Author: Denis Avetisyan
Researchers have developed a hybrid verification method that significantly speeds up the process of ensuring neural network reliability and safety.
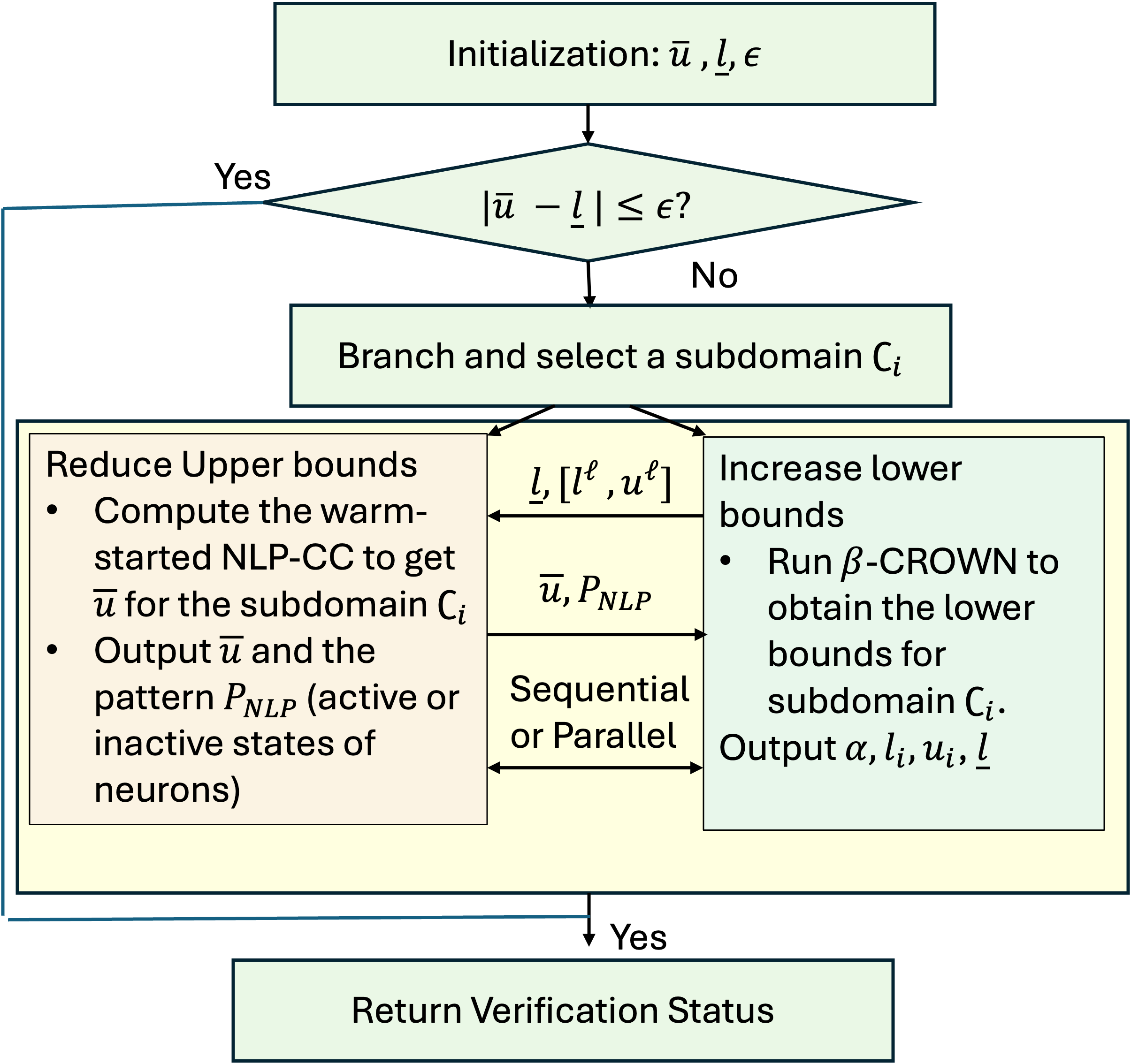
The technique combines tight upper bounds from nonlinear programming with lower bounds from bound propagation and pattern-aware branching to achieve scalable ε-global verification.
Despite strong empirical performance, the deployment of neural networks in safety-critical applications remains limited by concerns regarding robustness and the scalability of formal verification methods. This paper introduces ‘E-Globe: Scalable ε-Global Verification of Neural Networks via Tight Upper Bounds and Pattern-Aware Branching’, a novel hybrid verifier that efficiently tightens both upper and lower bounds within a branch-and-bound framework to achieve robust ε-global certification. By leveraging a complementarity-constrained nonlinear program to rapidly prune unsafe regions and employing pattern-aligned branching, E-Globe significantly accelerates verification and achieves markedly tighter bounds than existing methods. Could this approach unlock broader deployment of neural networks in domains demanding guaranteed robustness and reliability?
Fragile Foundations: The Illusion of Robustness in Neural Networks
Despite remarkable achievements in areas like image recognition and natural language processing, neural networks demonstrate a surprising fragility. These systems, while capable of high-level reasoning, can be easily fooled by subtly altered inputs – known as adversarial perturbations. These alterations, often imperceptible to humans, can cause a network to misclassify data with high confidence, raising significant safety concerns in applications like self-driving cars and medical diagnosis. The vulnerability stems from the high-dimensional and non-linear nature of these networks, creating “blind spots” where small changes in the input space can lead to drastically different outputs. This susceptibility isn’t a matter of simply improving training data; it’s a fundamental property of how these networks currently learn and generalize, demanding new approaches to ensure reliable performance in real-world scenarios.
Establishing the robustness of a neural network hinges on identifying the global optimal solution to a complex optimization problem defined across its entire input space. This isn’t simply finding a solution, but proving that no other input, even one subtly altered, will cause the network to misclassify. The computational cost of this verification escalates dramatically with network size and input dimensionality; each additional neuron and input feature expands the search space exponentially. Consequently, exhaustive searches become impractical, forcing researchers to rely on approximations and sampling techniques. These methods, while faster, introduce uncertainty – a network might appear robust based on limited testing, but remain vulnerable to adversarial examples carefully crafted to exploit undiscovered weaknesses. This inherent trade-off between computational feasibility and guaranteed safety presents a significant hurdle in deploying reliable and trustworthy artificial intelligence systems.
The increasing sophistication of neural networks, while enabling remarkable advancements in areas like image recognition and natural language processing, presents significant challenges to traditional verification and optimization techniques. Methods designed for smaller, simpler models often falter when applied to the high-dimensional input spaces and millions of parameters characteristic of modern architectures. Exhaustively searching for the worst-case adversarial perturbation-the input that maximizes prediction error-becomes computationally intractable, as the search space grows exponentially with input dimensionality. Consequently, existing tools frequently rely on approximations or simplifications, potentially overlooking vulnerabilities and failing to provide the strong robustness guarantees demanded by safety-critical applications. This scalability bottleneck necessitates the development of novel algorithms and methodologies specifically tailored to handle the immense scale and complexity inherent in contemporary neural network designs.
Pinpointing the Limits: Establishing Network Boundaries
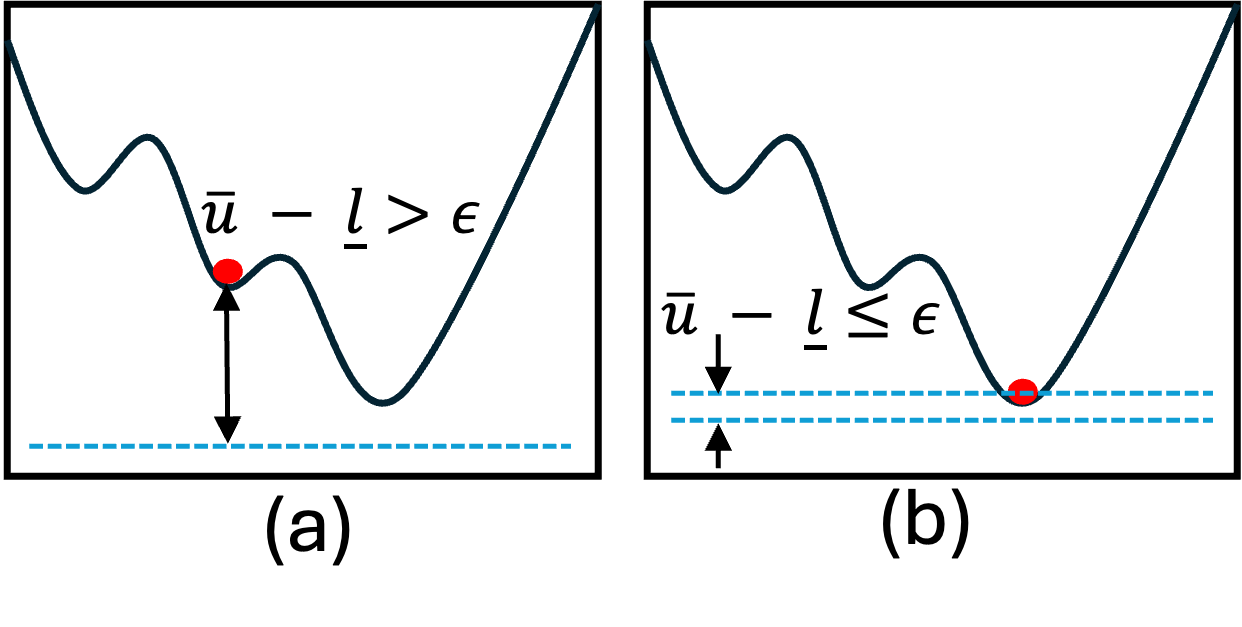
Network verification fundamentally relies on determining the definitive range of possible outputs a neural network will produce given a specific input range. This is achieved by establishing both lower bounds and upper bounds on the network’s output. A lower bound represents the minimum possible value the output can take, while an upper bound represents the maximum. The difference between these bounds defines the certified robustness region; a tighter bound difference indicates a more precise understanding of the network’s behavior. Establishing these bounds allows for formal guarantees about the network’s response to various inputs, which is critical for safety-critical applications. The process involves propagating input ranges through the network’s layers and accounting for the effects of each operation to determine the extreme values of the output.
Relaxation-based methods compute certified lower bounds on network output by reformulating the original non-linear problem into a more tractable, typically linear, approximation. This process introduces relaxation – replacing strict constraints with less restrictive ones – enabling the use of efficient solving techniques like linear programming. However, this relaxation inherently introduces a degree of imprecision; the resulting lower bound is often a conservative estimate, meaning it may significantly underestimate the true minimum value. While these methods provide a provable lower bound, the trade-off is a potential loss of accuracy, as the relaxation can widen the gap between the computed bound and the actual network output. The degree of conservatism is dependent on the specific relaxation technique employed and the network architecture.
CROWN, α-CROWN, and β-CROWN are iterative methods for computing certified lower bounds on the output of deep neural networks. These techniques function by propagating interval bounds through the network’s layers, tracking the range of possible values at each neuron. CROWN utilizes a linear relaxation of the network, providing a computationally efficient, though potentially conservative, lower bound. Successive iterations, as implemented in α-CROWN and β-CROWN, refine these bounds by incorporating tighter relaxations and leveraging information about the network’s structure, particularly the signs of weights. This propagation continues until a fixed point is reached, yielding a certified lower bound on the network’s output for a given input range, and enabling verification of robustness properties.
The NLP-CC (Non-Linear Programming with Complementarity Constraints) method computes tight upper bounds on network output by formulating the problem as a mixed-integer linear program. This approach exploits the properties of ReLU activation functions, which are piecewise linear, and introduces complementarity constraints to model the inactive regions of these functions. By solving this optimization problem, NLP-CC can determine an upper bound on the network’s output with a guaranteed gap of less than 0.005, offering a precise characterization of the network’s behavior. This precision is achieved through a systematic exploration of the network’s decision boundaries, enabling the computation of a tight, verifiable upper bound.
The necessity of relaxation-based and complementarity constraint methods stems from the computational limitations of traditional network verification techniques. Methods such as interval bound propagation or abstract interpretation, while theoretically sound, exhibit exponential scaling with network size and complexity. This results in verification times that are orders of magnitude slower-often rendering them impractical for all but the smallest neural networks. In contrast, techniques like CROWN, α-CROWN, β-CROWN, and NLP-CC provide significantly improved scalability by leveraging specific mathematical properties and approximations, enabling verification of larger, more complex networks within reasonable timeframes. This performance gain is crucial for applying formal verification to real-world applications of neural networks.
E-Globe: A Pragmatic Hybrid for Efficient Verification
E-Globe is a novel verification approach that integrates the strengths of two established techniques: NLP-CC and β-CROWN. NLP-CC (Non-Linear Programming with Constraint Conditioning) provides tight upper bounds on the network’s output, effectively narrowing the range of possible values. Conversely, β-CROWN delivers precise lower bounds by employing a linear relaxation technique based on interval bound propagation and constraint tightening. By combining these upper and lower bound calculations, E-Globe achieves a more accurate and efficient verification process than relying on either method in isolation. This hybrid formulation allows for a tighter bounding of the network’s reachable set, which is critical for determining robustness and safety properties.
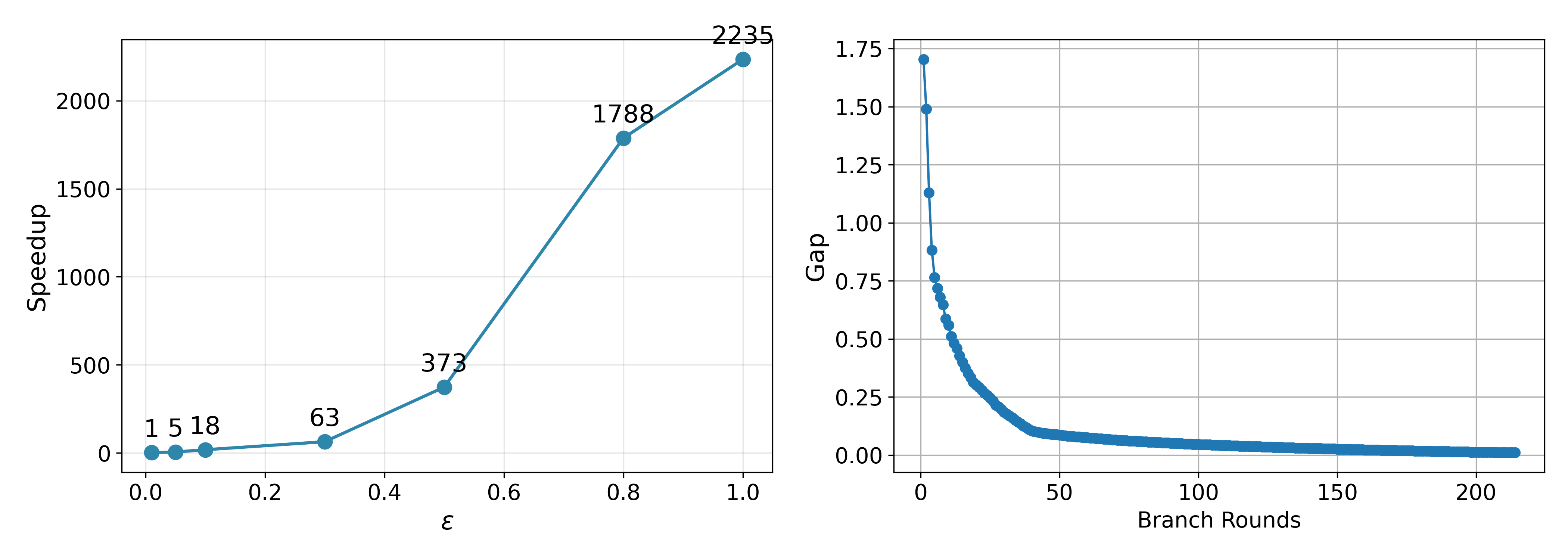
E-Globe demonstrates a substantial performance improvement over Mixed Integer Programming (MIP)-based verifiers, achieving speedups ranging from 100x to 1000x – representing two to three orders of magnitude. This accelerated verification process is critical for handling the increasing size and complexity of modern neural networks. The enhanced speed directly translates to improved scalability, allowing E-Globe to certify networks that are computationally intractable for traditional MIP-based methods. This performance gain is achieved through the synergistic combination of upper and lower bound techniques, alongside optimization strategies like warm-starting and pattern-aligned branching.
To improve verification speed, E-Globe utilizes Warm-Start techniques which preserve and reuse information computed during prior iterations of the verification process. Specifically, solutions obtained from analyzing a network with a given property are used as initial values for subsequent analyses, even if those analyses involve modified network parameters or different target properties. This avoids redundant computation and accelerates convergence, as the solver begins its search from a more informed starting point rather than a completely random initialization. The effectiveness of Warm-Start is particularly pronounced when verifying a series of related properties or when fine-tuning a network, allowing for significant computational savings.
Pattern-Aligned Strong Branching within E-Globe is a search strategy designed to efficiently explore the solution space during verification. This technique utilizes the Karush-Kuhn-Tucker (KKT) conditions – a set of necessary conditions for optimality in mathematical programming – to guide the branching process. Specifically, the KKT conditions are used to identify promising regions of the search space that are more likely to contain a feasible solution, thereby prioritizing those branches. This intelligent exploration, aligned with the network’s activation patterns, significantly reduces the number of nodes that need to be explored, leading to a more efficient verification process compared to naive branching strategies.
The E-Globe verification framework achieves a substantial reduction in model size during the Mixed Integer Programming (MIP) formulation process. By leveraging techniques such as Pattern-Aligned Strong Branching and incorporating knowledge from the Karush-Kuhn-Tucker (KKT) conditions, the number of binary variables required to represent the neural network is decreased by up to 25 times compared to a standard MIP formulation. This reduction directly translates to lower computational complexity and memory requirements, enabling verification of larger and more complex neural network architectures that would otherwise be intractable with conventional MIP-based methods.
The combination of NLP-CC upper bounds, β-CROWN lower bounds, Warm-Start techniques, and Pattern-Aligned Strong Branching within E-Globe facilitates the certification of neural networks with significantly increased size and complexity. Traditional methods, particularly those reliant on Mixed Integer Programming (MIP), experience scalability limitations as network dimensions grow due to the exponential increase in binary variables and computational demands. E-Globe mitigates these limitations by reducing the number of binary variables – by up to 25x – and achieving speedups of two to three orders of magnitude. This efficiency allows for the reliable verification of networks previously intractable for formal methods, expanding the applicability of robust AI certification to more realistic and challenging scenarios.
The pursuit of perfect robustness certification, as detailed in this work on scalable ε-global verification, feels a bit like chasing a phantom. This paper diligently refines bounds and branching strategies, attempting to tame the exponential complexity of neural network analysis. It’s a noble effort, tightening upper bounds with nonlinear programming and leveraging activation patterns to prune the search space. However, one suspects even the most elegant verification framework will eventually succumb to the realities of production deployments. As Carl Friedrich Gauss observed, “If other mathematicians had not already invented these methods, I would have been forced to do so.” The same rings true here; each advancement in verification merely postpones the inevitable accumulation of tech debt, as models evolve and new vulnerabilities emerge. The goal isn’t to solve robustness, but to continually delay its inevitable unraveling.
What’s Next?
This pursuit of tighter bounds and clever branching strategies feels…familiar. The authors demonstrate performance gains, certainly, but one suspects production networks will inevitably find a way to stress-test these optimizations into oblivion. It’s the usual story: a beautiful theory, painstakingly implemented, then promptly undermined by the sheer, chaotic complexity of real-world data. The reduction in search space is commendable, but the fundamental problem remains: verifying even moderately sized networks is an exercise in computational endurance.
The integration of NLP upper bounds with bound propagation techniques is a logical step, though it begs the question of whether this hybrid approach simply shifts the bottleneck. One anticipates diminishing returns as network architectures grow more exotic. Perhaps the real breakthrough won’t be in refining existing methods, but in fundamentally rethinking what ‘verification’ even means in the context of increasingly opaque models.
Ultimately, this work feels less like a solution and more like a sophisticated wrapper around the inherent intractability of the problem. The authors have undoubtedly pushed the state-of-the-art, but one suspects future research will reveal this, too, was merely the old thing with worse docs.
Original article: https://arxiv.org/pdf/2602.05068.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- Infinity Nikki Candlelight Reverie Challenge and Rewards Guide
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
- 币安人生 PREDICTION. 币安人生 cryptocurrency
2026-02-08 17:46