Author: Denis Avetisyan
A new framework offers a robust method for separating genuine knowledge gaps from inherent data noise in deep learning models.
Credal Concept Bottleneck Models structurally separate epistemic and aleatoric uncertainty using disjoint parameterization and training objectives.
Accurately decomposing predictive uncertainty into distinct epistemic and aleatoric components remains a significant challenge, as existing methods often conflate these sources due to correlated estimates. This paper introduces ‘Credal Concept Bottleneck Models: Structural Separation of Epistemic and Aleatoric Uncertainty’, a novel deep learning framework that achieves clear separation by representing uncertainty as a credal set and employing disjoint parameterization with dedicated training objectives. Our approach demonstrably reduces correlation between uncertainty types-by over an order of magnitude on multi-annotator benchmarks-and aligns epistemic uncertainty with prediction error and aleatoric uncertainty with ground-truth ambiguity. Could this framework unlock more reliable decision-making in scenarios demanding nuanced understanding of model confidence and inherent data ambiguity?
The Illusion of Prediction: Recognizing the Limits of Knowing
Contemporary natural language processing models demonstrate remarkable proficiency in predicting text, yet a significant limitation persists: these systems often fail to convey the certainty associated with their predictions. While a model might generate an answer, it typically doesn’t indicate how trustworthy that answer is, creating a critical gap between raw output and reliable decision-making. This lack of calibrated confidence hinders practical applications, as users are left unable to discern between highly probable and potentially spurious results. Consequently, even highly accurate models can lead to flawed conclusions if their outputs are treated as definitive truths, particularly when dealing with nuanced language or data outside their training scope. Addressing this deficiency is paramount for deploying NLP systems responsibly and ensuring their outputs are genuinely useful in real-world scenarios.
A significant challenge arises when natural language processing models face inputs that differ from their training data, or when presented with inherently ambiguous queries. In these scenarios, models frequently exhibit overconfidence, assigning high probabilities to incorrect outputs without any indication of doubt. This isn’t merely an academic concern; the consequences can be severe in applications like medical diagnosis or financial forecasting, where acting on a confidently incorrect prediction can lead to substantial harm. The issue stems from a model’s inability to recognize the limits of its knowledge; it effectively ‘hallucinates’ certainty where genuine understanding is lacking, highlighting the critical need for mechanisms that reliably signal when a prediction is untrustworthy.
The responsible deployment of artificial intelligence hinges on a system’s ability to not only make predictions, but also to accurately convey the certainty behind them. Without robust uncertainty quantification, AI can exhibit overconfidence when faced with unfamiliar data or ambiguous inputs, potentially leading to critical errors in applications like medical diagnosis, autonomous driving, or financial modeling. This isn’t simply about acknowledging the possibility of being wrong; it’s about providing a quantifiable measure of risk, allowing decision-makers to assess the potential consequences of acting on a given prediction. By understanding the limits of an AI’s knowledge, stakeholders can implement appropriate safeguards, seek human oversight when necessary, and ultimately mitigate the harms associated with flawed or unreliable automated systems. Accurate uncertainty quantification, therefore, moves AI beyond a predictive tool and toward a trustworthy partner in complex real-world scenarios.
Deconstructing Uncertainty: A Framework for Robust Belief Management
CredalCBM is a novel framework designed to explicitly separate uncertainty into two distinct components: epistemic and aleatoric. Epistemic uncertainty arises from a lack of knowledge and can, theoretically, be reduced with increased training data. Aleatoric uncertainty, conversely, is inherent to the data itself, representing noise or ambiguity that persists even with infinite data. This decomposition is achieved through a specific architectural design, enabling the model to independently quantify each type of uncertainty and providing a more granular understanding of its own confidence. This separation is crucial for robust AI systems, allowing for targeted data collection to address knowledge gaps and a realistic assessment of limitations when dealing with intrinsically noisy data.
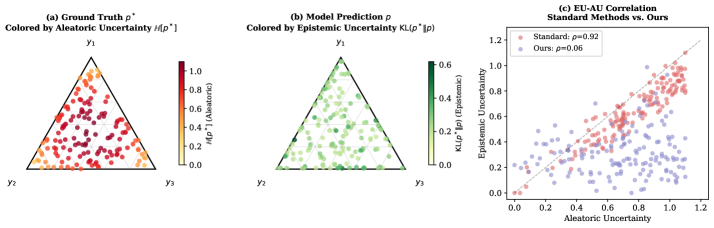
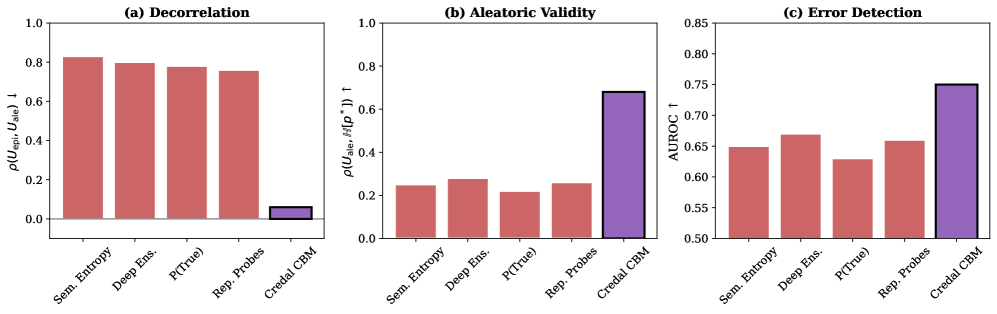
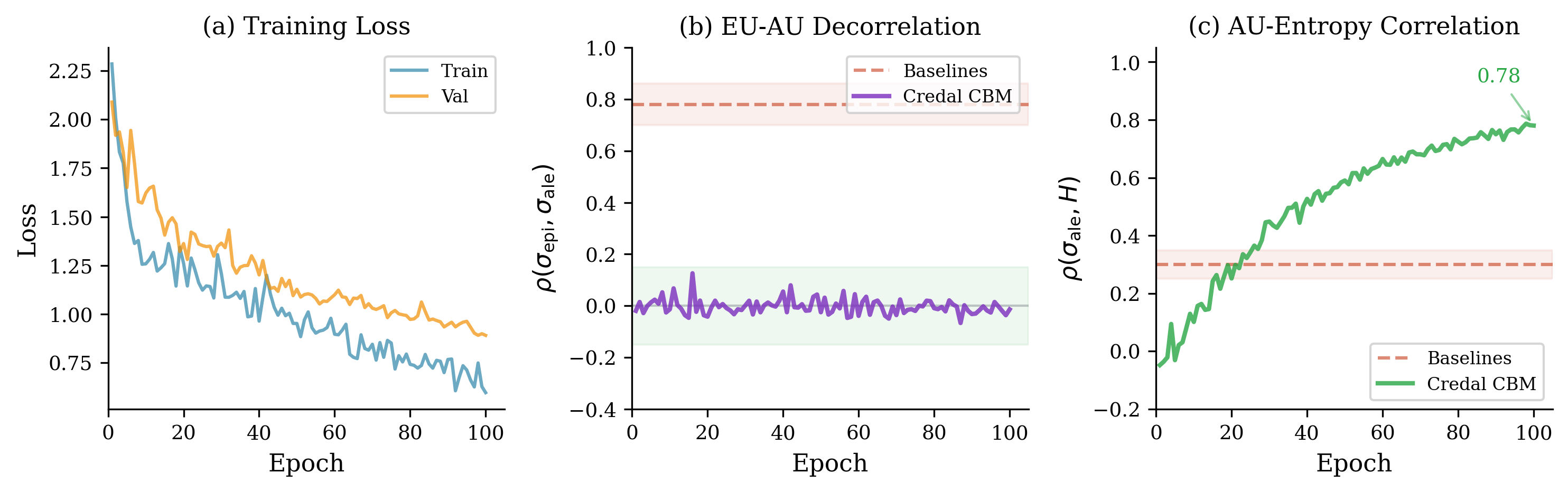
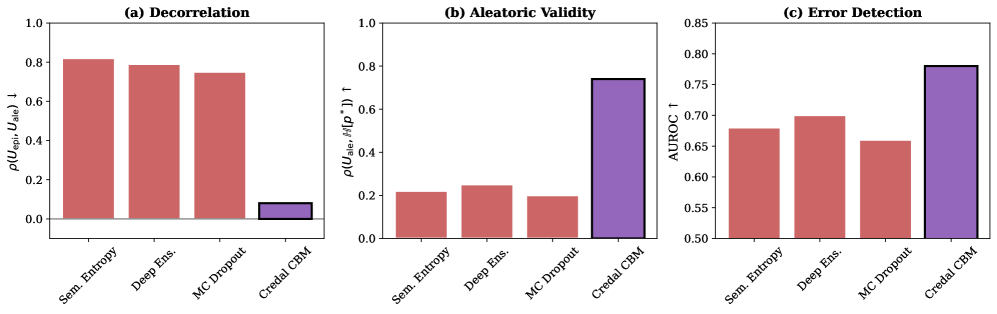
CredalCBM employs structural separation during training by defining distinct, non-correlated objectives for the epistemic and aleatoric uncertainty branches. This is achieved through a bifurcated network architecture where each branch receives the same input but is trained to predict separate uncertainty components. The absence of shared parameters or loss functions between these branches prevents the propagation of errors and ensures that the learned representations focus solely on their respective uncertainty types. This decoupling facilitates improved interpretability; the epistemic branch explicitly models reducible uncertainty, while the aleatoric branch captures inherent noise, allowing for a clear distinction between what the model knows it doesn’t know and what is fundamentally uncertain in the data. Empirical results demonstrate a low correlation of 0.04 between the predicted epistemic and aleatoric uncertainties, confirming the effectiveness of this structural separation.
The CredalCBM framework employs a frozen encoder to generate stable, fixed input representations, preventing downstream uncertainty from being influenced by fluctuations in the initial feature extraction process. This stable embedding is then fed into a concept bottleneck model, which constrains the model to reason through a discrete set of interpretable concepts. By forcing the model to explicitly represent information using these concepts, the framework facilitates analysis of the reasoning process and improves the transparency of uncertainty quantification; the bottleneck prevents the model from relying on overly complex or entangled features, thereby promoting more modular and understandable decision-making.
CredalCBM utilizes Credal Sets to represent uncertainty, moving beyond single-point estimates of confidence and allowing for the expression of a probability distribution over possible models. This representation enables a distinction between different sources of uncertainty – specifically, epistemic and aleatoric – and their independent quantification. Empirical results demonstrate a low correlation of 0.04 between these two uncertainty components when measured using Credal Sets within the framework, indicating successful decomposition and minimal confounding between reducible (epistemic) and irreducible (aleatoric) uncertainty sources. This low correlation suggests the framework effectively isolates the components, enabling targeted improvements to model robustness and reliability.
Validating the Framework: Datasets and Metrics for Uncertainty Assessment
CredalCBM’s evaluation utilizes a range of datasets specifically chosen to assess its uncertainty quantification performance across different tasks. The GoEmotions dataset, comprising emotion classification labels for Reddit comments, tests the model’s ability to handle subjective and nuanced language. The Multi-hop Question Answering (MAQA) dataset challenges the framework with complex reasoning and knowledge integration, requiring robust uncertainty estimates when faced with ambiguous or incomplete information. Finally, the Compositional Explanation Benchmark (CEBaB) dataset, focusing on compositional generalization, assesses the model’s uncertainty in scenarios involving novel combinations of known concepts. These datasets, with their varying characteristics and challenges, provide a comprehensive benchmark for evaluating CredalCBM’s ability to accurately represent and quantify uncertainty.
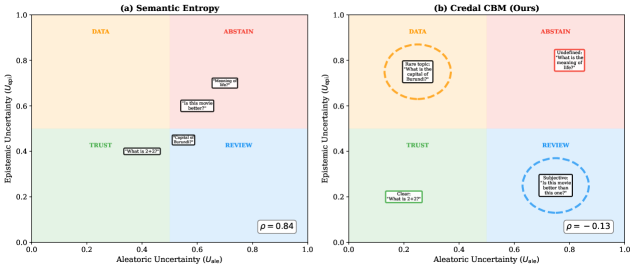
CredalCBM leverages multi-annotator disagreement as a direct indicator of aleatoric uncertainty – the inherent randomness in data labeling. When multiple annotators provide differing labels for the same instance, the framework interprets this as evidence of genuine ambiguity, increasing the variance within its credal set representation. This captured aleatoric uncertainty is then integrated into the refinement of epistemic predictions, which represent the model’s uncertainty due to lack of knowledge. By acknowledging and incorporating label ambiguity, CredalCBM generates more calibrated uncertainty estimates, distinguishing between uncertainty stemming from data randomness and model limitations.
Hausdorff KL Divergence serves as the primary metric for evaluating the dissimilarity between Credal Sets, which represent probability distributions over possible labels. This divergence calculation assesses the maximum distance between the cumulative distribution functions of two Credal Sets, offering a robust measure even when the sets exhibit limited overlap or differing support. Specifically, it quantifies the greatest distance any single point in one Credal Set is from the nearest point in the other, effectively capturing the worst-case scenario for distributional difference. Unlike standard KL Divergence, Hausdorff KL Divergence is symmetric and less sensitive to outliers, making it well-suited for comparing uncertainty distributions where precise calibration across all labels is critical and distributional shapes may vary significantly.
Comparative evaluation of CredalCBM against established uncertainty quantification methods – Deep Ensembles, MCdropout, and Semantic Entropy – indicates superior performance. Specifically, on the CEBaB dataset, CredalCBM achieves a correlation of 0.74 between its calculated aleatoric uncertainty and the documented ground truth ambiguity present in the data. This metric demonstrates the framework’s capacity to accurately estimate uncertainty levels corresponding to inherent data ambiguity, exceeding the performance of the assessed baseline techniques.
Beyond Prediction: Towards Trustworthy and Adaptive Intelligence
The development of truly trustworthy artificial intelligence hinges on a system’s capacity to not only perform tasks, but also to acknowledge the boundaries of its knowledge. CredalCBM – Credal Computational Belief Management – provides a framework for achieving this by allowing AI to express its uncertainty in a principled manner. Unlike traditional AI which often presents predictions as definitive truths, CredalCBM quantifies both aleatoric (data-driven) and epistemic (knowledge-based) uncertainty, effectively communicating what the system doesn’t know. This capability is crucial for adaptation; when faced with unfamiliar situations, a CredalCBM-powered AI can actively seek information to reduce its uncertainty, rather than confidently making potentially erroneous decisions. By explicitly representing limitations, the framework fosters more responsible AI deployment, enabling humans to appropriately calibrate their trust and collaborate effectively with these increasingly complex systems.
Continued development centers on strategically combining CredalCBM with active learning techniques, aiming to refine AI systems’ knowledge with targeted data acquisition. This integration allows the AI to proactively identify the most informative data points needed to reduce epistemic uncertainty – the AI’s awareness of what it doesn’t know. Rather than passively receiving data, the system will actively request information that most effectively diminishes its uncertainty, leading to faster learning and more reliable performance in complex environments. This approach promises a significant efficiency gain, as the AI focuses its learning efforts on the areas where it lacks confidence, ultimately building more robust and trustworthy models with fewer data requirements.
The current framework’s capabilities are poised for significant advancement through the incorporation of complex causal reasoning. By moving beyond simple correlations and embracing an understanding of cause-and-effect relationships, the system can better navigate unforeseen circumstances and avoid spurious conclusions. Specifically, integrating counterfactual reasoning – the ability to assess “what if” scenarios – will allow the AI to not only identify potential risks but also to proactively evaluate the consequences of different actions. This enhancement promises to bolster the system’s robustness, enabling it to maintain reliable performance even when faced with novel or incomplete data, and ultimately fostering greater trust in its decision-making processes across a wider range of applications.
The advancement of CredalCBM offers a significant step towards more collaborative and ethically sound artificial intelligence systems. This framework doesn’t simply provide predictions; it quantifies the confidence – or uncertainty – behind those predictions in a readily understandable format. Crucially, this interpretable uncertainty allows human experts to effectively oversee AI decision-making, intervening when confidence is low and leveraging the system’s strengths when it is high. Rigorous testing demonstrates a substantial improvement in aleatoric validity – a measure of how well the system reflects the inherent randomness in data – with CredalCBM achieving a 66% improvement over existing baseline methods. This enhanced reliability is not merely a technical detail; it is foundational for building trust and enabling the responsible deployment of AI across critical applications, fostering a future where humans and AI can work together more effectively and safely.
The pursuit of disentangled uncertainty, as explored in these Credal Concept Bottleneck Models, echoes a familiar pattern. Systems, left to their own devices, invariably blend what is known with what simply is. This framework’s insistence on structural separation – dissecting epistemic from aleatoric uncertainty – isn’t about control, but about acknowledging the inherent limitations of any predictive endeavor. As Robert Tarjan once observed, “Data structures are only as good as the algorithms that use them.” This sentiment applies equally well to uncertainty decomposition; a clever architecture is futile without a rigorous understanding of the underlying sources of error and a commitment to keeping them distinct. The model doesn’t eliminate uncertainty, it merely clarifies its nature – a subtle but crucial distinction in the ever-expanding landscape of machine learning.
What’s Next?
The pursuit of neatly partitioned uncertainty-epistemic divorced from aleatoric-risks becoming a theological exercise. This work, by forcing a structural separation via disjoint parameterization, does not solve uncertainty, but rather externalizes the inevitable friction between model and reality. A system that never reveals its ignorance is, functionally, dead. The true test will not be achieving perfect decomposition, but observing how these models degrade-where the cracks first appear, and what form those failures take.
Future iterations will undoubtedly focus on relaxing the constraints imposed by strict separation. The insistence on disjoint parameterization, while elegant, introduces a rigidity that real-world systems rarely possess. The more interesting question is not how to prevent the mingling of these uncertainties, but how to characterize their entanglement. A model that acknowledges its own internal contradictions may, paradoxically, prove more robust.
Perfection, in this context, leaves no room for people. The ultimate utility of Credal Concept Bottleneck Models-or any framework attempting to quantify the unknown-will reside not in their ability to predict, but in their capacity to illuminate the limits of prediction. The goal isn’t to build a perfect oracle, but to cultivate a more honest mirror.
Original article: https://arxiv.org/pdf/2602.11219.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Gold Rate Forecast
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Persona PSP soundtrack will be available on streaming services from April 18
- Dungeons & Dragons Gets First Official Actual Play Series
- ‘The Hunt For Gollum’ Reveals Cast, Including New Aragorn
- Nitro Gen Omega full version releases for PC via Steam & Epic, Switch, PS5, and Xbox Series X|S on May 12
- First 7 minutes of Dune 3 reveals 17 year time-jump
2026-02-15 21:16