Author: Denis Avetisyan
New research explores how quantifying uncertainty can help deepfake detection systems identify when they don’t know, leading to more trustworthy results.
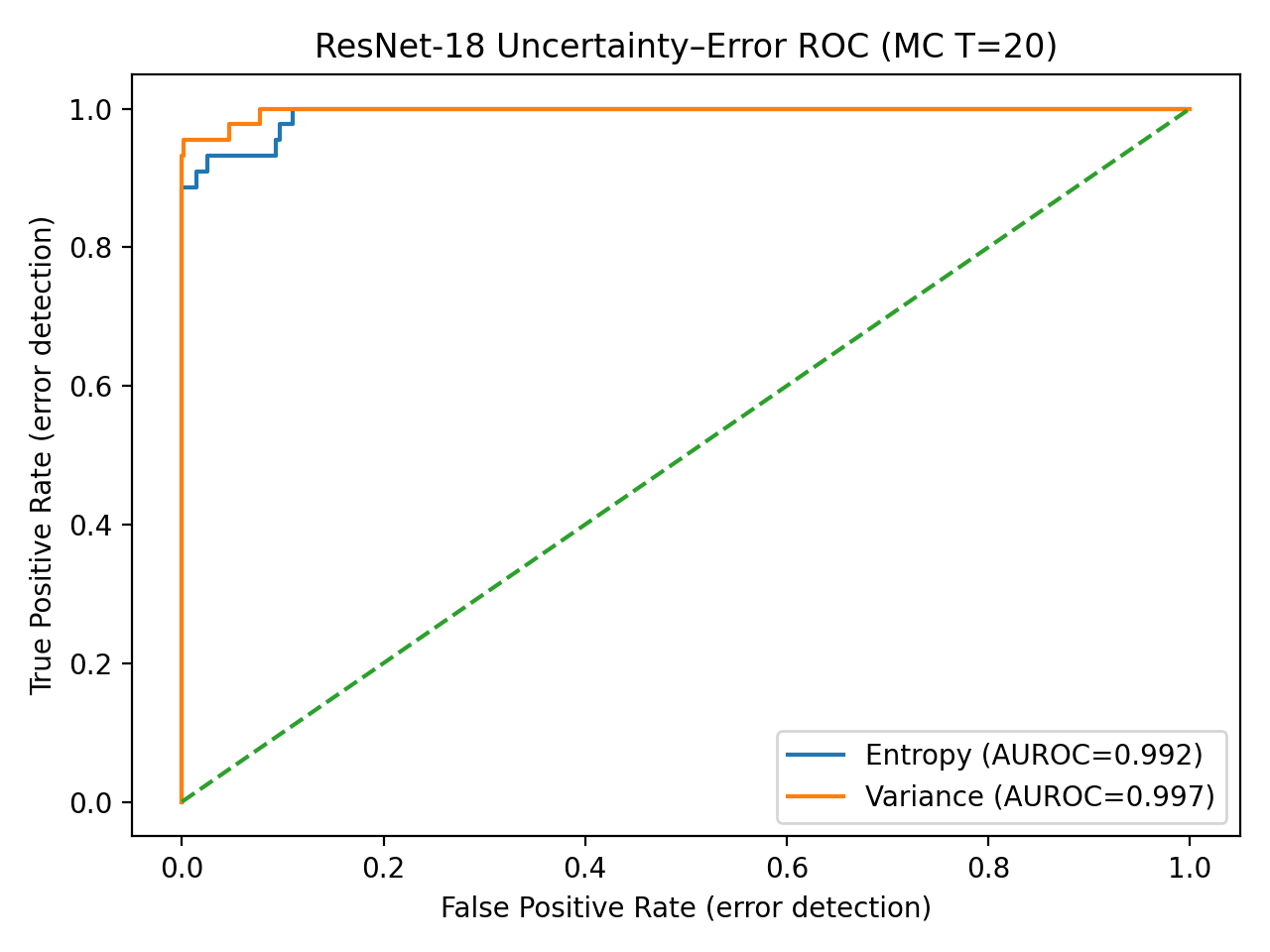
Conditional uncertainty-aware convolutional neural networks offer improved calibration and selective prediction for political deepfake detection, enhancing system reliability at high confidence levels.
While automated deepfake detection is increasingly vital for maintaining information integrity, most systems fail to signal when their predictions are unreliable-a critical limitation in high-stakes political contexts. This research, presented in ‘Conditional Uncertainty-Aware Political Deepfake Detection with Stochastic Convolutional Neural Networks’, investigates whether quantifying prediction uncertainty using stochastic convolutional neural networks can improve the reliability of deepfake detection. Results demonstrate that calibrated probabilistic outputs and uncertainty estimates enable risk-aware moderation policies, though their operational value is often concentrated at high confidence levels. When will nuanced uncertainty quantification become standard practice in safeguarding democratic processes from increasingly sophisticated synthetic media?
Decoding Reality: The Rise of Synthetic Media
The rapid advancement of artificial intelligence has fueled a surge in synthetic media, most notably through ‘deepfakes’ – convincingly realistic but entirely fabricated videos, images, and audio recordings. This proliferation presents a substantial threat to information integrity, as the ability to seamlessly manipulate reality erodes public trust in visual and auditory evidence. No longer limited to crude forgeries, deepfakes leverage sophisticated machine learning algorithms to create content that is increasingly difficult to distinguish from genuine sources. This poses risks across numerous domains, from political disinformation and reputational damage to financial fraud and the undermining of legal proceedings. The potential for misuse extends beyond malicious intent, as even seemingly harmless deepfakes can contribute to a climate of uncertainty and skepticism, making it harder for individuals to discern truth from fabrication.
The escalating sophistication of generative models is rapidly outpacing conventional techniques for detecting image manipulation. Historically, detection methods relied on identifying telltale artifacts – inconsistencies in lighting, blurring around edges, or mismatched color palettes – introduced during editing. However, contemporary deepfake technology, leveraging advancements in generative adversarial networks (GANs) and diffusion models, produces increasingly photorealistic synthetic content with remarkably subtle alterations. These techniques minimize detectable inconsistencies, blending synthetic elements seamlessly into genuine imagery. Consequently, traditional forensic analysis, even when employing sophisticated algorithms, struggles to reliably differentiate between authentic and fabricated visuals, creating a growing challenge for verifying the integrity of digital media and eroding public trust in visual information.
The pursuit of deepfake detection faces a fundamental challenge: discerning increasingly subtle manipulations from authentic content. Current systems, often relying on identifying telltale artifacts of generation processes, struggle with high-resolution deepfakes and those crafted with advanced techniques that minimize detectable flaws. This lack of nuance leads to both false positives – incorrectly flagging genuine media as synthetic – and false negatives, where sophisticated deepfakes evade detection. Consequently, reliance on these systems alone is insufficient; a robust defense requires a multi-faceted approach combining technological analysis with contextual verification and media literacy initiatives to build public resilience against misinformation and maintain trust in visual information.
Beyond Simple Accuracy: The Need for Reliable Prediction
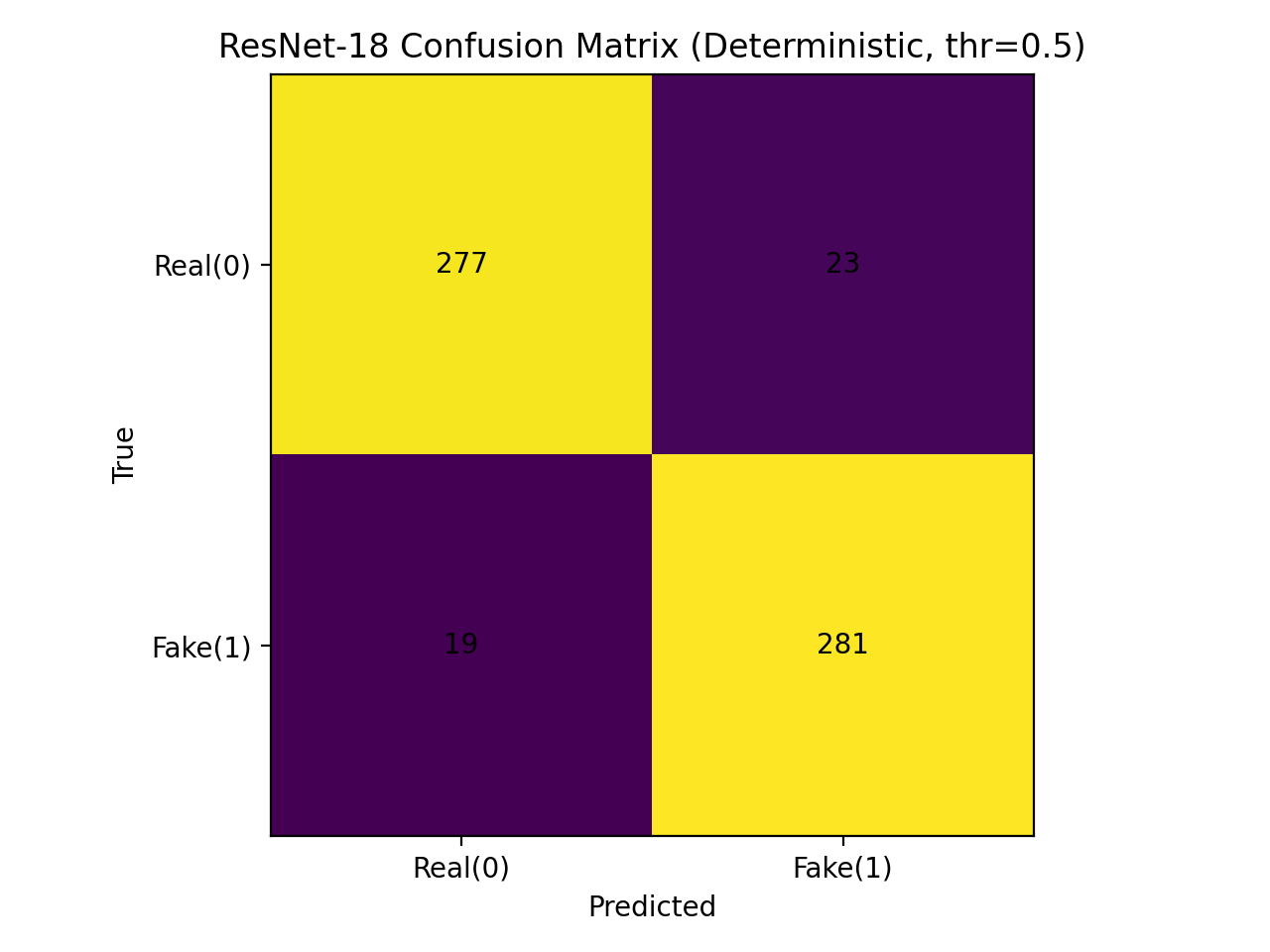
Discriminative performance, typically measured by metrics like accuracy or Area Under the Receiver Operating Characteristic curve (ROC-AUC), indicates a model’s ability to correctly classify inputs. However, this metric alone provides an incomplete picture of a model’s utility. A model can achieve high accuracy while still exhibiting unpredictable behavior on individual samples, particularly those outside the training distribution. Assessing prediction reliability involves quantifying the model’s confidence in its output; a reliable model not only classifies correctly but also provides a meaningful estimate of its certainty, allowing users to understand the potential for error and make informed decisions based on the prediction. This is especially important when considering the cost associated with incorrect classifications, and is distinct from simply calibrating the probabilities output by the model.
The criticality of reliable predictions is amplified in high-stakes applications such as deepfake detection due to the potential for significant repercussions from both false positives and false negatives. A false positive – incorrectly identifying authentic content as a deepfake – can damage reputations and erode trust in legitimate media. Conversely, a false negative – failing to detect a manipulated deepfake – can lead to the spread of misinformation, influence public opinion, and potentially incite real-world harm. Therefore, systems deployed in these scenarios require not only high accuracy but also a demonstrable understanding of their own limitations and the associated risks of incorrect classification, necessitating a focus on prediction reliability alongside discriminative performance.
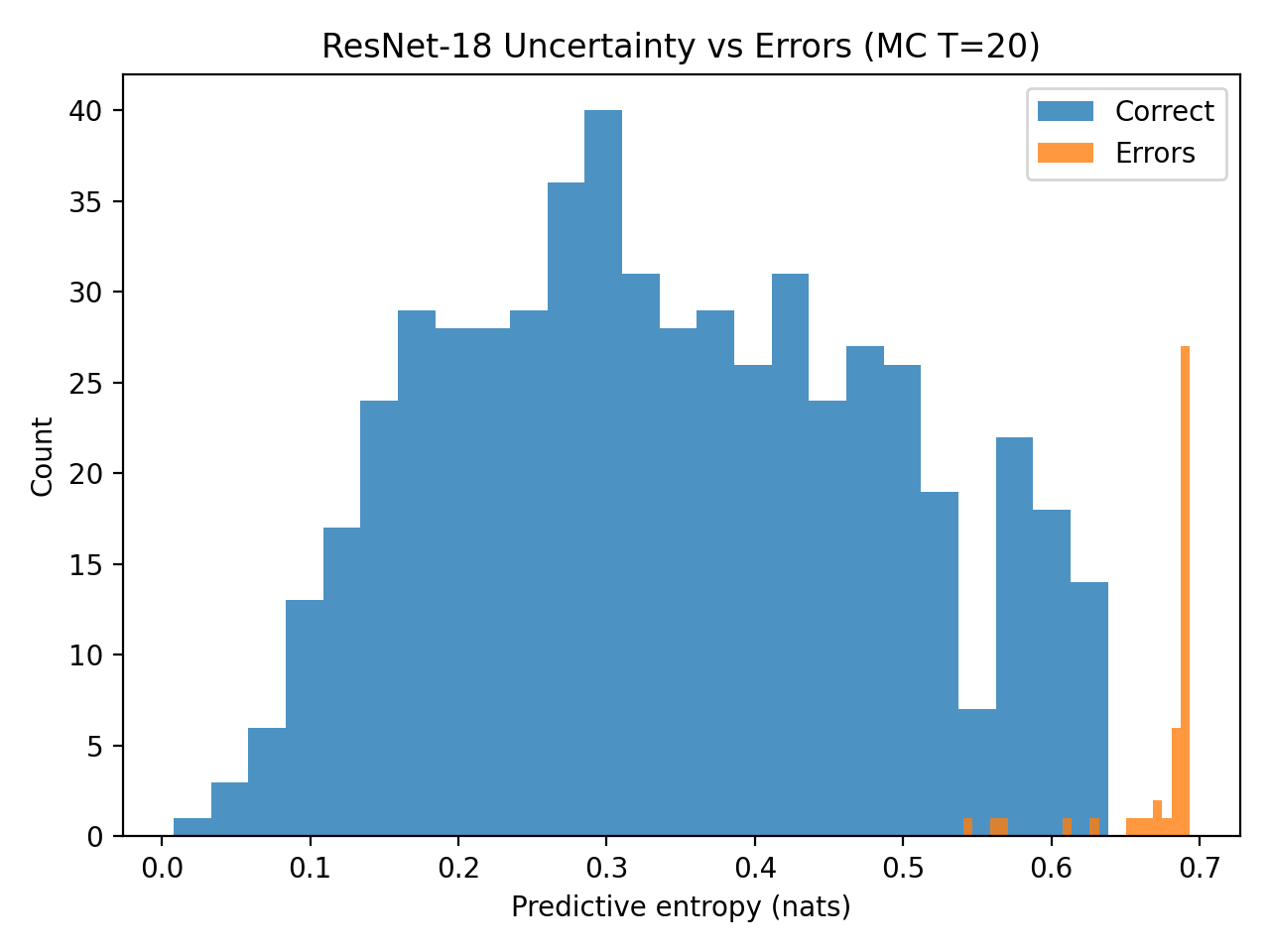
Uncertainty-aware inference techniques provide a means of quantifying the confidence level associated with a model’s prediction regarding image authenticity. This approach goes beyond simply classifying an image as real or fake by assigning a probability or confidence score to that classification. Research indicates that incorporating uncertainty estimation does not negatively impact discriminative performance; methods employing uncertainty-aware inference consistently achieve Receiver Operating Characteristic Area Under the Curve (ROC-AUC) values approaching 1.0, demonstrating that high accuracy is maintained even while providing a measure of prediction reliability. This near-saturated ROC-AUC performance confirms the viability of using uncertainty quantification without sacrificing the model’s ability to correctly identify authentic and manipulated images.
Establishing Confidence: Techniques for Reliable Inference
Model calibration addresses the mismatch between predicted probabilities and observed frequencies of correctness. Monte Carlo Dropout applies dropout during both training and inference, generating multiple predictions and averaging their probabilities to estimate uncertainty. Temperature Scaling adjusts the model’s logits by a temperature parameter, softening or sharpening the probability distribution to better reflect accuracy. Single-Pass Stochastic Inference performs a single forward pass with random noise added to the network’s weights, providing a probabilistic output without requiring multiple forward passes like Monte Carlo Dropout. These techniques aim to produce well-calibrated probabilities, where a prediction with a confidence of, for example, 90% is actually correct approximately 90% of the time.
Ensemble methods enhance uncertainty estimation by aggregating predictions from multiple independently trained models. This approach leverages the diversity of individual model errors; while each model may be prone to specific mistakes, these errors are less likely to be correlated across the ensemble. Common techniques include averaging the predicted probabilities or using a weighted average based on model performance on a validation set. The resulting aggregated prediction generally provides a more reliable estimate of uncertainty because it effectively reduces the variance of the prediction, leading to better-calibrated confidence scores and improved robustness against overfitting or noisy data.
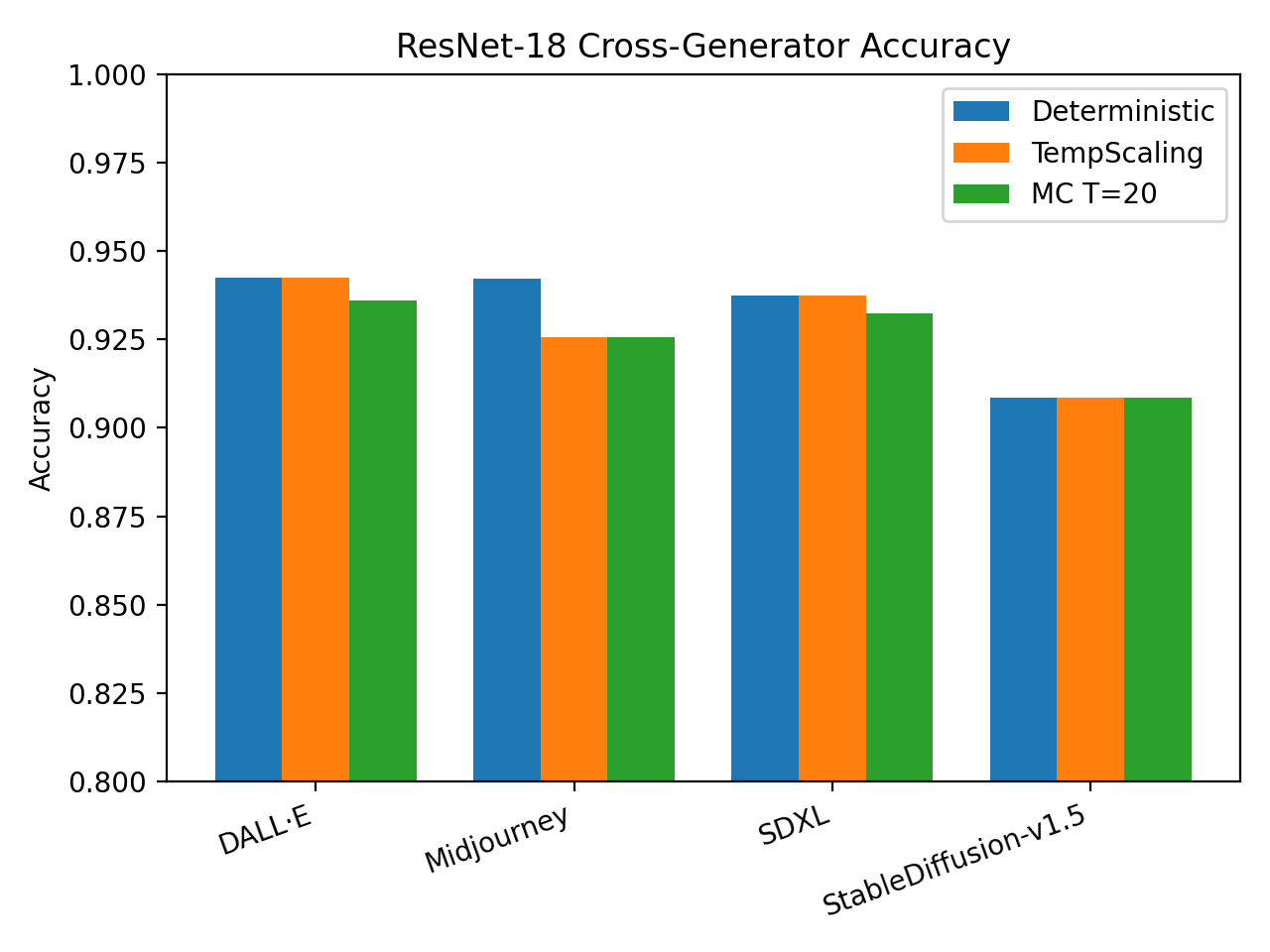
Model calibration is quantitatively assessed using metrics such as Expected Calibration Error (ECE) and Brier Score, which measure the alignment between predicted probabilities and observed frequencies of correctness. ECE calculates the average difference between a model’s predicted confidence and its actual accuracy across different confidence intervals; lower ECE values indicate better calibration. The Brier Score, conversely, measures the mean squared difference between predicted probabilities and the actual binary outcomes (0 or 1). Recent evaluations demonstrate that while certain uncertainty-aware methodologies have exhibited reductions in ECE, these improvements are not consistently observed across all tested models and datasets, and statistically significant gains have been limited, suggesting further research is needed to reliably enhance calibration performance.
Testing Resilience: Evaluating Generalization in the Real World
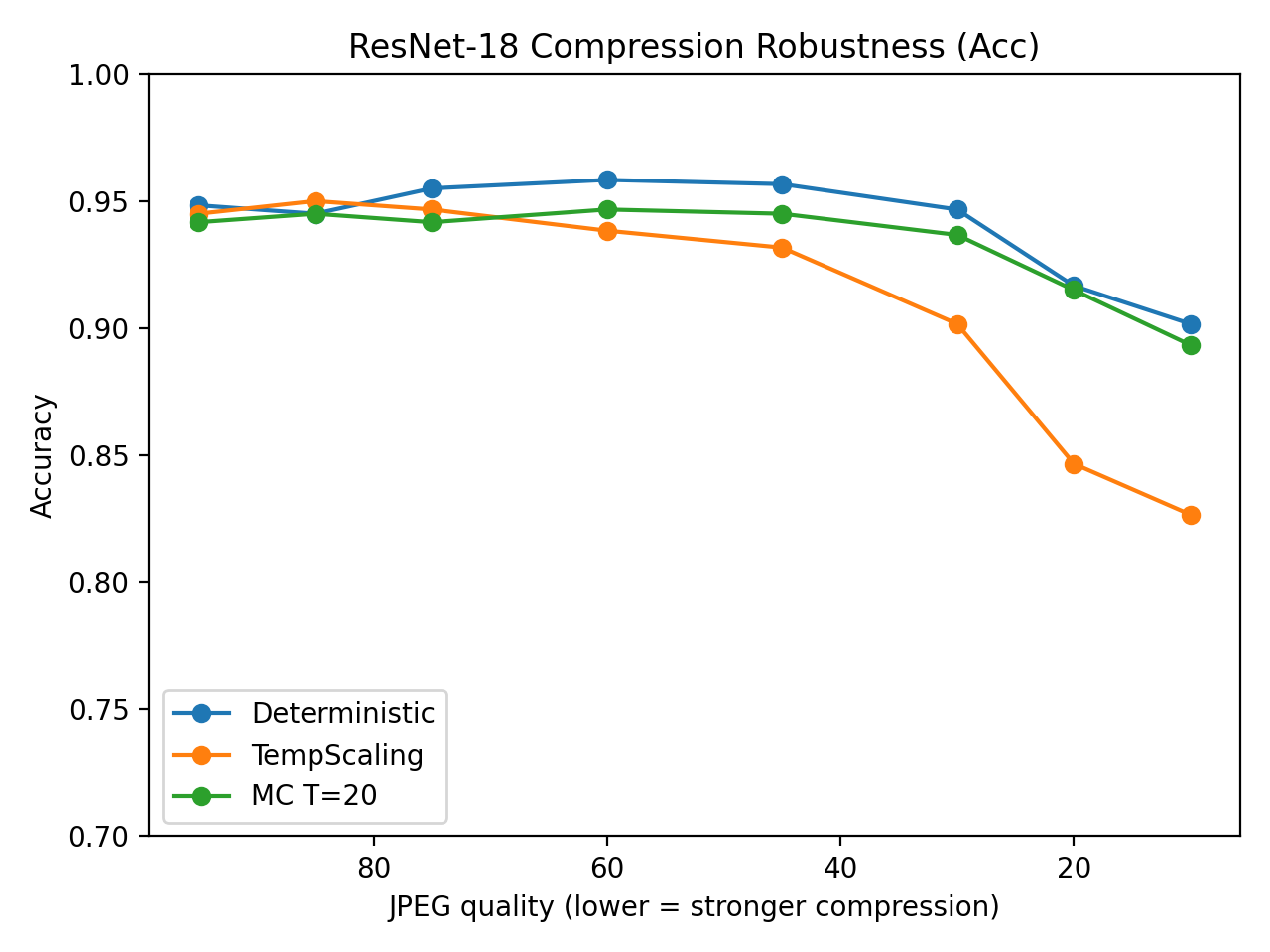
A truly robust deepfake detection system must extend beyond identifying forgeries created by known techniques; it needs to generalize to entirely new methods of manipulation. Generator-disjoint out-of-distribution (OOD) evaluation provides precisely this crucial test. This approach assesses a model’s performance on deepfakes generated by techniques not encountered during training, simulating the ever-evolving landscape of forgery creation. By withholding information about novel generation methods, researchers can rigorously determine if a detector relies on superficial artifacts specific to the training set, or if it has learned fundamental characteristics of authentic imagery that allow it to identify manipulations regardless of how they are created. Success in generator-disjoint OOD evaluation signifies a detector’s potential for long-term reliability, offering confidence that it will remain effective as deepfake technology continues to advance and become increasingly sophisticated.
Detection accuracy in deepfake identification isn’t solely determined by a model’s ability to generalize to entirely new generation methods; practical considerations such as image resolution and normalization techniques also exert a substantial influence. Studies reveal that lower resolution images can obscure subtle artifacts indicative of manipulation, hindering accurate detection, while inconsistent or absent image normalization – the process of standardizing pixel values – can introduce noise and skew results. These factors highlight the importance of preprocessing data consistently and ensuring sufficient image quality for reliable performance. Therefore, robust deepfake detection systems require not only sophisticated algorithms but also careful attention to these seemingly mundane, yet critically important, elements of the image handling pipeline.
Beyond simply classifying deepfakes as real or fake, assessing the confidence of a model’s predictions is crucial for real-world deployment. Negative Log-Likelihood (NLL) provides a quantifiable measure of this confidence, evaluating how well the probabilistic outputs align with observed data; lower NLL scores indicate higher confidence in correct classifications. Recent evaluations reveal that while Receiver Operating Characteristic Area Under the Curve (ROC-AUC) demonstrated limited statistically significant differences between models, the overlap in confidence intervals for metrics like Expected Calibration Error (ECE) and overall accuracy suggests that perceived improvements in calibration – how well a model’s stated confidence matches actual performance – were not always statistically robust. This highlights the importance of utilizing metrics like NLL to gain a more nuanced understanding of a model’s predictive quality and reliability, particularly when subtle performance gains are observed.
The pursuit of reliable deepfake detection, as detailed in this research, resembles a meticulous microscopic examination. The model isn’t simply identifying forgeries, but also quantifying its confidence in those identifications – a crucial step towards trustworthy artificial intelligence. As Geoffrey Hinton once stated, “What we’re really trying to do is build systems that can look at the world and learn from it.” This echoes the core idea of uncertainty quantification; the system doesn’t just provide a ‘yes’ or ‘no’ answer, but an assessment of its own certainty. The research highlights that such systems, when carefully calibrated, allow for selective prediction, mitigating risk by flagging instances where confidence is low, similar to a scientist acknowledging the limits of their observation.
Beyond the Likelihood Score
The pursuit of robust deepfake detection inevitably reveals a curious truth: knowing what a model predicts is often less valuable than understanding how certain it is. This work demonstrates that uncertainty quantification, while not a panacea for improving raw discriminative performance, offers a pathway toward building systems that acknowledge their limitations. The gains aren’t necessarily in identifying more deepfakes, but in avoiding costly errors when operating at high confidence – a subtle but crucial distinction. The visual patterns of uncertainty, therefore, become as important as the classifications themselves.
Future investigations should focus on refining the calibration of these uncertainty estimates. A well-calibrated system isn’t merely confident, it’s honestly confident. Beyond Monte Carlo dropout, exploring alternative methods for modeling epistemic uncertainty – Bayesian neural networks, perhaps, or ensembles with carefully designed diversity – may yield further improvements. The challenge lies in disentangling genuine uncertainty from mere noise, and translating that distinction into actionable insights.
Ultimately, the field must move beyond seeking a single “deepfake detector” and instead embrace the concept of a “risk assessor.” The question isn’t simply “is this real?” but “what is the probability this is manipulated, and what are the consequences of a misclassification?” The patterns revealed by uncertainty quantification offer a glimpse into that more nuanced future, a future where machines are not just intelligent, but also appropriately cautious.
Original article: https://arxiv.org/pdf/2602.10343.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- HoI4 fans harsh reactions to the announcement of another DLC pack
- 10 Worst End-Game Couples In Sitcom History
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
- Gold Rate Forecast
2026-02-12 15:51