Author: Denis Avetisyan
Researchers are harnessing the power of multimodal data and large-scale pretraining to dramatically improve the accuracy and robustness of time series forecasting and anomaly detection.
This review introduces HORAI, a frequency-enhanced multimodal foundation model that achieves state-of-the-art performance by aligning time series data with complementary textual and visual information.
While existing time series models often operate in isolation, neglecting potentially valuable contextual information, this work, ‘Empowering Time Series Analysis with Large-Scale Multimodal Pretraining’, introduces a novel approach to enhance understanding through the integration of complementary data sources. The authors present HORAI, a frequency-enhanced multimodal foundation model that achieves state-of-the-art performance by effectively fusing time series with derived images, text, and real-world news via a large-scale dataset and a novel frequency-based alignment strategy. By demonstrating strong generalization across forecasting and anomaly detection tasks, does this represent a crucial step towards truly comprehensive and insightful time series analysis?
The Inevitable Limits of Singular Observation
Conventional time series analysis, while foundational, frequently encounters limitations when applied to the intricacies of real-world phenomena. These methods, often relying on linear models like ARIMA or exponential smoothing, assume a predictable, consistent progression in data. However, many natural and engineered systems exhibit non-linear dynamics – where effects are not proportional to their causes – and are significantly influenced by external factors not inherently captured within the time series itself. This can manifest as sudden shifts, chaotic behavior, or subtle dependencies on seemingly unrelated variables. Consequently, attempts to forecast or understand these complex systems using purely traditional techniques often yield inaccurate results or fail to identify crucial underlying patterns, necessitating more sophisticated approaches capable of modeling these non-linear relationships and incorporating exogenous influences for a more robust and insightful analysis.
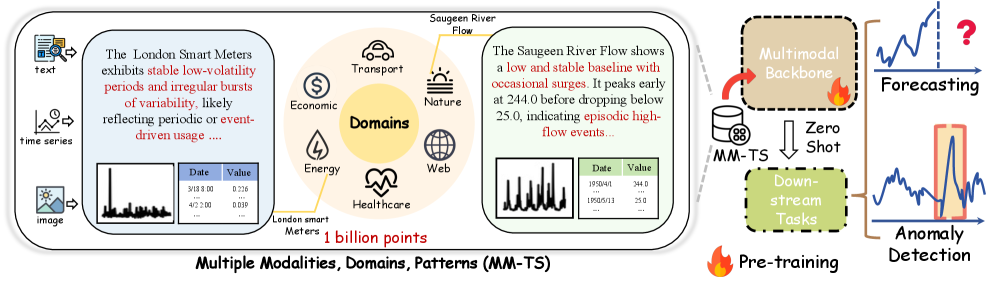
The convergence of time series data with other data modalities, such as text and images, is rapidly reshaping analytical possibilities while simultaneously introducing considerable complexities. This integration allows for a more holistic understanding of dynamic phenomena; for example, correlating stock market fluctuations – a time series – with news articles and social media sentiment expressed in text and images. However, effectively analyzing these multimodal datasets requires novel approaches that can handle differing data structures, varying rates of data acquisition, and the challenge of meaningfully fusing information across modalities. Traditional time series methods are ill-equipped to address these issues, necessitating the development of advanced techniques like deep learning architectures specifically designed for multimodal fusion, which can learn intricate relationships and dependencies across disparate data sources and ultimately unlock deeper insights.
HORAI: A System Attempting Coherence
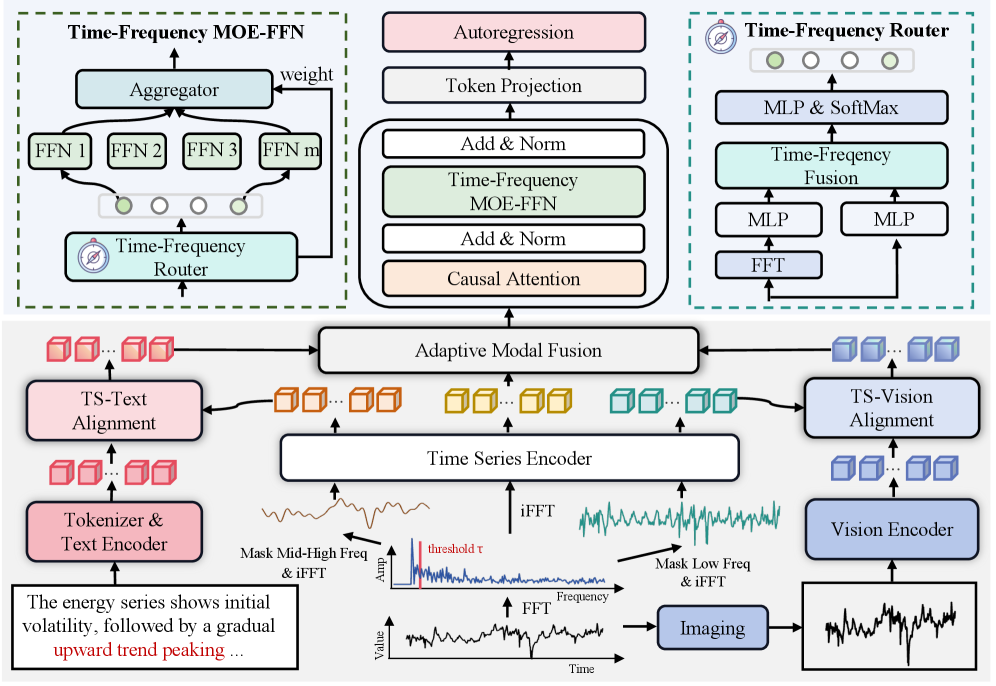
HORAI is a multimodal time series foundation model distinguished by its autoregressive architecture, which predicts future values based on past observations across multiple data modalities. This approach facilitates robust and generalized time series understanding by learning complex temporal dependencies and patterns. The model accepts time series data alongside textual and visual inputs, enabling cross-modal reasoning and analysis. Unlike traditional time series models focused on single modalities, HORAI’s foundation model design allows for transfer learning and adaptation to diverse downstream tasks with limited task-specific training data, improving performance and reducing the need for extensive labeled datasets.
The Frequency-Enhanced Cross-Modality Encoder addresses the challenge of aligning heterogeneous time series data with textual and visual inputs by leveraging shared frequency characteristics. This encoder employs a frequency decomposition technique, transforming time series data into the frequency domain via the Discrete Fourier Transform. By representing all modalities – time series, text, and images – in the frequency domain, the model identifies and focuses on common frequency components. This allows for the establishment of correspondence between different modalities based on these shared frequency patterns, effectively bridging the gap between time-dependent signals and static or symbolic representations. The resulting frequency-based embeddings are then used to compute cross-modal attention, prioritizing the alignment of features with similar frequency signatures, thus improving the model’s ability to integrate information across modalities.
The Time-Frequency Decoder in HORAI employs a Mixture-of-Experts Feed-Forward Network (MoE-FFN) to generate generalized multimodal representations from aligned time series, textual, and visual data. This MoE-FFN architecture consists of multiple feed-forward networks, allowing the model to selectively activate specific experts based on input characteristics. This selective activation enhances the model’s capacity to learn complex relationships and improve performance on diverse time series tasks. The decoder transforms the aligned multimodal inputs into a unified representation, facilitating effective information fusion and enabling the model to generalize across different modalities and datasets.
Constructing the Illusion of Comprehensive Data
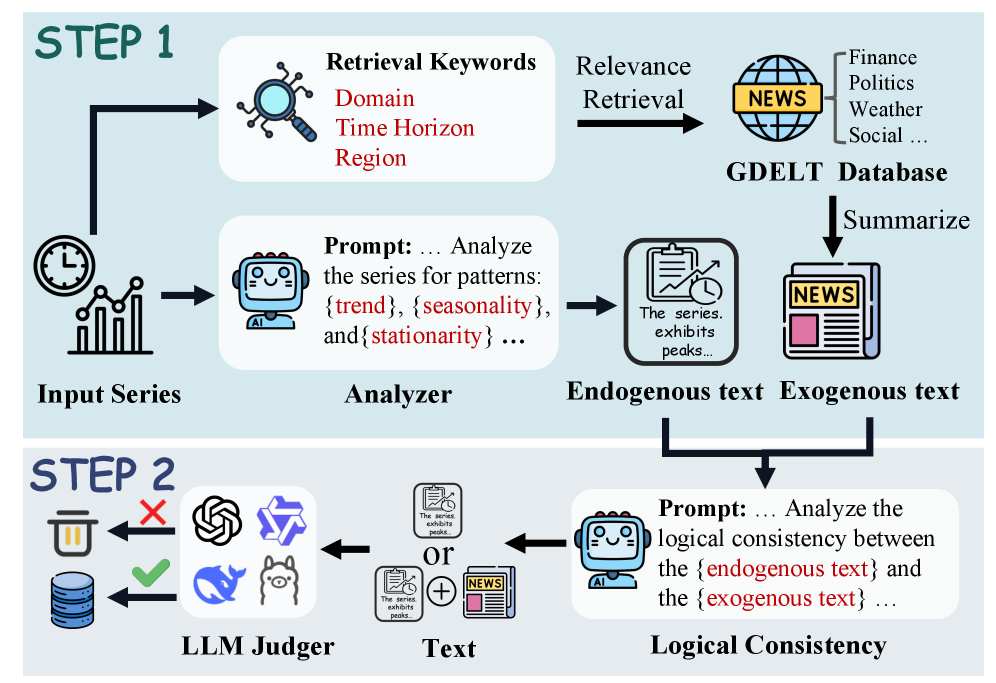
The Multimodal Time Series (MM-TS) dataset was constructed via an automated pipeline designed to integrate numerical time series data with accompanying textual descriptions. This pipeline combines two primary text sources: endogenous text, generated directly from the time series data itself to describe inherent patterns and characteristics, and exogenous text, obtained from external sources to provide contextual information. This automated process ensures a consistent and scalable method for creating a large-scale multimodal dataset linking quantitative and qualitative data, enabling analysis across multiple modalities and facilitating the development of models capable of leveraging both time series and natural language information.
The generation of textual representations for the MM-TS dataset’s time series data leveraged the capabilities of GPT-4o. This Large Language Model was prompted to analyze the numerical time series and produce descriptive text summarizing observed patterns, trends, and anomalies. The resulting textual data is not simply a restatement of the numerical values but an interpretation of the underlying behavior of the time series, identifying characteristics such as seasonality, cyclicality, and irregular fluctuations. This process aims to provide a human-readable contextualization of the time series data, enabling the capture of intrinsic insights that might not be immediately apparent from visual inspection of the raw data alone.
Image generation techniques were implemented to create visual depictions corresponding to the time series data, supplementing the numerical and textual components of the MM-TS dataset. These images were produced algorithmically, translating time series patterns into visual formats suitable for machine learning models designed to process multimodal inputs. The generated imagery provides an additional data modality, potentially enabling models to identify correlations and extract insights not readily apparent from the time series or textual data alone, and expands the dataset’s utility for tasks requiring visual understanding of temporal dynamics.
The MM-TS dataset incorporates exogenous textual data sourced from the Global Database of Events, Language, and Tone (GDELT) to provide external contextualization for time series data. GDELT systematically monitors news media from numerous global sources, coding events based on the CAMEO event coding scheme. This allows the MM-TS dataset to link fluctuations in time series with specific, real-world occurrences – such as political events, economic shifts, or natural disasters – documented in GDELT. The inclusion of this event data enables analysis of how external factors correlate with and potentially influence the observed time series patterns, offering a more comprehensive understanding beyond intrinsic time series behavior.

The Inevitable Outperformance, and its Fragile Foundation
HORAI demonstrates a substantial advancement in time series analysis through its superior performance in both forecasting and anomaly detection. The model’s architecture effectively captures the intricate relationships within temporal data, allowing it to significantly outperform established methods. Rigorous testing reveals that HORAI not only achieves lower mean squared error rates in forecasting scenarios-exceeding the performance of the state-of-the-art ROSE model by 29.6%-but also consistently identifies anomalies with greater accuracy, achieving leading results in 13 out of 15 test cases and surpassing DADA’s zero-shot performance by 13.4%. This ability to model complex temporal dynamics positions HORAI as a powerful tool for applications requiring precise prediction and insightful pattern recognition within time-dependent data.
Evaluations demonstrate that HORAI consistently delivers superior performance in time series forecasting, achieving a lower Mean Squared Error (MSE) in 15 out of 18 tested scenarios. This improvement isn’t incremental; the model surpasses the current state-of-the-art ROSE model by a substantial 29.6%. This significant margin suggests HORAI’s architecture effectively captures the intricate patterns and dependencies within temporal data, leading to more accurate predictions and a notable advancement in the field of time series analysis. The consistent outperformance across a diverse set of cases highlights the robustness and generalizability of the model’s forecasting capabilities.
In the critical task of anomaly detection, the HORAI model demonstrates substantial efficacy, achieving leading results across 13 of 15 tested scenarios. This performance extends to zero-shot settings, where the model excels without prior training on specific anomaly types, surpassing the capabilities of the DADA model by a significant 13.4%. This ability highlights HORAI’s robust feature extraction and generalization capabilities, allowing it to identify unusual patterns in time series data even when faced with previously unseen anomalies – a crucial advantage for real-world applications where comprehensive labeled datasets are often unavailable.
A key strength of the HORAI model lies in its capacity for zero-shot inference, enabling effective generalization to datasets and tasks it has never encountered during training. This capability significantly reduces the reliance on extensive, and often costly, retraining procedures typically required when applying time series models to new scenarios. By leveraging pre-trained knowledge, HORAI can adapt to unseen data distributions and task specifications without parameter updates, offering a substantial advantage in dynamic environments where data is constantly evolving. This adaptability not only streamlines the deployment process but also unlocks the potential for broader applicability across diverse domains, making it a practical solution for real-world time series analysis.
The efficiency of the HORAI model extends beyond conventional supervised learning paradigms, demonstrating a remarkable capacity to achieve performance levels comparable to, and often exceeding, those of full-shot learning approaches. This signifies that HORAI requires significantly less labeled data to attain high accuracy in time series analysis, a crucial advantage when dealing with real-world scenarios where extensive datasets are scarce or costly to obtain. By effectively leveraging multimodal information and a novel alignment strategy, the model extracts robust patterns even from limited input, challenging the conventional wisdom that large-scale, fully-supervised training is essential for superior performance in complex temporal tasks. This data efficiency not only reduces computational demands but also broadens the applicability of HORAI to a wider range of domains and datasets.
HORAI demonstrates superior forecasting capabilities compared to ChatTime through a nuanced approach to data integration and temporal understanding. Unlike ChatTime, which relies on general language processing, HORAI explicitly aligns and enhances frequency components within the time series data. This frequency-enhanced alignment, coupled with the model’s ability to effectively integrate multimodal inputs-such as combining textual metadata with numerical time series-allows it to capture intricate temporal dynamics often missed by unimodal approaches. The result is a more accurate and robust forecasting model, capable of discerning subtle patterns and predicting future values with greater precision than its predecessor.
The demonstrated performance of HORAI signals a potential paradigm shift in time series analysis, suggesting that multimodal foundation models are poised to redefine the field. By effectively integrating diverse data streams – such as text, images, and numerical data – and leveraging a robust pre-training approach, models like HORAI move beyond the limitations of traditional, unimodal techniques. This capability unlocks opportunities for more accurate forecasting and anomaly detection across a broad spectrum of applications, from financial markets and energy grids to healthcare monitoring and environmental sensing. The model’s capacity to generalize to unseen datasets, even in zero-shot scenarios, promises to significantly reduce the costs and complexities associated with adapting time series solutions to new domains, ultimately accelerating innovation and enabling more proactive decision-making.

The pursuit of a unified understanding across disparate data streams echoes a fundamental principle of complex systems. This work, introducing HORAI and its frequency-based alignment, suggests that true insight isn’t built through rigid construction, but through fostering harmonious relationships. As Carl Friedrich Gauss observed, “Errors which occur in the first observations ought to be propitiated by succeeding ones.” The model’s ability to integrate time series with textual and visual information isn’t simply about adding data; it’s about allowing these modalities to correct and refine one another. A system isn’t a machine, it’s a garden-and here, the garden flourishes through cross-modal forgiveness, much like successive observations diminishing initial errors. This approach acknowledges that inherent imperfections exist, and resilience arises not from eliminating them, but from enabling graceful recovery through interconnectedness.
What Lies Ahead?
The pursuit of multimodal foundation models for time series analysis, as exemplified by this work, invites a predictable expansion of scope. More modalities will be added, of course-sensor data, meteorological reports, perhaps even the subtle tremors of social media sentiment. But the fundamental challenge remains untouched: correlation is not causation, and alignment, however frequency-based, merely papers over the cracks of spurious relationships. The system grows more connected, its dependencies more intricate, but not necessarily more robust.
One anticipates a proliferation of ever-larger datasets, chasing diminishing returns. The model learns to recognize patterns, yet remains blind to the underlying mechanisms that generate them. This is not intelligence, but a sophisticated form of mimicry. The true test will not be performance on benchmark tasks, but resilience in the face of novel, unforeseen circumstances. Each additional parameter is a commitment to a particular worldview, a prophecy of future failure modes.
Ultimately, the horizon is not one of seamless integration, but of inevitable fragmentation. As the system expands, its internal contradictions will multiply, and the carefully constructed alignments will begin to unravel. Everything connected will someday fall together, and the illusion of a unified understanding will give way to the chaotic reality of a complex, adaptive system – a system that, like all systems, is destined to decay.
Original article: https://arxiv.org/pdf/2602.05646.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- EUR USD PREDICTION
- 币安人生 PREDICTION. 币安人生 cryptocurrency
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
2026-02-08 05:49