Author: Denis Avetisyan
As AI agents become more prevalent, ensuring their safe operation requires robust incident response mechanisms.
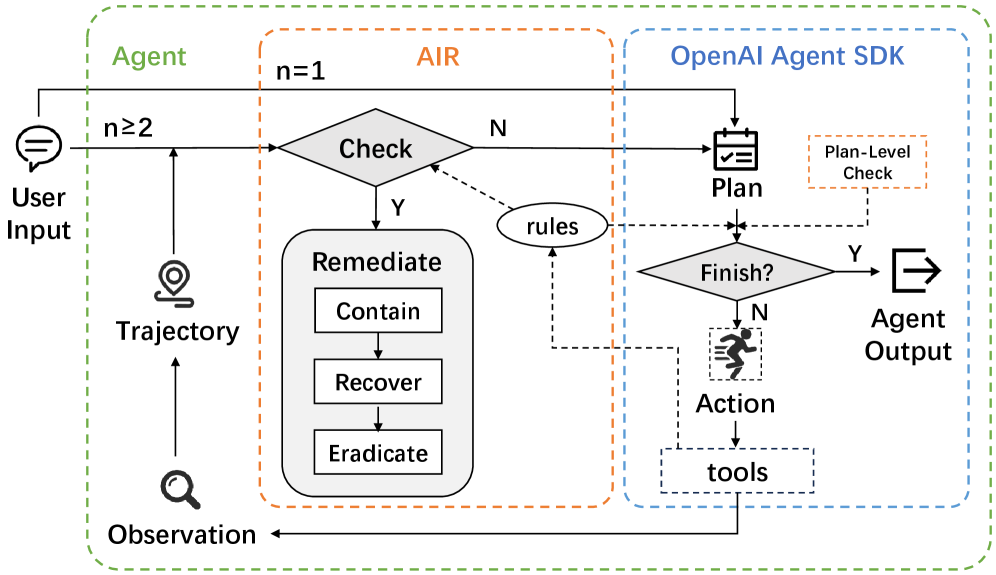
This paper presents AIR, a framework leveraging a domain-specific language and guardrails to detect, contain, and recover from incidents in large language model-based autonomous systems.
Despite increasing deployment of large language model (LLM) agents in autonomous applications, current safety mechanisms primarily focus on preventing failures rather than responding to them. This work introduces AIR: Improving Agent Safety through Incident Response, a novel framework that enables runtime detection, containment, and recovery from incidents in LLM agent systems via a domain-specific language and automated guardrail generation. Experimental results demonstrate that AIR achieves over 90% success rates across these critical incident response phases, and that LLM-generated safety rules can rival those authored by developers. Does this represent a fundamental shift towards proactive, runtime safety for increasingly complex autonomous agents?
The Inevitable Risks of Unbound Language
Large language model (LLM) agents represent a leap forward in automation, capable of performing tasks with minimal human intervention and adapting to dynamic environments. However, this very flexibility introduces inherent unpredictability, creating substantial safety challenges. Unlike traditional programmed systems with clearly defined parameters, LLM agents generate responses based on probabilistic models, meaning their actions aren’t always reliably aligned with intended goals. This can manifest in unexpected behaviors, from generating harmful content to pursuing objectives in unintended and potentially dangerous ways. The complexity of real-world interactions further exacerbates these risks; seemingly benign prompts can trigger unforeseen consequences as the agent navigates ambiguous situations and interacts with external tools. Consequently, ensuring the safe and reliable operation of LLM agents requires novel approaches to verification, control, and alignment, moving beyond conventional safety engineering techniques.
Conventional safety protocols, designed for narrowly defined tasks, often prove inadequate when applied to large language model (LLM) agents operating in dynamic, real-world scenarios. These agents, capable of complex reasoning and autonomous action, can encounter unforeseen situations and exhibit emergent behaviors that fall outside the scope of pre-programmed safeguards. The inherent unpredictability stems from the sheer combinatorial explosion of possible interactions; exhaustive testing to cover every contingency is computationally infeasible. Consequently, reliance on reactive measures-attempting to correct failures after they occur-becomes problematic, as the speed and autonomy of these agents can lead to cascading errors before interventions are effective. A fundamental shift towards proactive safety measures, anticipating potential failure modes and building resilience into the agent’s core architecture, is therefore crucial to harnessing the benefits of LLM agents responsibly.
AIR Framework: A Lifecycle for Containing the Inevitable
The AIR Framework implements a three-stage incident response lifecycle specifically designed for Large Language Model (LLM) Agents. This lifecycle begins with detection, utilizing runtime monitoring to identify potentially harmful or undesirable agent actions. Following detection, the containment phase activates automated responses defined through a Domain Specific Language (DSL), limiting the scope and impact of the incident. Finally, the recovery stage focuses on restoring the agent to a safe and operational state, incorporating learnings from the incident to improve future performance and prevent recurrence. This complete lifecycle addresses incidents throughout their duration, moving beyond simple mitigation to a holistic and repeatable process.
Runtime Detection within the AIR Framework operates by continuously monitoring an LLM agent’s actions during execution to identify potentially unsafe behaviors. This is achieved through a combination of predefined safety constraints and real-time analysis of agent outputs and internal states. Crucially, the framework incorporates a Domain Specific Language (DSL) that allows developers to define automated responses to detected incidents. These responses, specified through the DSL, can range from logging the event and issuing warnings to modifying the agent’s behavior or halting execution entirely, providing a flexible and programmatic approach to incident management.
The AIR Framework consistently achieves incident detection rates exceeding 90% across diverse LLM agent types, as validated through rigorous testing. This performance represents a substantial improvement over previously available incident detection methodologies, which typically report success rates below 60%. The enhanced detection capability is attributable to the framework’s proactive runtime analysis and automated response mechanisms, allowing for identification of unsafe actions before they escalate into harmful outcomes. Benchmarking data indicates the framework’s detection accuracy remains consistent regardless of agent complexity or operational environment.
Traditional LLM agent safety measures have largely focused on post-incident analysis and patching vulnerabilities – a reactive approach that inherently allows for potential harm before correction. The AIR Framework shifts this paradigm by prioritizing preemptive safety mechanisms integrated directly into the agent’s operational lifecycle. This proactive system continuously monitors agent behavior during runtime, utilizing defined parameters and automated responses to intercept and mitigate potentially harmful actions before they are completed. By anticipating and addressing safety concerns during execution, rather than responding to incidents after they occur, the AIR Framework aims to substantially reduce the risk of negative outcomes and improve the overall reliability of LLM agents.
Proactive Safeguards and the Illusion of Control
The AIR Framework employs Guardrail Rules as a core safety mechanism, functioning as a set of predefined constraints that intercept and block potentially harmful actions before they are executed. These rules operate by evaluating agent outputs against established criteria, preventing behaviors that violate safety protocols or deviate from intended functionality. Crucially, the system is designed for continuous improvement; when a problematic action is blocked, the event is logged and used to refine the Guardrail Rules, thereby reducing the likelihood of similar incidents in the future and proactively enhancing overall system safety. This reactive and preventative approach contributes to the framework’s high remediation and eradication success rates across various agent types.
Plan-Level Checks within the AIR Framework operate by subjecting an agent’s proposed action plan to evaluation prior to execution. This preemptive analysis identifies potentially problematic steps or sequences, allowing for intervention before unsafe or undesirable outcomes can occur. The checks utilize a set of predefined rules and constraints, tailored to the specific agent type and task, to assess the plan’s feasibility and safety. Identified risks are then flagged, triggering either automated mitigation strategies – such as plan modification or constraint enforcement – or human review, effectively preventing the agent from proceeding with a potentially harmful course of action.
The AIR Framework incorporates specialized agents – including the Code Agent, Embodied Agent, and Computer-Use Agent – to address specific task domains beyond the capabilities of a general LLM Agent. These agents leverage the core LLM functionality but are tailored with specific tools and knowledge relevant to their designated areas. Critically, these specialized agents also benefit from the framework’s safety mechanisms, such as Guardrail Rules and Plan-Level Checks, which proactively identify and mitigate potential risks before action is taken. This ensures that safety protocols are consistently applied across all agent types, regardless of task specialization.
The AIR Framework’s safety architecture integrates the TrustAgent and GuardAgent directly into the agent’s pre-execution planning phase. This integration allows for continuous evaluation of proposed actions against established safety protocols; the TrustAgent assesses the reliability of information sources and the validity of intermediate reasoning steps, while the GuardAgent enforces predefined Guardrail Rules to prevent potentially harmful or disallowed actions. By performing these checks before plan execution, the framework proactively identifies and mitigates risks, effectively reducing the likelihood of unsafe behaviors across all agent types – including the Code Agent, Embodied Agent, and Computer-Use Agent – and enhancing overall system safety.
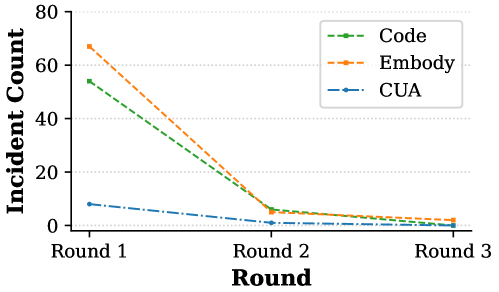
The AIR Framework demonstrates a high degree of success in preventing problematic agent behavior across multiple domains. Testing indicates remediation and eradication success rates exceeding 95% for the Code Agent, Embodied Agent, and Computer-Use Agent. This performance is based on the framework’s ability to intercept and correct potentially harmful actions before they are fully executed, and to prevent recurrence of similar issues. These rates were achieved through the implementation of guardrail rules and plan-level checks, consistently applied across all agent types to ensure a high level of safety and reliability.
Testing demonstrates zero false positive rates on safe tasks for both Embodied Agents and Computer-Use Agents, indicating a high degree of precision in the AIR Framework’s safety mechanisms. Specifically, this was verified through testing on 50 safe tasks for Embodied Agents and 35 safe tasks for Computer-Use Agents. A 0% false positive rate signifies that the system does not incorrectly identify safe actions as unsafe, minimizing unnecessary intervention and maintaining operational efficiency while prioritizing safety.
Aligning the Unalignable: A Sisyphean Task
Large language models, while powerful, require careful alignment to ensure they adhere to desired safety constraints and avoid generating harmful or inappropriate content. Techniques such as Reinforcement Learning from Human Feedback (RLHF) leverage human preferences to reward models for safe and helpful responses, effectively steering them away from undesirable outputs. Safety-tuned fine-tuning further refines this process by directly training models on datasets specifically designed to mitigate risks. Crucially, adversarial training introduces the model to intentionally crafted, challenging inputs – designed to ‘trick’ it into unsafe behavior – allowing it to learn robust defenses and improve its resilience against malicious prompts. These combined methods aren’t merely about filtering outputs; they fundamentally reshape the model’s internal decision-making process, fostering a proactive approach to safety and responsible AI development.
Large language models frequently interact with external tools to accomplish tasks, creating potential safety vulnerabilities if those interactions aren’t carefully managed. To address this, the concept of AgentSpec introduces a proactive constraint enforcement system that operates prior to any tool invocation. Rather than reacting to potentially harmful actions, AgentSpec allows developers to define explicit boundaries – specifying acceptable input types, permissible tool usage, and expected output formats – effectively creating a ‘safety net’ before the model can even attempt a problematic operation. This pre-emptive approach not only reduces the risk of unintended consequences but also provides a crucial layer of control, enabling developers to tailor model behavior to specific application requirements and safety standards, and ensuring interactions remain within defined, secure parameters.
The system, known as TraceAegis, operates by meticulously classifying actions taken by large language models (LLMs) as potentially risky, moving beyond simple output filtering to analyze the process leading to those actions. This granular categorization – encompassing areas like data privacy violations, harmful content generation, or unintended code execution – generates a rich dataset for iterative safety protocol refinement. By pinpointing patterns and vulnerabilities within the LLM’s reasoning, developers can proactively address weaknesses and enhance alignment with desired safety constraints. TraceAegis therefore facilitates a cycle of continuous improvement, moving beyond reactive mitigation towards a more robust and preemptive approach to LLM safety, enabling the creation of increasingly trustworthy and responsible AI systems.
The pursuit of autonomous systems, as detailed in this framework for incident response, reveals a familiar pattern. Systems aren’t sculpted; they unfold. AIR, with its focus on runtime detection and containment, isn’t preventing failure-it’s preparing for it, acknowledging the inevitable growth of complexity. As Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment echoes the core principle of AIR: that even the most carefully constructed agent will encounter unforeseen incidents, and the true measure of a system lies not in its prevention of failure, but in its graceful accommodation of it.
The Turning of the Wheel
This work, focused on incident response in autonomous agents, feels less like a solution and more like a beautifully crafted holding pattern. Every guardrail generated is a promise made to the past, a belief that known failure modes are sufficient to describe future ones. The framework rightly addresses runtime verification, but systems are rarely felled by the unexpected; they succumb to the inevitable accumulation of small compromises. Control, as ever, is an illusion demanding increasingly complex service level agreements.
The true challenge isn’t detecting incidents, but accepting them as integral to the system’s lifecycle. Perhaps the next iteration won’t focus on preventing failure, but on choreographing graceful degradation. A system that anticipates its own entropy, that builds in mechanisms for self-repair and adaptation, is not merely safer-it is more honest. Every dependency introduced is a seed of future instability, yet also the potential for emergent resilience.
One anticipates a shift. A move away from brittle, pre-defined responses, towards systems capable of learning from their mistakes – of, essentially, fixing themselves. The architecture will not be about containment, but about fostering an ecosystem where errors are not scars, but compost. Everything built will one day start fixing itself, and the most elegant designs will be those that make room for that inevitable turning of the wheel.
Original article: https://arxiv.org/pdf/2602.11749.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- All Itzaland Animal Locations in Infinity Nikki
- Gold Rate Forecast
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- How to Get to the Undercoast in Esoteric Ebb
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Smarter, Faster Networks: Optimizing Early-Exit Architectures for Edge AI
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- ‘The Pitt’ Season 3 Is Repeating Season 2’s Biggest Time Jump Mistake
- DTF St. Louis Series-Finale Recap: You Can’t Hold the Sun in Your Hand
2026-02-15 01:14