Author: Denis Avetisyan
New research dissects the sources of error in large language models, separating genuine ambiguity from inherent instability to improve their reliability.
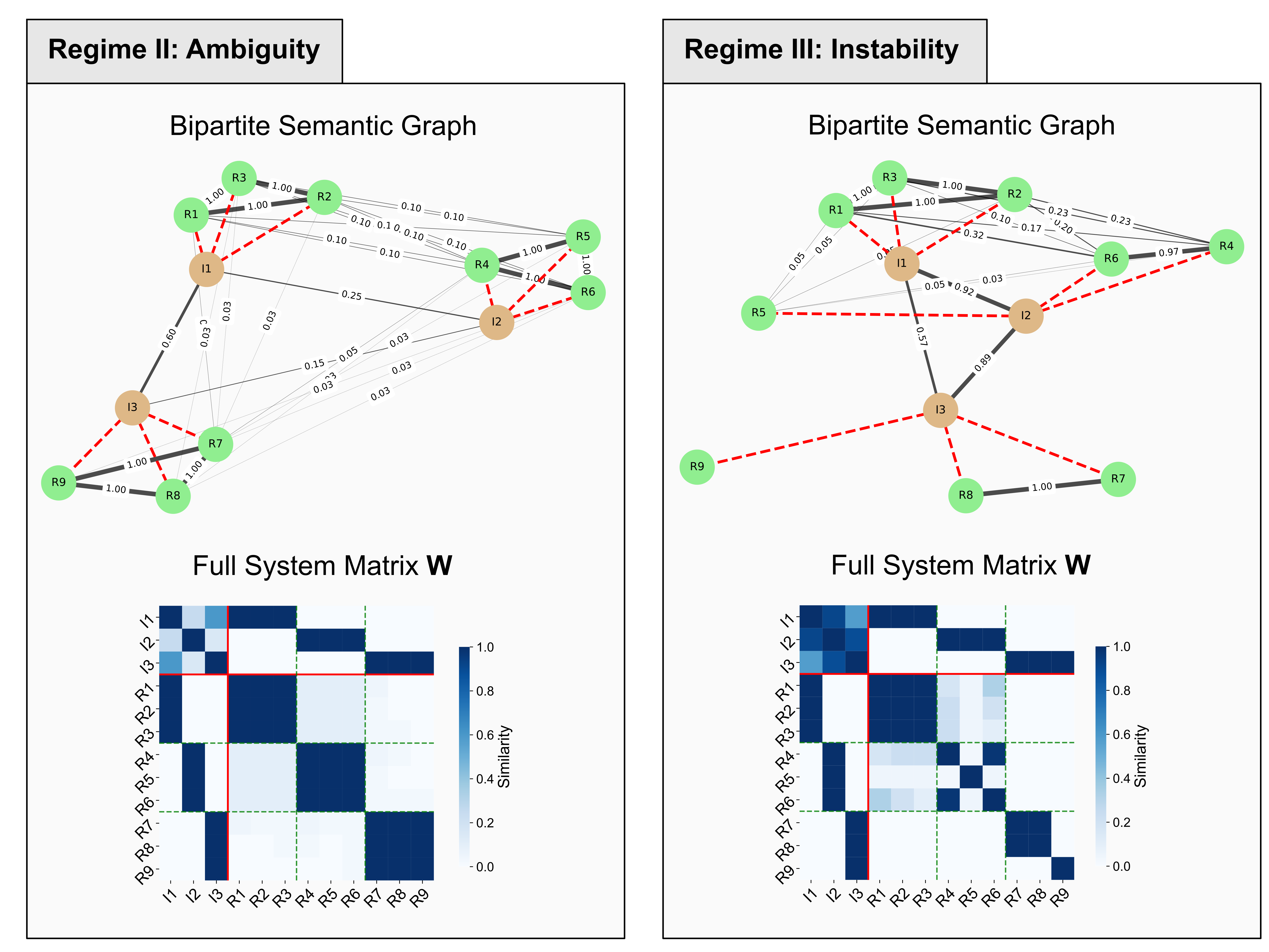
This study introduces CLUES, a framework for decomposing uncertainty in language models applied to clinical text-to-SQL tasks using kernel entropy and the Schur complement.
Reliable deployment of large language models often suffers from unpredictable outputs, yet distinguishing why a model fails remains a critical challenge. This is addressed in ‘Disentangling Ambiguity from Instability in Large Language Models: A Clinical Text-to-SQL Case Study’, which introduces CLUES, a framework that decomposes uncertainty in Text-to-SQL tasks into semantic ambiguity-requiring query refinement-and model instability-necessitating human review. By modeling the process as a two-stage interpretation-to-answer pipeline and leveraging the \text{Schur complement} of a semantic graph, CLUES improves failure prediction and offers a diagnostic decomposition unavailable from single uncertainty scores. Could this nuanced understanding of LLM failure modes pave the way for more robust and trustworthy clinical decision support systems?
Uncertainty: The Ghost in the Machine
The promise of easily querying databases using natural language faces a significant hurdle: ambiguity. A single question, phrased in everyday language, can often be interpreted in multiple valid ways, each potentially leading to a different SQL query and, consequently, a different result. Text-to-SQL systems, designed to bridge this gap, struggle with this inherent linguistic imprecision. For example, a query like “Show me the highest sales” leaves open questions about what constitutes “sales” – is it revenue, units sold, or profit? – and which timeframe is relevant. This ambiguity isn’t simply a matter of poor phrasing; it’s woven into the structure of language itself, and if unaddressed, it introduces substantial unreliability into data analysis, potentially leading to incorrect conclusions and flawed decision-making. The system must therefore contend with not just what is being asked, but how it can be reasonably understood.
The inherent slipperiness of natural language, and the challenges in computationally representing its meaning, contribute significantly to ambiguity. Linguistic properties like polysemy – where a single word carries multiple meanings – and the reliance on context for disambiguation create a baseline level of uncertainty. However, current Text-to-SQL models often struggle to fully capture these nuances. They rely on distributional semantics, learning word relationships from large datasets, but this approach can fall short when encountering novel phrasing or subtle contextual cues. Consequently, the models’ internal representation of semantic meaning may be incomplete or inaccurate, leading to multiple plausible interpretations of a single query and introducing uncertainty into any subsequent data analysis. This isn’t simply a matter of incomplete data; it reflects a fundamental difficulty in bridging the gap between the fluidity of human language and the rigid structures of machine understanding.
When natural language queries are processed without acknowledging their inherent ambiguity, two distinct forms of uncertainty propagate into subsequent data analysis. Aleatoric uncertainty arises from the inherent randomness within the query itself – multiple valid interpretations mean any single answer will always contain a degree of noise. Simultaneously, epistemic uncertainty emerges from the model’s limited understanding of which interpretation is correct; the system simply doesn’t ‘know’ the user’s precise intent. This combination isn’t merely a statistical nuisance; it directly impacts the reliability of derived insights, potentially leading to flawed conclusions and misguided decisions. Failing to account for this ‘Semantic Uncertainty’ therefore undermines the entire analytical process, creating a situation where confidence in the results is unwarranted and the true signal obscured by layers of unpredictable variation.
Conventional approaches to natural language processing often treat queries as having a single, definitive interpretation, a simplification that masks the inherent ambiguity of human language. Consequently, Text-to-SQL systems, and other analytical tools reliant on translating language into structured queries, frequently produce inaccurate results or misleading insights. These systems struggle with the subtle variations in meaning-the implicit assumptions, contextual dependencies, and potential for multiple valid interpretations-present in even seemingly straightforward questions. This failure to account for semantic nuance doesn’t just introduce errors; it creates a false sense of certainty in data analysis, potentially leading to flawed conclusions and misguided decisions based on unreliable information. The limitations of these traditional methods highlight the critical need for more sophisticated techniques capable of recognizing and addressing the full spectrum of linguistic uncertainty.
Deconstructing Uncertainty: A Framework for Robustness
Semantic uncertainty, as addressed by CLUES, is not a monolithic issue but rather a combination of distinct factors. This framework specifically decomposes semantic uncertainty into ‘Ambiguity’ and ‘Conditional Instability’. Ambiguity refers to the presence of multiple plausible interpretations of a query, while Conditional Instability describes the sensitivity of model outputs to slight variations in input or internal states. By isolating these two components, CLUES enables targeted intervention strategies; for example, addressing ambiguity through interpretation diversification and mitigating conditional instability via robustness enhancements. This decomposition allows for a more precise understanding of uncertainty sources and facilitates the development of tailored solutions to improve model reliability and performance.
The CLUES framework utilizes the Schur Complement, a matrix operation from linear algebra, to decompose and quantify semantic uncertainty. Specifically, the Schur Complement allows for the isolation of ‘Ambiguity’ and ‘Conditional Instability’ by partitioning a larger covariance matrix representing overall uncertainty. This partitioning creates smaller, well-defined matrices that directly represent each uncertainty source. The determinant of the Schur Complement, calculated as det(A - BX^{-1}Y) where A, B, X, and Y are appropriately defined matrices representing the relationships between query, interpretation, and result, provides a quantifiable metric for the magnitude of each isolated uncertainty component. This mathematical isolation enables targeted analysis and mitigation strategies for each uncertainty source independently.
Interpretation-Augmented Generation (IAG) is a core component of the CLUES framework, functioning by systematically generating multiple plausible interpretations for a given user query before producing a response. This proactive approach contrasts with traditional methods that assume a single, correct interpretation. IAG achieves this by formulating diverse paraphrases and semantic variations of the initial query, effectively creating a set of alternative inputs to the system. Each of these interpreted queries is then processed independently, and the resulting outputs are analyzed to assess the range of potential answers and identify sources of uncertainty stemming from ambiguous phrasing or multiple valid interpretations of the user’s intent.
The CLUES framework utilizes a Bipartite Semantic Graph to model the relationship between potential query interpretations and their corresponding results. This graph consists of two disjoint sets of nodes – one representing distinct interpretations of a user’s query and the other representing the generated results associated with each interpretation. Edges connect each interpretation node to its resulting output nodes, visually and mathematically defining the mapping between input and output. This bipartite structure enables the quantification of uncertainty by analyzing the connectivity and distribution of results across interpretations; for instance, a high degree of overlap in results originating from different interpretations indicates robustness, while isolated results suggest conditional instability. The graph’s structure facilitates the identification of ambiguous queries – those with multiple plausible interpretations – and allows for targeted interventions to refine interpretations or generate more informative results.
Validating the System: Accuracy in the Face of Ambiguity
CLUES enhances the accuracy of Clinical Text-to-SQL by specifically addressing challenges posed by ambiguous natural language queries. Traditional Text-to-SQL systems often struggle with queries containing multiple interpretations or lacking sufficient contextual information, leading to incorrect SQL generation. CLUES mitigates this through a novel framework designed to identify and resolve ambiguity during the query processing stage. Experimental results demonstrate that CLUES achieves an Area Under the Receiver Operating Characteristic curve (AUROC) of 0.762 when evaluating performance with conditional instability (HR|IH), a statistically significant improvement (p<0.001) over the AUROC of 0.600 achieved using total uncertainty (HR). This indicates a substantial increase in the system’s ability to correctly interpret and translate ambiguous clinical questions into accurate SQL queries.
Validation of the CLUES framework utilizes both curated datasets and real-world clinical data. Specifically, the ‘EpiAskKB’ dataset provides a controlled environment for assessing performance, while integration with ‘Electronic Health Records’ (EHRs) demonstrates applicability to practical clinical scenarios. This dual approach ensures that CLUES is not only accurate in controlled tests but also robust and functional when applied to the complexities of actual patient data, enabling evaluation across a spectrum of clinical inquiries and data formats commonly found in healthcare systems.
Evaluation of CLUES on clinical Text-to-SQL tasks demonstrated a statistically significant improvement in accuracy when utilizing conditional instability (HR|IH) for uncertainty quantification. Specifically, CLUES achieved an Area Under the Receiver Operating Characteristic curve (AUROC) of 0.762 when assessing queries based on HR|IH, compared to an AUROC of 0.600 when utilizing total uncertainty (HR). This difference in AUROC values was determined to be statistically significant with a p-value less than 0.001, indicating a robust performance gain through the consideration of conditional instability in query evaluation.
The CLUES framework incorporates Heat Kernel smoothing applied to the bipartite graph representing query-schema relationships to improve the reliability of uncertainty quantification. This technique effectively diffuses uncertainty scores across the graph, allowing for a more nuanced assessment of query ambiguity and instability. By smoothing the uncertainty estimates, the framework reduces the impact of noisy or isolated signals, leading to a more stable and accurate representation of the confidence in the generated SQL query. This refined uncertainty quantification is critical for identifying potentially erroneous queries for review and improving overall system robustness, particularly in scenarios involving complex clinical data and ambiguous natural language inputs.
CLUES extends its capabilities beyond traditional clinical Text-to-SQL tasks to encompass Open-Domain Question Answering (QA). Evaluation of CLUES on Open-Domain QA datasets demonstrates an Area Under the Receiver Operating Characteristic curve (AUROC) of 0.627 when utilizing Hierarchical Reinforcement learning with conditional instability (HR|IH) for uncertainty quantification. This represents a statistically significant improvement of +0.077 over the AUROC achieved using total uncertainty (HR) alone. This performance indicates CLUES’ adaptability and efficacy in broader QA scenarios where the scope of potential answers is not limited to structured database queries.
In deployment scenarios, CLUES facilitates a 51% reduction in error rates by prioritizing manual review of only 25% of incoming queries. This efficiency is achieved through identification of queries classified as Regime IV, which represent those exhibiting both high ambiguity and instability during the uncertainty quantification process. By focusing human review efforts on this subset of complex queries, CLUES significantly minimizes overall error without requiring exhaustive manual validation of all incoming requests, thereby offering a practical solution for real-world clinical Text-to-SQL systems.
Beyond Answers: A System That Understands Its Own Limits
The CLUES framework introduces ‘Regime Analysis’, a technique that categorizes queries not simply by what is asked, but by how certain the system is about answering them. This allows for the identification of distinct ‘regimes’ of uncertainty – areas where the model consistently struggles or excels. By grouping queries with similar uncertainty profiles, targeted interventions become possible; for example, data scientists can prioritize retraining efforts on regimes exhibiting high error rates or augment datasets with examples that reduce ambiguity in specific areas. This approach goes beyond blanket model improvements, enabling a more nuanced calibration process that optimizes performance across the entire spectrum of possible queries and promotes a more reliable and trustworthy AI system.
A core innovation within CLUES lies in its ‘Kernel Language Entropy’ metric, a rigorously defined approach to quantifying uncertainty in data analysis. Unlike traditional methods that often treat uncertainty as a byproduct, this metric directly measures the complexity and ambiguity inherent in language data by assessing the distribution of semantic kernels. Higher entropy values indicate greater uncertainty, potentially signaling issues with data quality – such as ambiguity, noise, or incompleteness – that could compromise the reliability of subsequent analyses. This allows for proactive identification of problematic data points, enabling targeted interventions like data cleaning, re-annotation, or the application of more robust modeling techniques, ultimately fostering more trustworthy and accurate AI systems. By providing a principled and quantifiable measure of uncertainty, the Kernel Language Entropy metric moves beyond simply detecting errors to understanding why they occur, and informing strategies to mitigate them.
The CLUES framework champions a shift toward responsible artificial intelligence by prioritizing the explicit modeling of uncertainty in data analysis. Rather than treating data as definitive, CLUES acknowledges and quantifies inherent ambiguities, allowing for a more nuanced understanding of results and a reduction in potentially misleading conclusions. This approach fosters transparency, as the system doesn’t simply provide answers, but also articulates the level of confidence associated with them. By openly communicating these uncertainty levels, CLUES empowers users to critically evaluate findings, identify areas requiring further investigation, and ultimately make more informed decisions, thereby mitigating the risks associated with opaque or overconfident AI systems.
Traditional analytical systems often present results as definitive statements, obscuring the inherent limitations of data and algorithms. This framework, however, fundamentally shifts that paradigm by prioritizing the quantification of confidence alongside answers themselves. Rather than simply stating what a model predicts, it details how certain the prediction is, offering a nuanced understanding of reliability. This move towards uncertainty-aware analysis is critical for responsible AI deployment, allowing stakeholders to assess risk, identify areas requiring further investigation, and ultimately, make more informed decisions based not just on outcomes, but on the trustworthiness of those outcomes. The system delivers not just data, but metadata about the data, fostering transparency and accountability in complex analytical processes.
The pursuit of reliable outputs from Large Language Models, as demonstrated by the CLUES framework, inherently demands a willingness to dissect and challenge established norms. This work doesn’t merely accept model uncertainty; it actively deconstructs it, separating ambiguity from instability-a process akin to reverse-engineering a complex system to expose its vulnerabilities. Tim Berners-Lee aptly stated, “The Web is more a social creation than a technical one.” Similarly, understanding the nuances of LLM behavior requires recognizing that their ‘intelligence’ emerges from complex interactions, not inherent perfection. CLUES, by isolating these error sources, allows for targeted intervention-a calculated disruption intended to refine the system and ultimately extract more meaningful insights from the chaos.
Beyond Certainty: Charting Future Directions
The dissection of uncertainty-specifically, the separation of ambiguity from instability-presented in this work feels less like a solution and more like a refined interrogation. CLUES offers a useful taxonomy, but the true challenge lies not merely in identifying the sources of error, but in systematically exploiting that knowledge. Future efforts should focus on actively manipulating these decomposed uncertainties; could targeted data augmentation, informed by ambiguity scores, pre-emptively stabilize fragile models? Or might a system proactively solicit clarification when faced with high semantic ambiguity, effectively shifting the burden of precision to the input itself?
A critical limitation, inherent in the Text-to-SQL paradigm, is the assumption of a single ‘correct’ answer. Clinical data, however, rarely offers such neat resolutions. Expanding the framework to accommodate probabilistic SQL outputs, reflecting degrees of confidence or alternative interpretations, feels like a necessary, if uncomfortable, progression. The pursuit of ‘correctness’ may be a distraction; perhaps the real goal is building models that are reliably wrong, providing traceable reasoning even in the face of genuine epistemic uncertainty.
Ultimately, the value of CLUES, and similar decompositional approaches, rests on a principle often overlooked: transparency. Obfuscating errors behind aggregate metrics provides no leverage for improvement. True security, in this context, is not about achieving perfect accuracy, but about understanding where and why a system fails, and designing interventions that leverage those failures for ongoing refinement.
Original article: https://arxiv.org/pdf/2602.12015.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Gold Rate Forecast
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Persona PSP soundtrack will be available on streaming services from April 18
- Morgan Stanley’s Tokenized Tango: Wealth, AI, and the Onchain Waltz
- DTF St. Louis Series-Finale Recap: You Can’t Hold the Sun in Your Hand
- Warriors vs. Clippers Play-In Results According to NBA 2K26
- Dungeons & Dragons Gets First Official Actual Play Series
2026-02-15 03:01