Author: Denis Avetisyan
A new method, NSM-Bayes, dramatically improves the speed and robustness of Bayesian inference by leveraging neural networks and simulation.
This work introduces a provably-robust and fully amortised simulation-based inference technique using score-matching and neural networks to overcome limitations posed by outliers in complex models.
Despite the increasing reliance on complex simulation-based models for scientific inference, existing methods often struggle with noisy or erroneous data arising from real-world measurements. This paper, ‘Amortised and provably-robust simulation-based inference’, introduces a novel approach-NSM-Bayes-that addresses this limitation by providing provable robustness to outliers while enabling efficient, fully amortised Bayesian inference. This is achieved through a neural approximation of a weighted score-matching loss, circumventing the need for computationally expensive Markov chain Monte Carlo sampling and offering significant speedups. Could this method unlock more reliable and scalable inference across a wider range of scientific and engineering applications?
The Illusion of Certainty: Bayesian Inference in Complex Systems
The power of Bayesian inference hinges on evaluating the likelihood function – the probability of observing the data given a particular model – but this calculation often proves insurmountable when dealing with complex simulations. Many modern scientific endeavors, from climate modeling to particle physics, rely on computationally intensive processes that don’t yield easily expressed likelihoods. This ‘intractability’ arises because directly calculating the probability requires an exhaustive exploration of the simulation’s parameter space, a task that quickly becomes computationally prohibitive as the number of parameters increases. Consequently, researchers are often forced to rely on approximations, such as Markov Chain Monte Carlo (MCMC) methods, which themselves can be slow and require careful tuning to ensure accurate results. The limitations imposed by intractable likelihoods therefore represent a significant bottleneck in applying Bayesian statistics to increasingly complex and realistic scientific problems, necessitating the development of novel inference techniques.
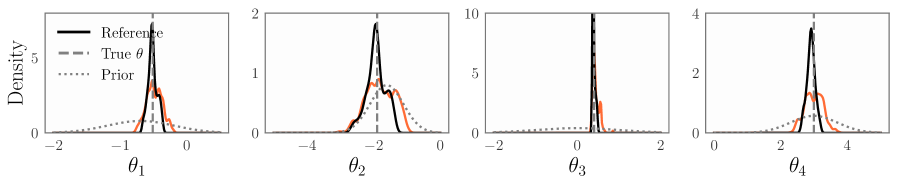
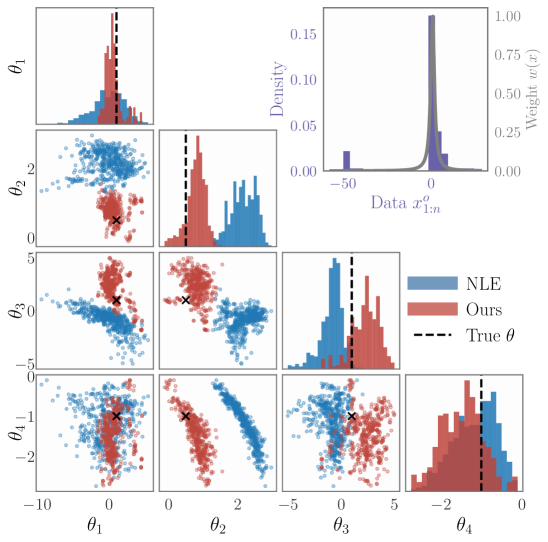
Traditional Bayesian inference, while powerful, exhibits a notable vulnerability to inaccuracies stemming from both outlying data points and imperfect model construction. Studies reveal that even a modest presence of outliers – as little as 10% – can introduce substantial bias into parameter estimates derived using Non-Local Estimation (NLE), a phenomenon clearly illustrated in Figure 1. This sensitivity arises because standard Bayesian approaches often assume data conform closely to the specified model, a condition rarely met in realistic applications. Consequently, the inferred parameters may not accurately represent the underlying system, diminishing the reliability of predictions and potentially leading to flawed decision-making. Addressing this challenge requires developing robust Bayesian techniques less susceptible to these common data and model imperfections.
Beyond Likelihoods: Score Matching for Robust Inference
NSM-Bayes provides a simulation-based approach to Bayesian inference that circumvents the requirement for explicitly defined likelihood functions. Traditional Bayesian methods rely on calculating or approximating the likelihood – the probability of observed data given model parameters – which can be analytically intractable or computationally expensive, especially in complex models. NSM-Bayes instead frames the inference problem as matching the score function – the gradient of the log likelihood – using simulation. This is achieved by constructing a loss function that penalizes discrepancies between the score function estimated from simulated data and the observed data, enabling parameter estimation without direct likelihood evaluation. This capability is particularly advantageous when dealing with complex models where likelihood functions are difficult or impossible to formulate.
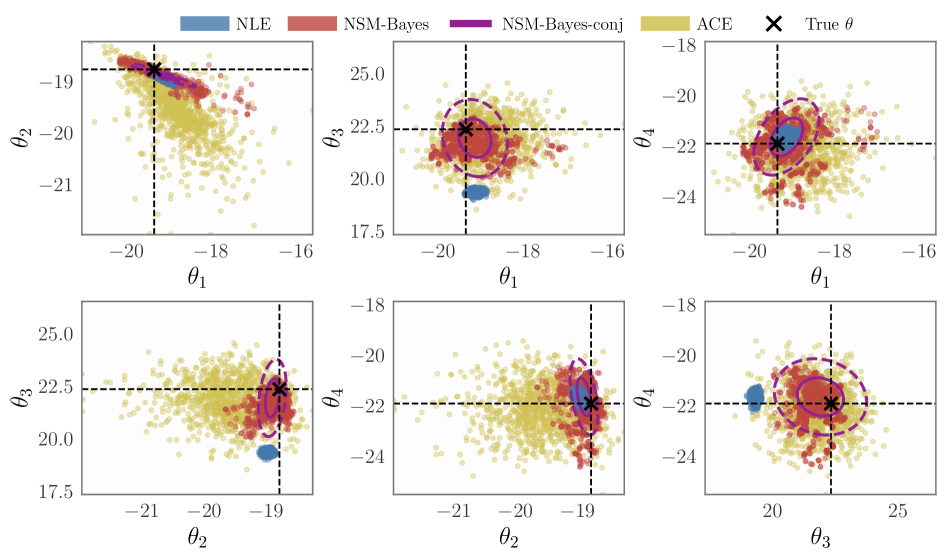
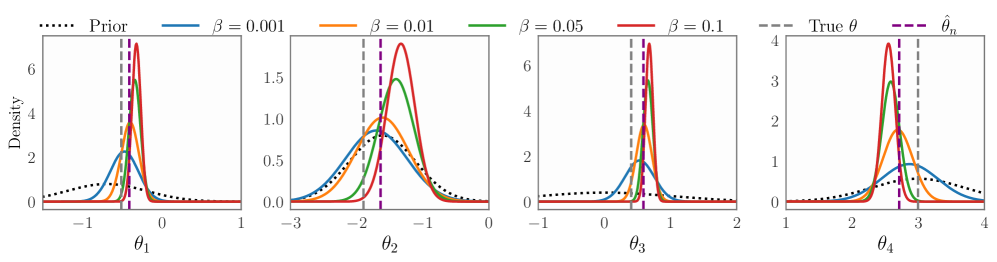
NSM-Bayes exhibits enhanced robustness to both outlier data points and inaccuracies in the underlying model specification through the application of score-matching techniques. Empirical validation across three distinct simulation environments – the g-and-k distribution, a Susceptible-Infected-Recovered (SIR) Epidemic Model, and a Radio Propagation Simulator – demonstrates consistent performance improvements compared to standard Bayesian methods. Specifically, the score-matching approach allows NSM-Bayes to accurately estimate parameters even when faced with data corrupted by outliers or when the assumed model does not perfectly represent the true data-generating process. These results indicate that NSM-Bayes provides a more reliable inference framework in practical scenarios where data quality or model fidelity may be compromised.
The NSM-Bayes method employs a loss function designed to promote stable learning during Bayesian inference. This loss function is composed of two primary components: the trace of the Hessian matrix and the gradient of the weighting function. The Hessian trace term, calculated as \text{Tr}(\nabla^2 \log p(x|\theta)) , regularizes the learning process by penalizing high curvature in the parameter space, thus preventing instability. Simultaneously, the gradient of the weighting function, \nabla w(x) , adjusts the importance weights assigned to simulated samples, enabling the method to effectively handle complex posterior distributions and improve the accuracy of parameter estimation. The combined effect of these two components results in a loss function that is both robust and efficient, facilitating stable learning even in challenging scenarios.
Simplifying the Complex: Conjugate Priors and Efficient Computation
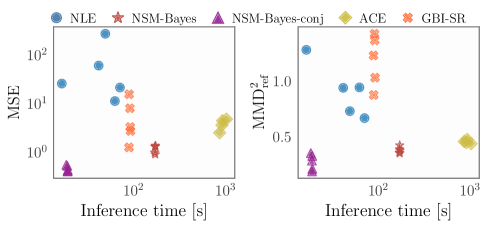
NSM-Bayes-conj builds upon the foundational Non-Gaussian Sequential Monte Carlo (NSM-Bayes) approach by imposing restrictions on the permissible network structures. Specifically, these restrictions are designed to facilitate the use of conjugate prior distributions. Utilizing conjugate priors allows for closed-form calculation of the posterior distribution, eliminating the need for iterative sampling procedures typically required in Bayesian inference. This simplification dramatically reduces computational cost, as posterior updates become analytical rather than numerical, and enables efficient processing of models with a larger number of parameters and data points compared to standard NSM-Bayes implementations. The resulting method retains the ability to model non-Gaussian distributions while achieving substantial gains in computational efficiency.
Restricting the network form in NSM-Bayes to enable Conjugate Posterior Updates results in a substantial reduction in computational cost. This simplification avoids complex calculations typically required for posterior inference, particularly in models with numerous parameters. Consequently, NSM-Bayes-conj exhibits improved scalability to high-dimensional problems, allowing it to efficiently process datasets and models with a large number of variables where standard methods may become computationally prohibitive. The computational benefits are derived from the ability to directly compute the posterior distribution without resorting to iterative approximation techniques, leading to faster training and prediction times.
Amortised inference, a variational inference technique, is inherently compatible with both the NSM-Bayes and NSM-Bayes-conj methodologies. Instead of performing inference independently for each data point, amortised inference learns a mapping from the data to the parameters of an approximate posterior distribution. This is typically implemented using a neural network – the network is trained to predict the posterior parameters given the input data, effectively ‘amortising’ the computational cost of inference across multiple data points. Consequently, posterior approximation becomes significantly faster, as it involves a forward pass through the trained neural network rather than solving an optimisation problem for each individual observation. This characteristic is crucial for scaling Bayesian inference to large datasets and complex models, providing a substantial performance gain over traditional methods.
A Robust Framework with Broad Implications for Scientific Modeling
Rigorous testing demonstrates the versatility of NSM-Bayes and NSM-Bayes-conj across markedly different scientific domains. The methods were successfully applied to the g\text{-}and\text{-}k distribution, a common benchmark for statistical inference; the SIR Epidemic Model, vital for understanding infectious disease dynamics; and a Radio Propagation Simulator, used in telecommunications and signal processing. Consistent performance across these diverse datasets-ranging from purely statistical problems to complex physical simulations-highlights the framework’s robustness and general applicability, confirming its capacity to deliver reliable parameter estimation and uncertainty quantification in a wide spectrum of scientific challenges.
The efficacy of these novel Bayesian inference methods hinges on Simulation-Based Inference (SBI), a computational approach that leverages the power of neural networks to navigate complex probability distributions. Rather than relying on traditional analytical solutions, SBI employs neural networks as learnable surrogates for computationally expensive simulation models. This allows for efficient approximation of the likelihood function-a critical component in Bayesian analysis-even when direct calculation is intractable. By training neural networks to map simulation parameters to observable data, the framework can rapidly estimate posterior distributions, quantifying uncertainty and enabling robust parameter estimation across diverse scientific domains, including epidemiology, physics-based modeling, and wireless communication. The neural network’s ability to generalize from limited simulations ensures the method’s adaptability and scalability, marking a significant advancement in tackling challenging inference problems.
The development of NSM-Bayes and NSM-Bayes-conj signifies a considerable leap forward in the field of Bayesian inference, offering a robust framework with far-reaching consequences for scientific modeling. Traditional methods often struggle with complex, computationally intensive models, hindering accurate parameter estimation and reliable uncertainty quantification; however, this new approach, leveraging the power of neural networks within a simulation-based framework, effectively addresses these challenges. This capability extends beyond specific applications, providing a versatile toolkit for researchers across diverse disciplines – from epidemiology and radio science to physics and engineering – enabling them to refine models, improve predictions, and gain a more comprehensive understanding of complex systems with greater confidence. The resulting advancements represent a state-of-the-art methodology poised to become a foundational element in modern data analysis and scientific discovery.
The pursuit of robust inference, as detailed in this work, reveals a humbling truth about theoretical constructs. One might say, as Niels Bohr did, “Prediction is very difficult, especially about the future.” This sentiment resonates deeply with the NSM-Bayes method presented; its provable robustness to outliers isn’t merely a technical achievement, but an acknowledgement that any model, however carefully constructed, operates within a realm of inherent uncertainty. The paper’s focus on amortised inference, utilizing neural networks, further underscores this point-a convenient tool for beautifully getting lost in the complexity of data, knowing full well that the map is not the territory. Black holes are, after all, the best teachers of humility.
Where Do the Simulations End?
This work, concerned with coaxing reliable answers from the chaos of simulation, inevitably bumps against the limits of any model. The presented method, NSM-Bayes, offers a pathway toward robustness, a shield against the inevitable outliers. But one should not mistake a well-defended pocket black hole for the real thing. The universe rarely cooperates with tidy probability distributions, and the very act of constructing a ‘likelihood surrogate’ implies a prior ignorance of the true generating process. Sometimes matter behaves as if laughing at laws, and no amount of clever amortisation can truly capture that defiance.
The pursuit of fully amortised inference remains a tantalising, yet potentially illusory, goal. Each step toward greater efficiency – toward simulations that run faster, that require less data – carries the risk of further abstraction, of losing sight of the fundamental uncertainties. The true challenge lies not in building ever-more-complex simulations, but in understanding when the simulations themselves become the problem.
Future work may well focus on quantifying the ‘distance’ between a simulation and reality, on developing metrics for assessing the trustworthiness of these synthetic worlds. But one suspects that the ultimate limit is not computational, but epistemic. There are questions to which the answers, like the singularities at the heart of black holes, lie forever beyond the event horizon of observability.
Original article: https://arxiv.org/pdf/2602.11325.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- All Itzaland Animal Locations in Infinity Nikki
- Gold Rate Forecast
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Persona PSP soundtrack will be available on streaming services from April 18
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- “67 challenge” goes viral as streamers try to beat record for most 67s in 20 seconds
2026-02-15 11:29