Author: Denis Avetisyan
New research details a framework for building and pre-training graph foundation models at an unprecedented scale, unlocking advanced capabilities for heterogeneous graph data.
This paper introduces GraphBFF, a system for billion-scale graph foundation models demonstrating scaling laws and a novel KL-Batching technique for efficient pre-training.
Despite the success of foundation models in language and vision, extending this paradigm to the complex and heterogeneous nature of real-world graphs remains a significant challenge. This work introduces a comprehensive framework, detailed in ‘Billion-Scale Graph Foundation Models’, for constructing billion-parameter Graph Foundation Models (GFMs) capable of generalizing across diverse graph-structured data. By presenting the GraphBFF Transformer and demonstrating predictable scaling laws with increasing model capacity and data, we establish a pathway for efficient pre-training via techniques like KL-Batching and achieve substantial performance gains-up to 31 PRAUC points-on unseen downstream tasks. Can these findings pave the way for a new era of principled and scalable graph learning at an industrial scale?
The Inevitable Limits of Local Perception
Conventional graph neural networks, such as Graph Convolutional Networks (GCNs), often falter when confronted with the intricacies of expansive, diverse graph structures. These models typically rely on localized information aggregation – examining a node’s immediate neighbors – which proves insufficient for capturing the subtle, long-range dependencies crucial in billion-scale graphs. The inherent limitations stem from the fixed-size message passing and the difficulty in distinguishing between important and irrelevant connections within highly heterogeneous networks. Consequently, GCNs struggle to generalize across varying node types and relationship strengths, hindering their ability to effectively model real-world phenomena like social networks, knowledge graphs, and biological systems where relationships are complex and multifaceted. This challenge necessitates the development of more sophisticated architectures capable of handling both scale and heterogeneity to unlock the full potential of graph representation learning.
As graph neural networks grow in complexity, attempting to incorporate billion-scale parameters into traditional methods quickly reveals significant computational bottlenecks. The core issue lies in the quadratic growth of operations required for message passing and attention mechanisms – each node potentially interacting with every other – which rapidly exhausts available memory and processing power. This limitation doesn’t merely slow down training; it fundamentally restricts the model’s expressiveness. A network unable to efficiently process vast parameter spaces struggles to capture the subtle, nuanced relationships within complex datasets, hindering its ability to perform sophisticated reasoning and generalization. Consequently, scaling model size beyond a certain threshold often yields diminishing returns, necessitating the development of innovative architectures designed to circumvent these computational barriers and unlock the full potential of large-scale graph data.
The ability of graph neural networks to effectively reason over interconnected data is fundamentally constrained by difficulties in capturing long-range dependencies – relationships between nodes that are distant within the graph structure. Traditional graph architectures often struggle as information must traverse numerous layers to connect these distant nodes, leading to signal attenuation and computational inefficiency. This limitation hinders performance in tasks requiring holistic understanding, such as knowledge graph completion or complex relationship prediction. Consequently, research is increasingly focused on developing novel architectures – including attention mechanisms, hierarchical pooling, and alternative message passing schemes – designed to circumvent these limitations and enable more effective propagation of information across the entire graph, ultimately facilitating robust reasoning capabilities even in scenarios with extensive and intricate connections.
Foundation Models for the Inevitable Complexity
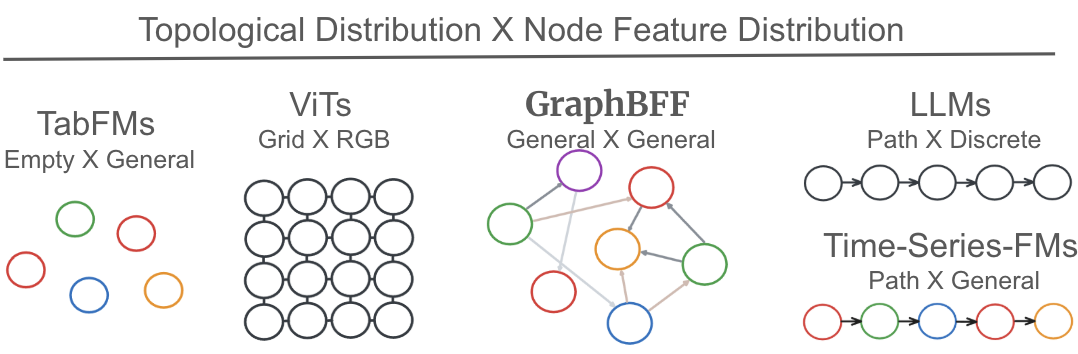
GraphBFF provides a complete framework for developing Foundation Models utilizing heterogeneous graphs, meaning it supports graphs with diverse node and edge types. This framework is engineered specifically for models containing billion-scale parameters – exceeding one billion trainable variables – which presents significant computational and memory challenges. It encompasses all stages of model building, including data ingestion, graph representation learning, model training, and deployment. The end-to-end nature of GraphBFF aims to simplify the process of creating and scaling graph-based Foundation Models compared to assembling disparate tools and libraries.
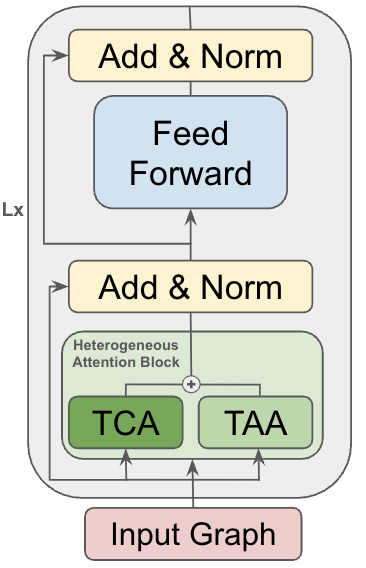
The GraphBFF Transformer is a novel architecture designed to process graph-structured data at scale. It moves beyond traditional Transformers by directly incorporating graph connectivity into its attention mechanism, allowing it to model relationships between nodes without requiring explicit feature engineering or graph embeddings. This is achieved through a sparse attention pattern focused on immediate neighbors within the graph, reducing computational complexity from O(N^2) to approximately O(N \cdot D), where N represents the number of nodes and D is the average node degree. The architecture supports heterogeneous graphs, enabling the modeling of diverse node and edge types, and incorporates learnable edge representations to capture nuanced relationships between nodes. This allows the GraphBFF Transformer to effectively handle complex graph structures and extract meaningful representations for downstream tasks.
GraphBFF mitigates computational bottlenecks inherent in large-scale graph neural network training through the implementation of Sparse Softmax and KL-Batching. Sparse Softmax reduces the computational complexity of the softmax operation – a significant cost factor during training – by only computing the probabilities for a relevant subset of neighbor nodes, effectively limiting the size of the output distribution. Complementing this, KL-Batching approximates the full batch Kullback-Leibler (KL) divergence calculation by dividing the batch into smaller subsets and iteratively updating the approximation, which reduces memory requirements and allows for the processing of larger effective batch sizes without exceeding GPU memory limits. These techniques combined enable GraphBFF to maintain performance while scaling to billion-scale graph parameters.
The Empirical Limits of Scale
GraphBFF’s architecture facilitates the empirical validation of neural scaling laws specifically within graph-structured data. Analyses reveal a power-law relationship between model size and performance, quantified by scaling exponents of \alpha_N = 0.703 for the number of nodes and \alpha_D = 0.188 for the number of edges. These exponents indicate that performance gains diminish with increasing model size, but demonstrate a predictable relationship allowing for informed scaling of resources. The observed exponents are consistent with, but not identical to, those observed in language modeling, suggesting that graph-based models exhibit distinct scaling characteristics influenced by graph topology and data distribution.
The GraphBFF framework demonstrates scalability to models containing billions of parameters. This capability facilitates substantial performance gains across a range of graph-based tasks, including node classification, link prediction, and graph-level regression. Scaling to this magnitude allows the model to capture complex relationships within graph data that are not discernible with smaller parameter counts, resulting in improved generalization and accuracy. Performance improvements are observed consistently across diverse datasets and task formulations when utilizing billion-scale models within the framework.
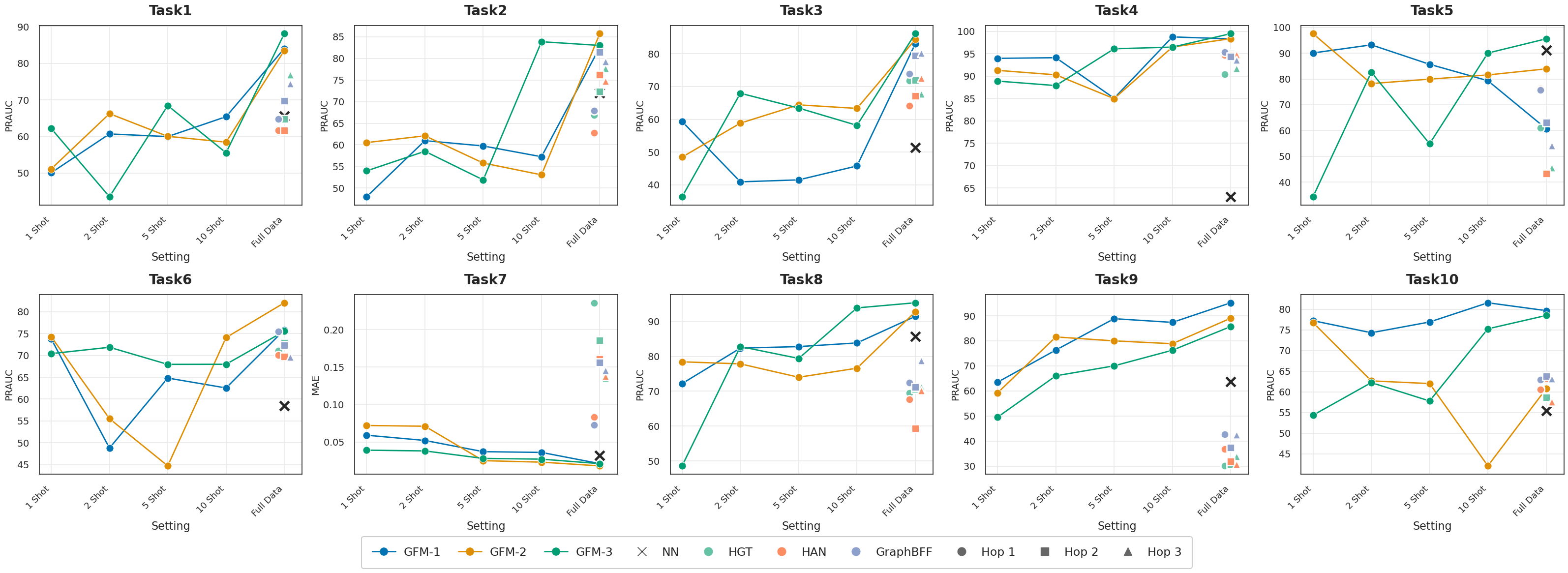
The model demonstrates strong generalization capabilities, achieving Peak Rank-Average Precision Under the Curve (PRAUC) scores of up to 95.19 in zero-shot evaluation scenarios. This performance represents a substantial improvement over task-specific baseline models; for example, in Task 9, the model achieved a PRAUC of 95.19 compared to the 42.62 achieved by baseline methods. These results indicate the model’s capacity to perform effectively on unseen graph-based tasks without task-specific training, highlighting its robust feature representation and transfer learning abilities.
Probing experiments demonstrate consistent performance gains across ten distinct downstream tasks when utilizing the framework. Specifically, improvements of up to 10% were observed, indicating a generalized benefit beyond individual task optimization. These gains were measured by evaluating the model on established datasets for each task and comparing performance metrics to existing baselines, confirming the framework’s ability to enhance generalization and accuracy across a variety of graph-based applications.
The Inevitable Horizon: Beyond Current Limits
GraphBFF represents a significant advancement in the field of graph foundation models, establishing a new performance standard for both construction and scaling. By offering a robust and efficient framework, it unlocks the potential for developing more powerful artificial intelligence systems capable of reasoning over complex relationships. This innovation isn’t merely incremental; it provides the scaffolding necessary to build graph-based AI that can handle increasingly large and intricate datasets, moving beyond the limitations of previous approaches. The resulting models promise improvements in areas like knowledge discovery, recommendation systems, and predictive modeling, ultimately facilitating a deeper understanding and more effective interaction with interconnected data.
The true power of GraphBFF lies in its capacity to process heterogeneous graphs – data structures where connections and nodes aren’t uniform, mirroring the intricacy of real-world systems. Unlike many existing graph neural networks that struggle with diverse data types, GraphBFF seamlessly integrates information from various sources, such as social networks with users, posts, and interactions, or biological pathways comprising genes, proteins, and reactions. This adaptability allows for more accurate modeling of complex phenomena, as relationships aren’t forced into simplistic, homogeneous representations. Consequently, GraphBFF offers a significant advantage in fields like drug discovery, knowledge graph reasoning, and recommendation systems, where nuanced relationships between entities are critical for generating meaningful insights and predictions.
Ongoing development of GraphBFF prioritizes innovations in attention mechanisms and optimization strategies to unlock even greater potential. Researchers are actively investigating methods to refine how the model focuses on the most relevant connections within a graph, potentially moving beyond traditional attention to explore sparse or learnable attention variants. Simultaneously, efforts are underway to optimize the computational efficiency of the framework, including techniques like quantization and pruning, to facilitate the training and deployment of larger, more complex graph foundation models. These advancements aim not only to improve performance on existing benchmarks but also to expand the scope of problems GraphBFF can effectively address, paving the way for applications requiring increasingly sophisticated graph analysis and reasoning.
The pursuit of billion-scale graph foundation models, as detailed in this work, echoes a familiar pattern. One builds not a structure, but a compromise frozen in time. The authors demonstrate scaling laws and efficient pre-training with GraphBFF, yet each architectural choice-each layer, each parameter-is a prophecy of future failure. The heterogeneity of graphs introduces complexity, a tangled web of dependencies. As John McCarthy observed, “It is perhaps a bit optimistic to expect that we can ever completely understand the workings of our own minds.” This rings true for these models as well; the deeper one delves into scaling these systems, the more apparent it becomes that complete comprehension remains elusive, and the system itself will inevitably evolve beyond initial design.
What Lies Ahead?
The construction of billion-scale graph foundation models, as demonstrated by this work, feels less like engineering and more like tending a garden. Each parameter added is a seed planted in the hope of a flourishing structure, fully aware that most will wither, and the surviving tendrils will grow in unpredictable directions. Scaling laws hold, yes, but they describe what happens, not why. The emergent properties of these models-their capacity for generalization, their susceptibility to bias-remain largely opaque, a testament to the fact that complexity breeds not understanding, but a more sophisticated form of ignorance.
KL-Batching addresses a practical hurdle-the tyranny of memory-but it’s merely a reprieve, not a solution. The relentless demand for data and compute will continue to outpace available resources. The true challenge isn’t building bigger models, but building models that learn more efficiently, that can extrapolate from sparse signals, and that don’t require the ingestion of ever-expanding datasets. Heterogeneous graphs offer a richer substrate for representation, but also introduce new complexities in alignment and interpretation.
Ultimately, this work isn’t a destination, but a point of departure. It reveals, not solves, the fundamental problem: every deploy is a small apocalypse. The structures created will inevitably decay, be superseded, or reveal unforeseen flaws. The documentation written today will be a historical artifact tomorrow, a quaint record of optimistic assumptions. The task, then, isn’t to build perfect models, but to cultivate a capacity for graceful failure and continuous adaptation.
Original article: https://arxiv.org/pdf/2602.04768.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
2026-02-05 20:38