Author: Denis Avetisyan
New research reveals a growing imbalance in language technology, with a small number of languages dominating the benefits of artificial intelligence.
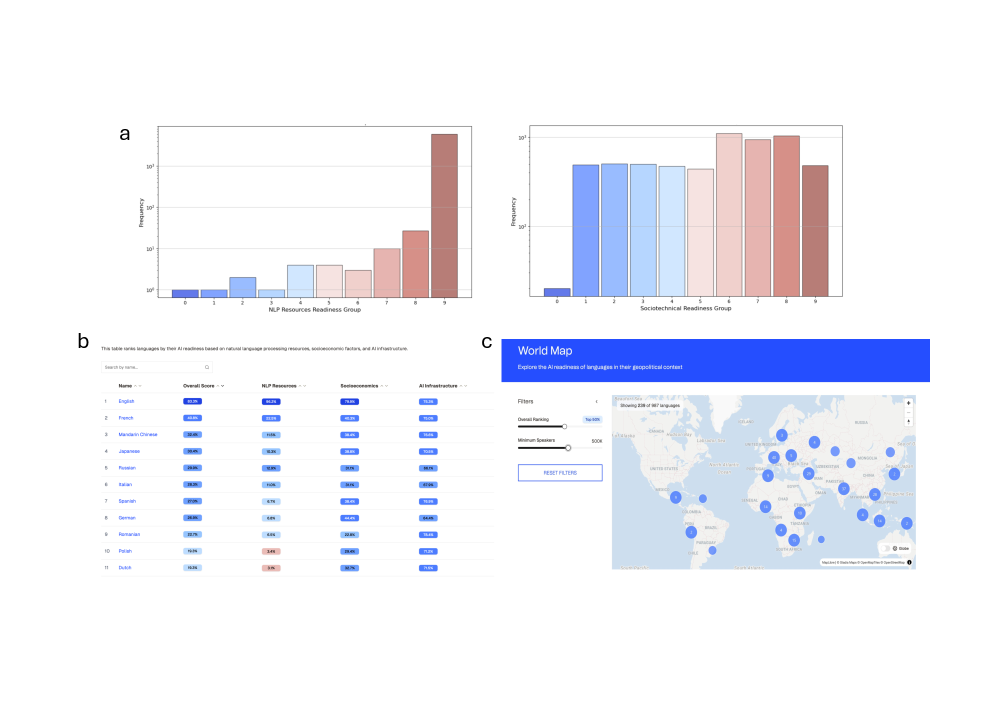
A novel index, EQUATE, assesses linguistic readiness for AI and highlights the urgent need for greater technological equity across languages.
Despite the potential of artificial intelligence to address global challenges, its benefits remain unevenly distributed, creating a new form of digital marginalization. This study, ‘Artificial intelligence is creating a new global linguistic hierarchy’, analyzes the systemic inequalities in language AI development across thousands of languages, revealing a concentration of resources in a small handful while the vast majority lack access. Our findings demonstrate an accelerating disparity, exceeding the diffusion patterns of previous information technologies, and introduce the Language AI Readiness Index (EQUATE) to map capacity and prioritize equitable deployment. Will this index serve as a crucial tool in fostering a more sustainable and inclusive future for language technology?
The Inevitable Echo: Linguistic Fracture in the Age of Intelligence
The rapid advancement of artificial intelligence has unlocked remarkable capabilities in language processing, yet these benefits are not universally shared. A significant digital language divide is emerging, wherein a small number of widely spoken languages dominate the landscape of AI-powered tools and resources. This imbalance means that while speakers of languages like English, Mandarin, and Spanish increasingly benefit from features like machine translation, automated content creation, and voice assistance, those who communicate in less prevalent tongues are often left behind. Consequently, access to information, educational opportunities, and even essential services becomes increasingly limited for a substantial portion of the global population, potentially widening existing social and economic inequalities and hindering full participation in the digital age.
The current trajectory of language technology development reveals a significant imbalance, with a small number of widely-spoken languages – often termed “high-resource” – receiving the vast majority of research and development investment. This prioritization isn’t merely a reflection of linguistic prevalence; it actively exacerbates existing global inequalities. Because machine learning models require massive datasets for training, languages with limited digital presence struggle to gain adequate representation, resulting in technologies that perform poorly, or not at all, for their speakers. Consequently, individuals communicating in these underrepresented languages face increasing barriers to accessing information, participating in digital economies, and benefiting from the advancements of artificial intelligence, creating a widening gap in opportunity and reinforcing linguistic disadvantage.
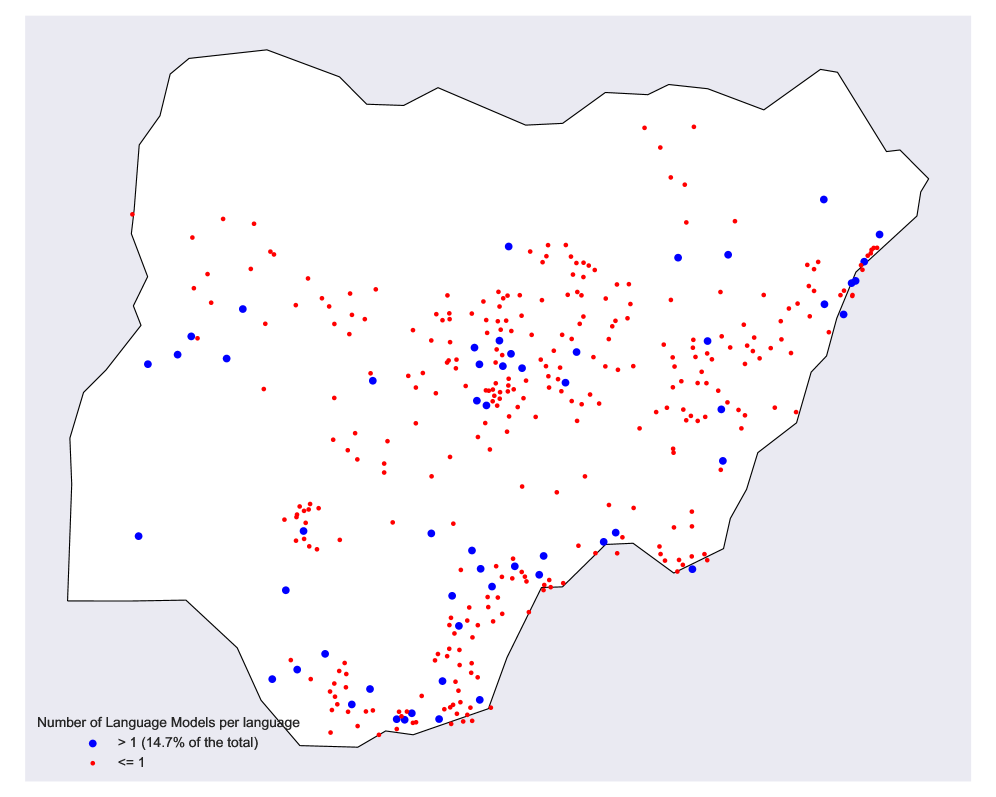
A recent analysis reveals a surprising disparity in language technology access: Nigeria demonstrates a higher proportion of its languages – 14.7% – covered by at least one language model, exceeding both the United States (14%) and Australia (6.8%). This finding challenges the assumption that technological advancement automatically translates to equitable distribution, and underscores a significant gap between nations in leveraging artificial intelligence for linguistic inclusivity. While often associated with technological leadership, the United States and Australia lag behind Nigeria in providing AI-driven language support to their diverse linguistic communities, potentially hindering access to digital information and opportunities for speakers of under-represented languages within those countries.
The current trajectory of language technology development risks creating a significant digital underclass, as speakers of low-resource languages face increasing marginalization. Without equitable access to tools like machine translation, speech recognition, and information retrieval, these communities are effectively excluded from a growing portion of the digital world. This limited access extends beyond simple communication; it restricts opportunities in education, employment, healthcare, and civic engagement, hindering social mobility and perpetuating existing inequalities. The inability to participate fully in the digital landscape not only silences diverse voices but also diminishes the collective knowledge base, as valuable cultural heritage and unique perspectives remain inaccessible to a wider audience. Addressing this disparity is therefore crucial not just for linguistic inclusivity, but for fostering a more equitable and informed global society.
EQUATE: Mapping the Ecosystem of Linguistic Readiness
The Language AI Readiness Index (EQUATE) is a composite metric designed to assess the suitability of a given language for the development and deployment of Artificial Intelligence applications. EQUATE moves beyond simple measures of data availability by systematically evaluating a language’s ecosystem across multiple dimensions. This evaluation incorporates both quantifiable factors – such as the volume of digitized text and the presence of computational resources – and qualitative assessments of supporting infrastructure and societal factors. The resulting index provides a standardized score representing a language’s overall readiness, enabling comparative analysis and targeted investment strategies to foster AI innovation across diverse linguistic communities.
The EQUATE framework assesses language AI readiness through three core pillars: AI Resource Availability, encompassing the presence of datasets, pre-trained models, and AI expertise within a language community; Digital Infrastructure, which measures access to computing power, internet connectivity, and data storage capabilities; and Socioeconomic Conditions, reflecting factors like education levels, economic stability, and government support for technological development. This tri-pillar approach ensures a holistic evaluation, moving beyond purely technical considerations to account for the broader ecosystem necessary for successful language AI implementation and adoption.
Statistical analysis of the Language AI Readiness Index (EQUATE) demonstrates that 58.4% of the variance in a language’s readiness for AI development is attributable to two principal components. These components effectively distinguish between broader societal development – encompassing factors like digital infrastructure and socioeconomic conditions – and the availability of AI-specific resources, such as datasets and computational power. This indicates that foundational societal factors play a dominant role in determining a language’s capacity to leverage AI technologies, exceeding the influence of purely AI-related resource availability.
The EQUATE framework delivers a detailed assessment of language AI readiness by integrating evaluations of AI Resource Availability, Digital Infrastructure, and Socioeconomic Conditions. This combined analysis identifies languages with existing foundational strengths – robust digital access and supportive economic factors – that can accelerate AI development. Conversely, EQUATE highlights languages where strategic investment in areas like data creation, computational resources, and educational programs will yield the greatest impact on future AI applicability. The resulting index provides a granular view beyond simple resource availability, enabling targeted resource allocation and focused development efforts to maximize the benefits of language AI technologies across a diverse range of languages.
Dissecting Readiness: Methodology Behind the EQUATE Index
The EQUATE index utilizes the Weighted Geometric Mean as its aggregation function to combine individual indicator scores within each pillar. This method was chosen over the arithmetic mean due to its sensitivity to low values; indicators receiving scores of zero in any category will result in a zero composite score, accurately reflecting a complete lack of resource availability. Weights are assigned to each indicator based on expert evaluation of its relative importance in determining language AI readiness, ensuring that key features contribute disproportionately to the overall assessment. The formula for the Weighted Geometric Mean is \sqrt[n]{\prod_{i=1}^{n} x_i^{w_i}} , where x_i represents the score for indicator i, w_i is its corresponding weight, and n is the total number of indicators. This approach provides a more nuanced and accurate representation of resource availability than simpler averaging techniques.
Stepwise regression was employed as a feature selection process to determine the optimal combination of indicators for predicting language AI readiness. This iterative method began with a full model incorporating all available indicators, and subsequently added or removed variables based on their statistical significance, as measured by the p-value associated with the F-statistic. Variables were added if their inclusion significantly improved the model’s fit, and removed if their presence did not contribute to a statistically significant improvement. The process continued until no further variables could be added or removed without reducing the model’s predictive power, resulting in a parsimonious model comprising only the most influential predictors. This refined model, utilizing a subset of the original indicators, demonstrates improved predictive accuracy and reduced risk of overfitting compared to a model incorporating all available features.
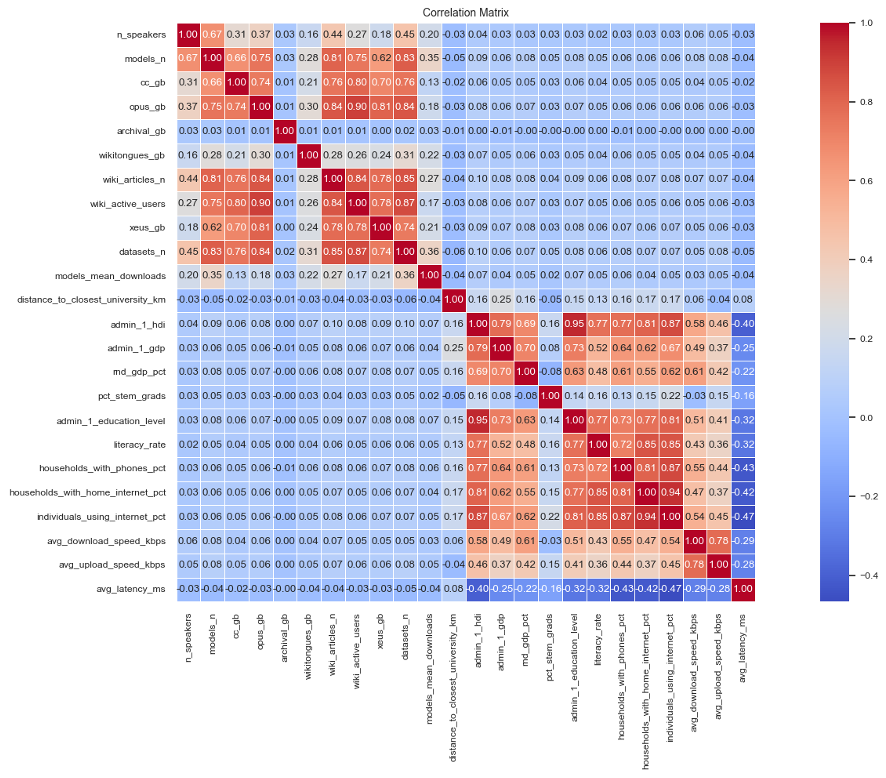
The EQUATE index utilizes a diverse set of publicly available corpora to quantify language AI resource availability. Data was sourced from CommonCrawl, a massive web archive providing raw text for language modeling; OPUS, a collection of translated texts facilitating machine translation research; Bible Translations, offering standardized text in numerous languages; and the ACL Anthology, a repository of computational linguistics research papers. These datasets collectively provide a substantial and varied base for assessing the quantity and diversity of text data available for each language, forming a core component of the AI readiness evaluation.
Statistical analysis revealed a Pearson correlation coefficient near zero (r ≈ 0) between the EQUATE index, representing AI resource availability, and established socioeconomic indicators such as GDP per capita, Human Development Index (HDI), and levels of educational attainment. This finding suggests that possessing resources conducive to language AI development – including large text corpora and computational infrastructure – does not reliably correlate with overall economic prosperity or societal advancement. Specifically, the observed correlation remained consistently low across multiple datasets and statistical controls, indicating that access to AI development resources is not necessarily a byproduct of, or contributor to, general development, and may be distributed independently of existing socioeconomic structures.
The Inevitable Cascade: Implications for an Inclusive AI Future
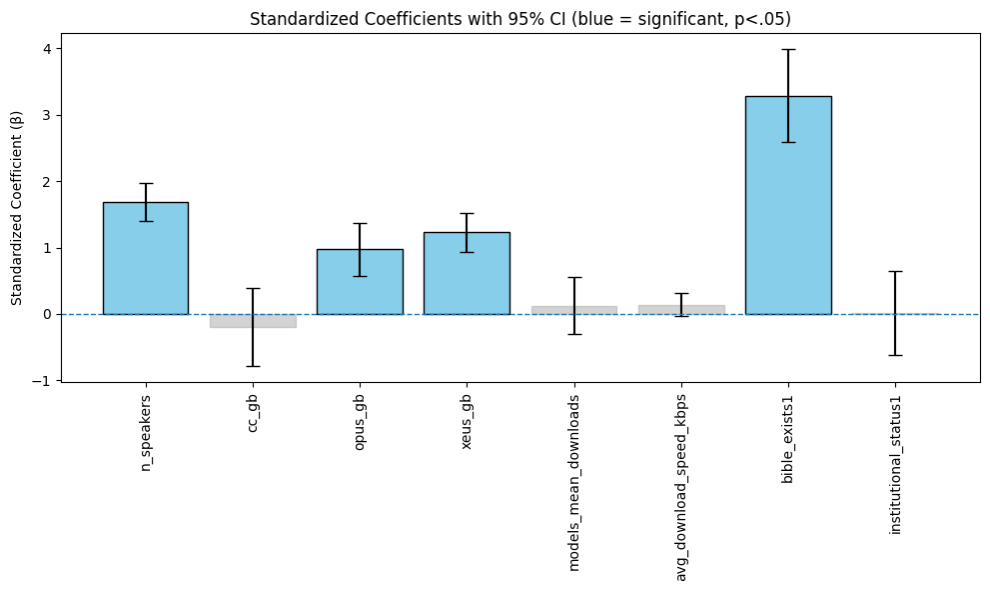
The study, utilizing the EQUATE model, demonstrates a significant correlation between a nation’s socioeconomic standing – as quantified by the Human Development Index (HDI) – and its preparedness for effectively integrating language AI technologies. This finding suggests that countries with lower HDI scores often lack the necessary infrastructure, digital literacy, and linguistic resources to fully benefit from advancements in natural language processing. Consequently, the gap in AI readiness isn’t solely a technological one, but is deeply intertwined with existing global inequalities; nations already facing developmental challenges may be further marginalized as language AI becomes increasingly prevalent. This highlights the critical need to consider socioeconomic factors when deploying and scaling these technologies, ensuring that advancements in artificial intelligence contribute to, rather than exacerbate, existing disparities.
The study demonstrates that digital language inequality isn’t simply a matter of access, but a complex interplay of factors that systematically advantages some languages and communities over others. This research reveals a widening gap in the availability of language technologies – like machine translation and speech recognition – based on socioeconomic indicators, effectively creating a digital divide within the linguistic landscape. Consequently, languages spoken by communities with lower Human Development Index scores are significantly under-represented, hindering their participation in the digital economy and limiting access to crucial information. The findings strongly suggest that broad, universal approaches to technological deployment are insufficient; instead, targeted interventions – including localized data collection, language-specific model training, and community-driven development – are essential to mitigate these disparities and foster truly inclusive AI systems.
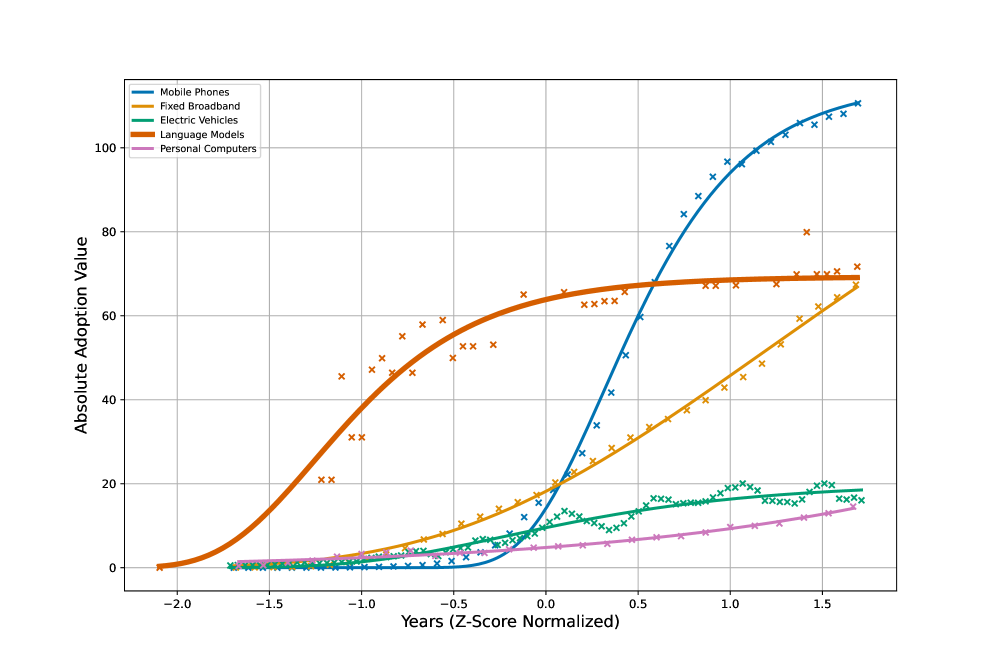
Further research can utilize the Gompertz Model – traditionally employed to study the spread of innovations and epidemics – to map the diffusion of language technologies across different socioeconomic landscapes. This analytical approach allows for the identification of critical thresholds and bottlenecks hindering equitable access, moving beyond simple assessments of availability to understand how these technologies propagate through communities. By modeling the adoption curves of language tools, researchers can pinpoint regions or demographics experiencing delayed uptake and, crucially, forecast future disparities. The resulting insights can then directly inform targeted interventions – such as localized training programs, infrastructure development, or culturally-relevant content creation – designed to accelerate adoption and bridge the digital language divide, ensuring these powerful tools benefit all segments of the population.
Analysis of technological growth rates reveals language models are experiencing an exceptionally rapid adoption trajectory when contrasted with other innovations. The study quantifies this acceleration using a growth rate constant – denoted as ‘cc’ – which measures the speed of early-stage uptake; language models demonstrably exhibit the highest ‘cc’ value among the technologies assessed. This indicates not merely growth, but a uniquely swift dissemination, suggesting language AI is establishing itself at a pace exceeding that of comparable digital tools. The findings imply a widening gap in access and capability if proactive measures aren’t taken to ensure equitable distribution and development of these powerful technologies, particularly as their influence expands across various societal domains.
The pursuit of language AI, as detailed in this study, reveals a pattern echoing the natural world – a concentration of resources and development in a select few, mirroring Zipfianization. It’s a predictable asymmetry; the system isn’t built, it grows along lines of least resistance. As Andrey Kolmogorov observed, “The most important things are always the simplest.” This simplicity-the concentration of effort on dominant languages-creates an AI readiness hierarchy. The EQUATE index, in attempting to quantify this disparity, isn’t merely measuring technological advancement, but charting the unfolding of a new, digital ecology. A silent system, quietly reinforcing existing linguistic power structures.
What’s Next?
The creation of an ‘AI Readiness Index’-EQUATE-is not a solution, but a meticulously charted mapping of the inevitable. It names the languages already accruing advantage, and, by implication, those destined for further marginalization. Architecture is how one postpones chaos; in this case, the chaos of linguistic homogenization driven not by conquest, but by algorithmic convenience. The observed Zipfianization of language AI-the concentration of resources in a few dominant tongues-was not a bug to be fixed, but a feature of any complex adaptive system. There are no best practices – only survivors.
Future work will inevitably focus on technical ‘fixes’ – data augmentation, cross-lingual transfer learning, and the like. These are palliative measures. The true challenge lies in acknowledging that language technology is not a neutral tool, but an engine of cultural stratification. The question is not how to make languages AI-ready, but how to design systems that tolerate, even celebrate, linguistic diversity in the face of relentless optimization.
Order is just cache between two outages. The current moment offers a fleeting opportunity to examine the underlying assumptions baked into these systems before the algorithmic tide fully recedes, revealing which languages were carried aloft and which were left stranded. The real measure of success will not be technical proficiency, but the degree to which these technologies amplify, rather than erode, the world’s linguistic tapestry.
Original article: https://arxiv.org/pdf/2602.12018.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Persona PSP soundtrack will be available on streaming services from April 18
- Raptors vs. Cavaliers Game 2 Results According to NBA 2K26
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- Dungeons & Dragons Gets First Official Actual Play Series
- Spider-Man: Brand New Day LEGO Sets Officially Revealed
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
2026-02-13 20:45