Author: Denis Avetisyan
This research explores how artificial intelligence can dramatically reduce the time and effort required to diagnose and resolve issues in modern software delivery pipelines.
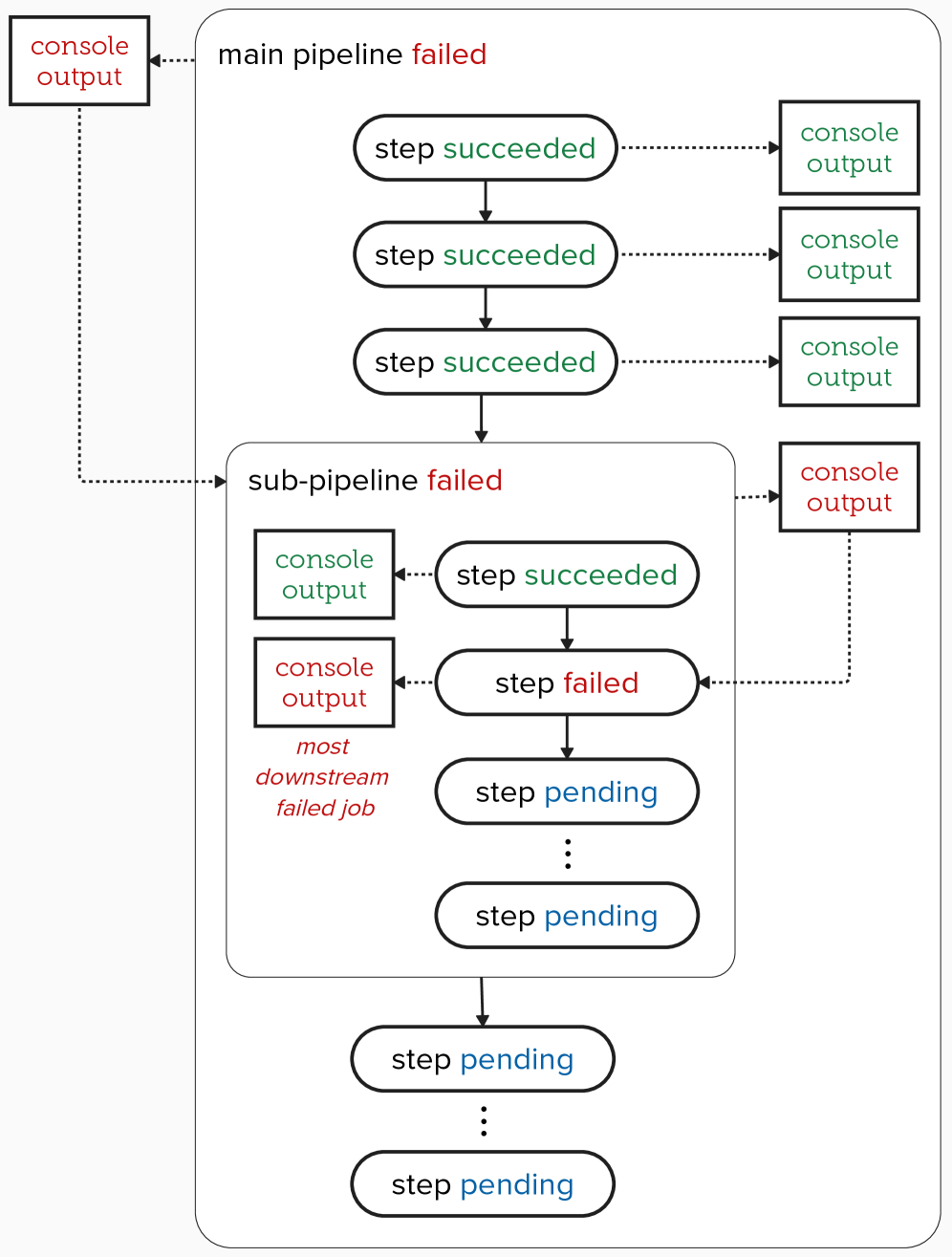
A case study demonstrates the effectiveness of large language models, augmented with historical data, for automating failure management in SAP HANA CI/CD pipelines.
Manual failure management in Continuous Integration/Continuous Delivery (CI/CD) pipelines remains a significant bottleneck despite widespread automation efforts due to the unstructured nature of diagnostic information. This paper, ‘Using Large Language Models to Support Automation of Failure Management in CI/CD Pipelines: A Case Study in SAP HANA’, investigates the potential of large language models (LLMs) to address this challenge within a complex industrial software project. Our results demonstrate that an LLM-based system, particularly when enriched with historical failure data, can accurately identify error locations and propose precise solutions in 92.1% of cases. Could this approach represent a paradigm shift towards fully autonomous CI/CD pipeline management and proactive system self-healing?
The Fragility of Velocity: Scaling CI/CD Pipelines
Contemporary software development increasingly depends on Continuous Integration and Continuous Delivery (CI/CD) pipelines to accelerate release cycles and enhance software quality. However, the very complexity that allows these pipelines to manage intricate build, test, and deployment processes also introduces significant fragility. Failures within these pipelines – stemming from code integration issues, infrastructure inconsistencies, or testing errors – are surprisingly common. These disruptions don’t just halt progress; they directly impede development velocity and jeopardize system stability, leading to delayed feature releases, increased costs, and potentially negative impacts on end-user experience. The inherent challenge lies in maintaining reliability as pipelines scale to accommodate larger codebases, more frequent deployments, and increasingly distributed teams, demanding proactive strategies for failure detection and rapid recovery.
A significant challenge in modern software delivery lies in the often-obscure nature of pipeline failures. When a continuous integration or continuous delivery process breaks down, identifying the root cause can be remarkably difficult, creating a frustrating delay in restoring functionality. This lack of immediate insight directly impacts mean time to resolution (MTTR), extending the period of instability and hindering development velocity. Unlike failures in traditional systems, pipeline issues frequently stem from intricate interactions between numerous tools and services, making it hard to pinpoint the exact source of the problem. Consequently, engineers may spend considerable time sifting through logs and tracing the execution path, rather than addressing the underlying issue and deploying fixes promptly. This opacity necessitates more sophisticated debugging and observability tools to effectively diagnose and resolve pipeline failures, ensuring a faster and more reliable software delivery process.
Conventional monitoring systems frequently fall short when applied to contemporary CI/CD pipelines due to the inherent complexity and distributed nature of these systems. These tools often treat pipeline stages as isolated entities, failing to establish crucial connections between events occurring across different stages-a build failure impacting a subsequent deployment, for instance. The sheer volume of log data generated by a typical pipeline further exacerbates the problem; while abundant, these logs remain largely unstructured and lack the necessary context for rapid diagnosis. Consequently, identifying the root cause of failures becomes a laborious process of manual log analysis, significantly extending mean time to resolution. Extracting actionable intelligence requires more than simply aggregating data; it demands a system capable of understanding the relationships between events and providing developers with a clear, concise explanation of what went wrong and how to prevent it in the future.

From Noise to Insight: Automating Failure Root Cause Analysis
Console Logs represent the foundational data source for automated failure management systems due to their comprehensive recording of events occurring within a pipeline’s execution. These logs capture a detailed chronological record of each job’s status, including start and end times, resource allocation, and any generated output or error messages. Effective extraction of meaningful information from these logs is paramount; raw log data is often unstructured and voluminous, necessitating parsing and filtering to isolate relevant indicators of failure. This data is subsequently utilized by automated systems to establish a baseline of normal operation, detect anomalies, and ultimately diagnose the root cause of pipeline failures without requiring manual log review.
Regular expressions (regex) are essential for parsing unstructured log data due to their ability to define search patterns for specific text sequences. Within pipeline logs, regex facilitates the extraction of critical information such as error codes, exception types, timestamps, and relevant parameters. By defining patterns that match common error message formats or stack trace structures, automated systems can reliably identify and isolate key indicators of failure. The precision of these regex patterns directly impacts the accuracy of subsequent failure analysis; well-defined expressions minimize false positives and ensure that only relevant log entries are flagged for further investigation. Furthermore, regex allows for the capture of contextual data surrounding the error, such as the specific input values or system state at the time of the failure, which is crucial for root cause analysis.
Automated Failure Management systems utilize data extracted from logs to identify the root cause of failures without requiring manual analysis. Recent studies indicate that Large Language Models (LLMs), when trained with historical failure data, demonstrate a high degree of accuracy in pinpointing the most downstream failed job within a pipeline; specifically, these LLMs achieved up to 98% accuracy in identifying the ultimate failure point. This capability allows for faster incident resolution and reduces the mean time to recovery by automating the process of tracing failures back to their origin.
Orchestrating the Flow: Jenkins and the Modern Pipeline
Jenkins functions as a central automation server within a CI/CD pipeline, providing the core engine for defining and executing a series of automated steps. These steps, which can include code compilation, unit testing, integration testing, static analysis, and deployment, are orchestrated as a directed acyclic graph. Jenkins supports a plugin architecture allowing integration with a wide variety of development, testing, and deployment tools. This framework enables organizations to automate the software release process, reducing manual effort, increasing release frequency, and improving software quality by providing rapid feedback on code changes. Jenkins’ capabilities extend to both simple and complex pipeline configurations, accommodating diverse software development methodologies.
The Jenkins Pipeline utilizes a Jenkinsfile, a text file written in Groovy, to define the entire automated workflow as code. This approach allows pipelines to be treated as infrastructure, enabling version control using systems like Git. Storing pipeline definitions in version control facilitates auditing, rollback capabilities, and collaborative development of the CI/CD process. Changes to the pipeline are then tracked, reviewed, and deployed like any other application code, ensuring consistency and reproducibility across environments. The Jenkinsfile specifies the stages and steps involved in building, testing, and deploying applications, defining dependencies and configurations programmatically.
Remote Pipelines in Jenkins facilitate modularity by allowing a Jenkinsfile to trigger another Jenkins pipeline on a different Jenkins master, effectively distributing the overall workload. This is achieved through the ‘pipeline’ step within a Jenkinsfile, specifying the target Jenkins instance and pipeline name. Downstream Pipelines build upon this concept by enabling a pipeline to trigger other pipelines within the same Jenkins instance, creating a dependency graph of tasks. Both approaches improve scalability by parallelizing execution across multiple Jenkins masters or nodes and enhance resilience; failure of a single pipeline does not necessarily halt the entire process, as dependent pipelines can potentially continue if designed to handle such scenarios. These features support complex workflows by breaking them down into manageable, reusable components.
Integration with code review tools such as Gerrit enables CI/CD pipelines to dynamically respond to review status. Upon detection of a code review failure – indicated by a negative review, unresolved comments, or lack of approval – the pipeline execution is immediately terminated. This prevents the build process from continuing with potentially flawed or unapproved code. The pipeline then provides feedback to developers, typically through Gerrit itself, indicating the reason for the failure and directing them to address the review comments before triggering a subsequent build. This tight coupling ensures code quality and adherence to established review processes are enforced as part of the automated pipeline.
Toward Robustness: A Hybrid Approach to Failure Management
A truly resilient software delivery pipeline hinges on a Hybrid Failure Management System, one that strategically blends the predictability of rule-based automation with the analytical power of Large Language Models. Traditional automation excels at handling known failure scenarios, swiftly executing pre-defined responses. However, modern CI/CD pipelines are dynamic, frequently encountering novel issues that demand more nuanced understanding. This is where LLMs prove invaluable, leveraging historical data and contextual awareness to diagnose and resolve failures beyond the scope of static rules. By combining these strengths, organizations can achieve a more adaptive and robust system, minimizing downtime and accelerating recovery from both anticipated and unforeseen incidents. The hybrid approach doesn’t replace existing automation, but augments it, creating a self-improving system capable of handling increasingly complex challenges within the software delivery lifecycle.
A robust failure management strategy hinges on meticulously crafted Failure Management Instructions, serving as a unified guide for both automated systems and human operators. These instructions aren’t simply troubleshooting steps; they represent a codified understanding of potential failures, their root causes, and pre-approved remediation pathways. By detailing expected behaviors and outlining precise responses, organizations ensure consistency in handling incidents, reducing the risk of misdiagnosis and prolonged downtime. The instructions detail not only what to do, but also when to escalate to manual intervention, creating a seamless handover between automation and expert analysis. This clarity streamlines the recovery process, minimizing the impact of failures on critical systems and fostering a more resilient software delivery pipeline.
The integration of critical infrastructure, such as SAP HANA, into Continuous Integration and Continuous Delivery pipelines necessitates exceptionally robust reliability and automated recovery mechanisms. Recent analysis demonstrates the significant impact of historical data on the efficacy of Large Language Models in failure resolution; when equipped with past records, these models correctly identified solutions for up to 7070 out of 7676 failures. However, performance dropped considerably-to only 5050 correct solutions-when historical data was unavailable. This substantial difference underscores the necessity of a hybrid failure management system, leveraging both traditional automation and the intelligent capabilities of LLMs informed by comprehensive historical data, to minimize disruption and maintain pipeline stability.
Organizations striving for resilient software delivery can significantly minimize downtime and accelerate recovery through a combined approach to failure management. This strategy leverages the precision of rule-based automation alongside the analytical capabilities of large language models. Studies demonstrate a consistent ability to pinpoint the root cause of failures – with a standard deviation of just 0.07 when applying domain knowledge – enabling rapid intervention and reducing the impact on critical systems. This hybrid system doesn’t simply react to issues; it proactively enhances the stability of the entire software delivery pipeline, leading to improved reliability and a more efficient development lifecycle.
The pursuit of automated failure management, as detailed in this study, echoes a fundamental principle of computer science: the importance of provable correctness. It’s not merely about achieving a functional outcome, but about establishing a system’s reliability through rigorous analysis and predictable behavior. Donald Knuth aptly stated, “Premature optimization is the root of all evil.” This sentiment aligns with the paper’s findings; LLMs, when grounded in historical failure data, move beyond superficial fixes to address the underlying causes of errors. The study demonstrates that automation isn’t simply about speed, but about building a more robust and demonstrably correct CI/CD pipeline, mirroring the mathematical elegance Knuth champions.
What’s Next?
The demonstrated utility of large language models within CI/CD failure management, while promising, merely scratches the surface of a deeper, and predictably complex, challenge. The current approach, reliant on historical records, inherently limits the system’s capacity to address genuinely novel failures-those not previously encountered within the training data. To claim automation is to invite scrutiny; a truly robust system demands a capacity for deductive reasoning, not simply pattern matching against past events. The elegance of a provable solution remains elusive.
Future work must address the inherent limitations of inductive learning. Augmenting LLMs with formal methods-perhaps integrating constraint satisfaction or automated theorem proving-offers a potential, though computationally demanding, path forward. It is tempting to chase ever-larger datasets, but optimization without analysis is self-deception. The real measure of progress lies not in the quantity of data consumed, but in the precision with which the system can generalize beyond it.
Ultimately, the aspiration should not be merely to automate the response to failure, but to actively prevent it. Integrating LLMs with formal verification tools, and employing them to analyze code for potential vulnerabilities before deployment, represents a far more ambitious, and intellectually satisfying, objective. The pursuit of such a system will demand a rigorous mathematical foundation, and a willingness to abandon the illusion that ‘working on tests’ constitutes genuine validation.
Original article: https://arxiv.org/pdf/2602.06709.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
- EUR USD PREDICTION
2026-02-09 18:51