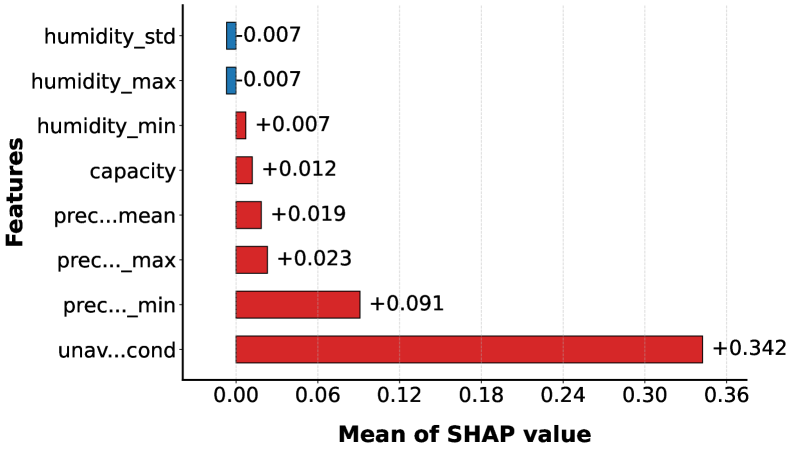
Prometheus employs both Local Aggregation and Global Aggregation techniques to determine the contribution of individual features to prediction outcomes. Local Aggregation assesses feature importance within specific data clusters, while Global Aggregation provides an overall importance ranking across the entire dataset. Quantitative results demonstrate a 20% improvement in the F1-score for urban deployments and a 4% improvement for rural deployments when compared to baseline models. This performance gain is directly attributable to the framework’s ability to accurately identify and prioritize the most influential predictive features, thereby reducing prediction errors and enhancing overall system accuracy.
Unveiling Feature Importance Through Explainable AI
Prometheus utilizes Explainable AI (XAI) techniques, specifically Saliency Maps, to provide visual representations of feature contributions to model predictions. These maps identify which input features most strongly influence the model’s output, enabling users to pinpoint potential indicators of Reward-based Learning Failure (RLF). By visualizing these contributions, Prometheus allows for targeted investigation of model behavior and facilitates the identification of features driving potentially undesirable outcomes. The system supports analysis across various feature sets to determine those with the highest predictive power, informing subsequent model refinement and validation efforts.
Insertion and deletion tests are quantitative methods used to assess feature importance by observing the change in model prediction when features are systematically altered. In a deletion test, the value of a single feature is masked or removed, and the resulting change in the model’s output is recorded; a significant change indicates high importance. Conversely, an insertion test begins with a baseline input – often all features set to a neutral value – and iteratively adds each feature, measuring the impact on the prediction. These tests provide a robust, model-agnostic approach to validating feature contributions and identifying potential biases or unexpected dependencies within the model’s decision-making process, offering a more granular understanding than simple correlation analysis.
Prometheus’s feature analysis capabilities, utilizing techniques like Saliency Maps, Insertion Tests, and Deletion Tests, have demonstrated significant performance with reduced feature sets. In rural deployment scenarios, the model achieved a 96% F1-score when utilizing only the two most important features identified through these analyses. While performance is comparatively lower in urban deployments, a 67% F1-score was still achieved using the same two-feature approach. These results indicate the effectiveness of Prometheus’s feature selection process in identifying key indicators and suggest the potential for model simplification without substantial performance degradation, particularly in rural environments.
Lightweight Models for Scalable Network Intelligence
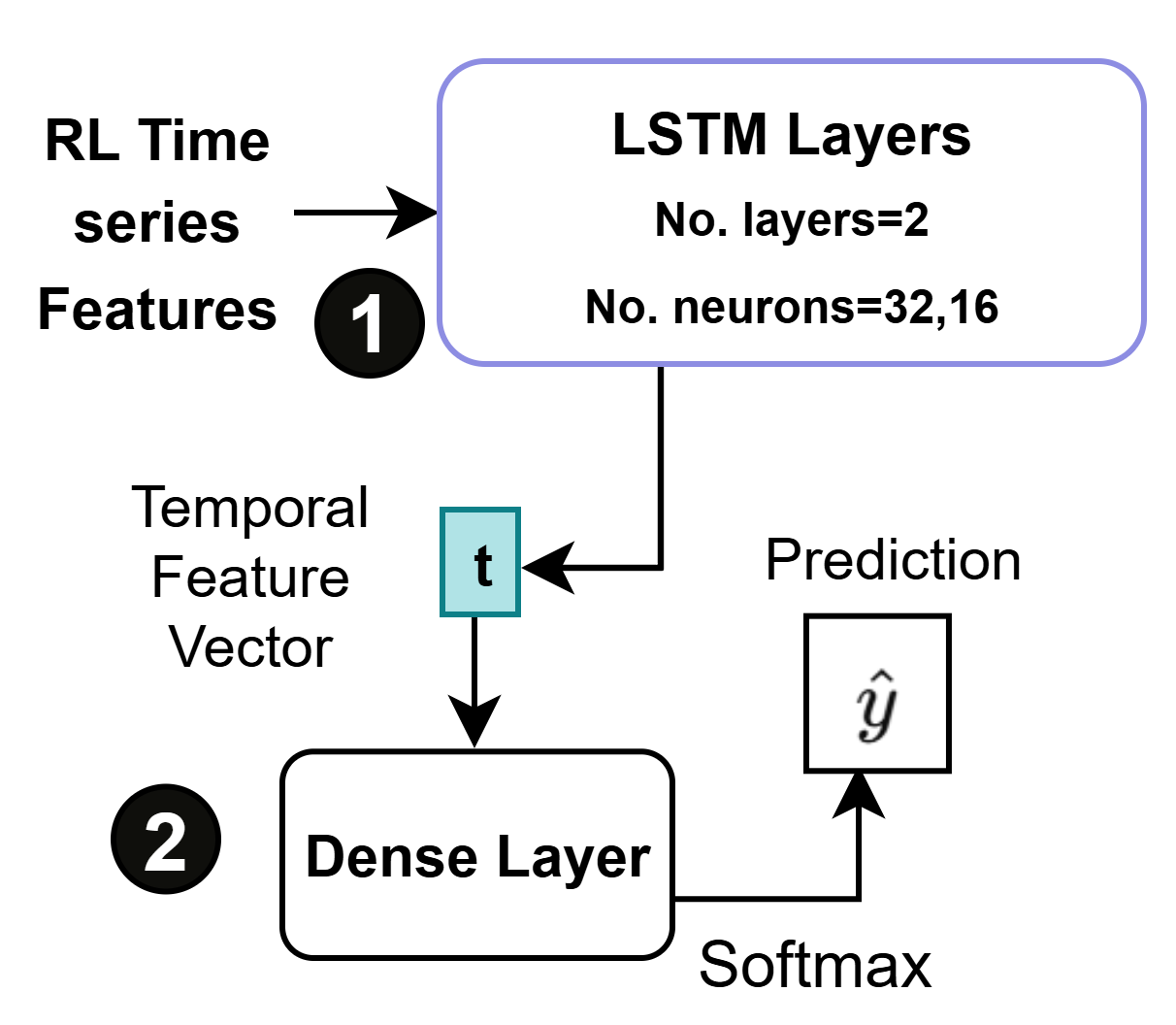
Prometheus incorporates both Lightweight Transformer and Lightweight LSTM models to address the computational challenges of network intelligence. These models are created through a two-pronged approach: architectural refinement, which involves simplifying the model structure by reducing layers or the size of internal representations, and feature pruning, a process of removing statistically insignificant connections or input features. This combined strategy allows Prometheus to deploy complex models in resource-constrained environments without substantial performance degradation, facilitating scalable network monitoring and analysis.
Streamlined model architectures are critical for scalable network intelligence due to the inherent computational limitations of deploying predictive models across extensive network infrastructure. Reducing model complexity directly lowers the processing requirements for both training and inference, enabling real-time predictions on resource-constrained devices and minimizing latency. Maintaining predictive accuracy during this simplification process is paramount; Prometheus achieves this through techniques like architectural refinement and feature pruning, ensuring that performance degradation is minimized while significantly reducing computational load. This balance between accuracy and efficiency is essential for practical deployment in large-scale network environments where maintaining network performance is a primary concern.
Prometheus facilitates real-time Reinforcement Learning from Human Feedback (RLHF) prediction within network deployments through the implementation of computationally efficient models. Specifically, simplification techniques applied to Long Short-Term Memory (LSTM) based models have resulted in a 92% reduction in the total number of model parameters. This parameter reduction directly translates to lower computational costs and reduced memory footprint, enabling the execution of complex predictive tasks without negatively impacting overall network performance or introducing latency. The resulting models maintain a comparable level of prediction accuracy to their larger counterparts, offering a practical solution for scalable network intelligence.
Towards a Future of Proactive Network Resilience
Prometheus establishes a resilient network foundation by actively minimizing Request Loss Frequency (RLF), a critical metric for user experience. This framework doesn’t simply react to failures; it anticipates and mitigates potential disruptions through continuous monitoring and analysis of network performance indicators. By correlating diverse data points – including latency, throughput, and error rates – Prometheus pinpoints the root causes of performance degradation before they escalate into widespread outages. The result is a demonstrable improvement in Quality of Service, evidenced by faster response times and reduced buffering. Ultimately, this proactive approach transcends traditional network management, fostering a more dependable and consistently available infrastructure that minimizes downtime and maximizes user satisfaction.
A key strength of the Prometheus framework lies in its readily interpretable data, affording network operators an unprecedented ability to anticipate and resolve issues before user experience is affected. Unlike traditional reactive systems that diagnose problems after they manifest, Prometheus delivers clear, actionable insights into network behavior, highlighting potential vulnerabilities and performance bottlenecks in real-time. This interpretability stems from the framework’s design, which emphasizes transparent metrics and customizable alerts, allowing operators to quickly pinpoint the root cause of emerging problems – such as bandwidth saturation or latency spikes – and implement corrective measures. Consequently, network downtime is minimized, service quality is sustained, and a more robust, user-centric network infrastructure is realized, shifting the paradigm from damage control to preventative care.
The transition from reactive network troubleshooting to proactive management, facilitated by systems like Prometheus, represents a fundamental shift in network operations. Traditionally, issues were addressed after user impact, involving diagnosis and repair cycles that inherently introduce downtime and degrade service quality. Prometheus, however, enables continuous monitoring and analysis of network performance indicators, allowing operators to identify and mitigate potential problems before they escalate into disruptions. This preemptive approach minimizes recovery time, optimizes resource allocation, and dramatically improves the overall user experience. The result is a network that isn’t simply responsive to failures, but actively anticipates and prevents them, unlocking substantial gains in both efficiency and resilience and paving the way for truly self-healing infrastructure.
The pursuit of predictive accuracy, as demonstrated by Prometheus, often leads to unnecessarily complex models. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This sentiment resonates with the framework’s emphasis on model simplification. The system doesn’t merely predict failures in the 5G RAN; it prioritizes explainability by distilling the most impactful features – a pragmatic approach acknowledging that a slightly less accurate, yet understandable, model is far more valuable than a black box. Architecture, after all, is the art of choosing what to sacrifice, and Prometheus sacrifices marginal gains for the clarity of insight.
The Road Ahead
The pursuit of explainable artificial intelligence in critical infrastructure, as exemplified by frameworks like Prometheus, inevitably reveals a fundamental tension. Each added layer of interpretability, each simplification intended to illuminate decision-making, introduces a new dependency – a hidden cost of freedom. The framework elegantly addresses feature importance within the constraints of time series analysis, yet the inherent complexity of radio access networks suggests this is merely a localized optimization. True systemic understanding demands a shift from feature-centric explanations to a holistic view of network behavior – recognizing that prediction, ultimately, is about anticipating the emergent properties of a complex, adaptive system.
Current approaches often treat failure prediction as a classification problem. However, network health is fundamentally a dynamic state, susceptible to cascading effects and subtle shifts in operational regimes. Future work should explore methods that model not just the probability of failure, but the propagation of risk through the network – incorporating concepts from control theory and dynamical systems.
The simplification of models, while laudable, carries its own risk. Stripping away nuance in the name of clarity risks obscuring the subtle indicators of impending instability. The challenge, then, is not simply to find the most important features, but to understand how those features interact – and to accept that a truly complete explanation may be inherently unachievable, or at least, computationally intractable.
Original article: https://arxiv.org/pdf/2602.13231.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Persona PSP soundtrack will be available on streaming services from April 18
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Gold Rate Forecast
- “67 challenge” goes viral as streamers try to beat record for most 67s in 20 seconds
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
2026-02-17 18:56