Author: Denis Avetisyan
New research shows artificial intelligence is surprisingly adept at forecasting the success of startup ventures, challenging traditional methods of strategic foresight.
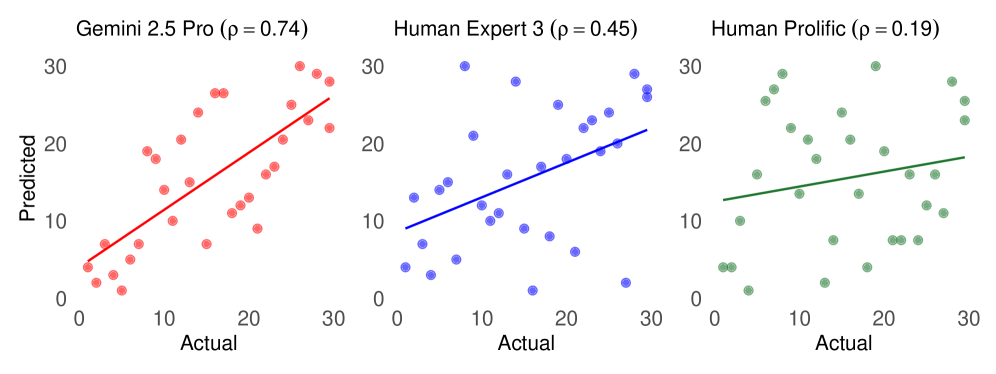
A prospective analysis of crowdfunding projects reveals that frontier large language models outperform human investors in predicting venture success.
Accurately anticipating future outcomes remains a persistent challenge for human decision-makers, particularly in high-stakes, uncertain environments. This is addressed in ‘The Strategic Foresight of LLMs: Evidence from a Fully Prospective Venture Tournament’, which benchmarks the predictive capabilities of large language models against human experts using a live, prospective prediction tournament of Kickstarter projects. Results demonstrate that frontier LLMs substantially outperform both experienced managers and investors in forecasting fundraising success, with the best model achieving a rank correlation of 0.74. Do these findings signal a fundamental shift in our ability to forecast strategic outcomes, and what implications does this hold for future decision-making processes?
Decoding Foresight: The Limits of Intuition in Complex Systems
The ability to anticipate future events and their consequences is fundamental to achieving success across numerous endeavors, from business and policy-making to scientific research. However, human judgment consistently proves fallible when confronted with complex systems and uncertain outcomes. This isn’t simply a matter of occasional miscalculation; cognitive biases, limited information processing capacity, and the inherent difficulty of extrapolating from past experience contribute to systematic errors in prediction. Consequently, strategic foresight, while undeniably crucial, often relies on intuition that, while valuable, frequently fails to accurately map present conditions onto future possibilities, leaving individuals and organizations vulnerable to unforeseen challenges and missed opportunities.
Predictive accuracy often falters not from a lack of intelligence, but from the overwhelming complexity of modern data landscapes. Traditional forecasting methods, reliant on human analysts or simplified models, frequently struggle to synthesize the sheer volume of information required for robust predictions. These approaches are particularly susceptible to overlooking subtle, yet critical, signals embedded within massive datasets – patterns that might indicate emerging trends or potential disruptions. Consequently, systematic errors arise, not necessarily from flawed reasoning, but from an inability to process and integrate the full spectrum of relevant data points, leading to forecasts that consistently miss key shifts and underestimate the likelihood of unexpected outcomes. This limitation is especially pronounced in dynamic environments where numerous interacting factors contribute to the final result.
The Kickstarter platform presents a uniquely challenging arena for predictive accuracy, operating as a real-world proving ground where creative projects live or die based on public funding. Unlike traditional market research with established metrics, Kickstarter success hinges on a complex interplay of factors – innovative ideas, compelling presentation, effective marketing, and even sheer luck. This confluence creates substantial uncertainty; a seemingly brilliant concept can fail to gain traction, while an unexpectedly simple project can become a viral sensation. The platform’s high-stakes environment, where creators risk time and resources, and backers risk financial loss, amplifies the difficulty of forecasting which ventures will ultimately flourish, making it an ideal case study for evaluating predictive methodologies.
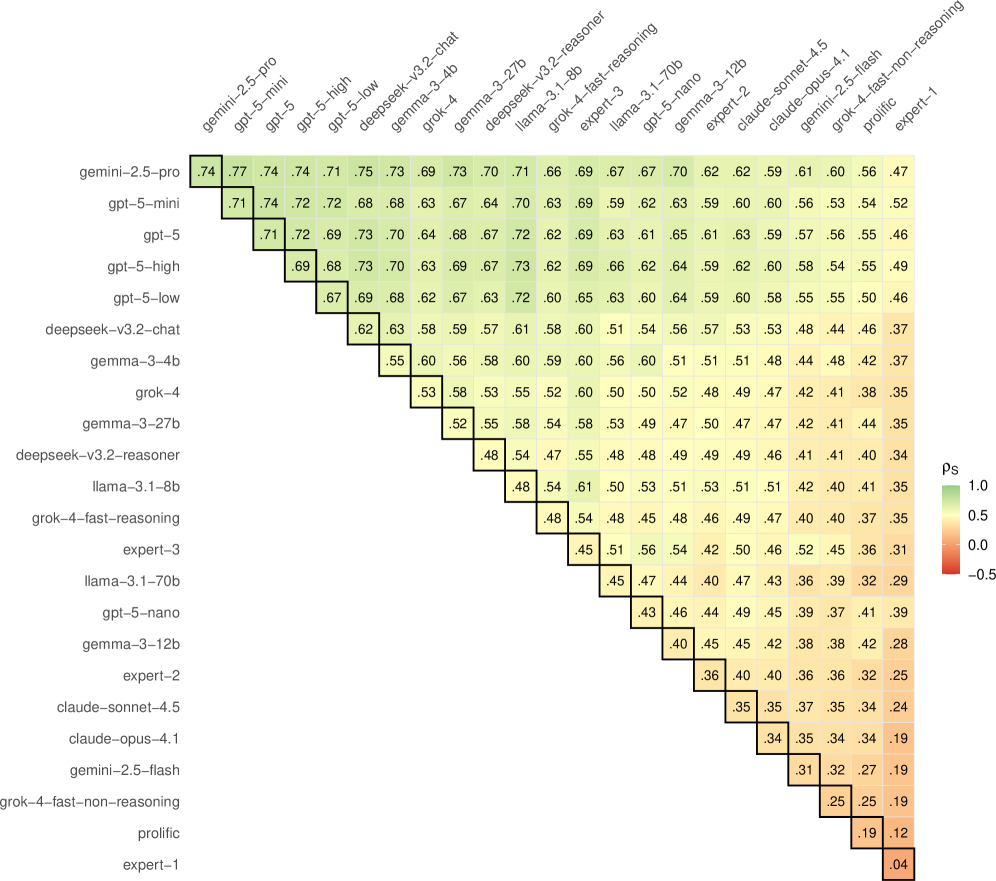
Recent analysis of Kickstarter projects reveals a striking disparity between human predictive ability and that of large language models. Quantitative results, measured by Spearman’s Rank Correlation, demonstrate that LLMs can predict project success with a correlation coefficient reaching 0.74. This indicates a strong ability to rank projects by their likelihood of funding. In contrast, human evaluators, even those with expertise in the relevant fields, achieve a maximum correlation of only 0.45. This significant difference suggests that LLMs are capable of discerning subtle patterns within project descriptions and associated data that consistently elude human judgment, offering a potentially valuable tool for both backers seeking promising ventures and creators aiming to maximize their campaign’s potential.
The Rise of Predictive Machines: A New Era of Analytical Insight
Recent progress in Large Language Models (LLMs) indicates a capacity to exceed human performance in specific predictive applications. These models, trained on extensive datasets, are demonstrating an ability to extrapolate future outcomes with increasing accuracy across diverse domains. This isn’t limited to tasks involving textual data; LLMs are now being successfully applied to numeric and categorical prediction problems. The observed performance gains suggest that LLMs can effectively identify complex relationships and subtle indicators that may not be readily apparent to human analysts, representing a significant advancement in the field of predictive analytics and artificial intelligence.
Recent applications of Large Language Models (LLMs), specifically Gemini 2.5 Pro and models within the GPT-5 family, have demonstrated predictive capabilities when applied to Kickstarter project outcomes. These models were utilized to forecast the fundraising success of projects listed on the platform, analyzing project descriptions, creator profiles, and campaign details as input data. Evaluation metrics indicated a statistically significant ability to predict which projects would meet their funding goals, surpassing baseline performance benchmarks. This application showcases the potential of LLMs to analyze complex datasets and identify predictive indicators within unstructured text, moving beyond traditional data-driven forecasting methods.
Analysis of Large Language Model (LLM) predictive capabilities indicates performance exceeding simple correlational relationships. LLMs demonstrate an ability to discern nuanced patterns and signals within datasets that are not readily apparent to human analysts, leading to improved forecast accuracy. Statistical testing of LLM predictions against human predictions in 253 pairwise comparisons revealed statistically significant results (p < 0.05) in 96 instances, confirming that the observed improvements are not attributable to random chance and highlighting the models’ capacity for identifying non-obvious predictive factors.
Effective deployment of Large Language Models for predictive tasks necessitates comprehensive evaluation protocols beyond initial benchmark results. Factors influencing model performance include dataset quality, potential biases within training data, and the specific features used as inputs. Rigorous testing should encompass diverse datasets, sensitivity analysis to input variations, and assessment of generalization capabilities to unseen data. Furthermore, careful consideration must be given to computational costs, scalability, and the interpretability of model outputs to ensure reliable and actionable forecasts. Ongoing monitoring and recalibration are crucial to maintain accuracy and adapt to evolving data patterns.
Validating Analytical Rigor: Establishing a Foundation for Trustworthy Predictions
Effective evaluation of Large Language Model (LLM) performance necessitates the use of standardized datasets to facilitate reproducible results and fair comparisons between models. Beyond simple accuracy metrics, statistical measures like Spearman’s Rank Correlation are crucial for assessing the ability of LLMs to correctly rank predictions; this is particularly important when evaluating predictive tasks where the order of results carries significant weight. Spearman’s Rank Correlation, which assesses the monotonic relationship between predicted and actual rankings, provides a more robust evaluation than metrics sensitive to absolute prediction values. Utilizing these standardized datasets and statistical measures allows for a more objective and quantifiable assessment of LLM capabilities, moving beyond qualitative observations to data-driven conclusions.
Data standardization is a critical prerequisite for reliable evaluation of Large Language Models (LLMs). Variations in data formatting, labeling conventions, and feature engineering across different datasets can introduce confounding variables, leading to inaccurate performance comparisons. Without consistent data preprocessing, observed differences in model outputs may reflect disparities in the data itself, rather than genuine variations in model capabilities. This necessitates the use of standardized datasets with clearly defined schemas and consistent labeling practices. Furthermore, standardization extends to the evaluation metrics employed; consistent application of metrics across models and datasets is essential to avoid spurious results and ensure fair assessment of relative performance.
The performance of Large Language Models (LLMs) is directly affected by the composition and characteristics of their training data. Systematic biases present within this data – stemming from skewed representation, historical inaccuracies, or prejudiced viewpoints – are inevitably learned by the model and subsequently reflected in its outputs. This means LLMs may consistently favor certain demographics, perpetuate existing stereotypes, or exhibit inaccuracies related to underrepresented topics. The quality of the training data, therefore, is a critical determinant of model reliability and fairness; insufficient or biased data will limit the model’s generalizability and introduce predictable errors, even with advanced architectural designs or extensive parameter counts.
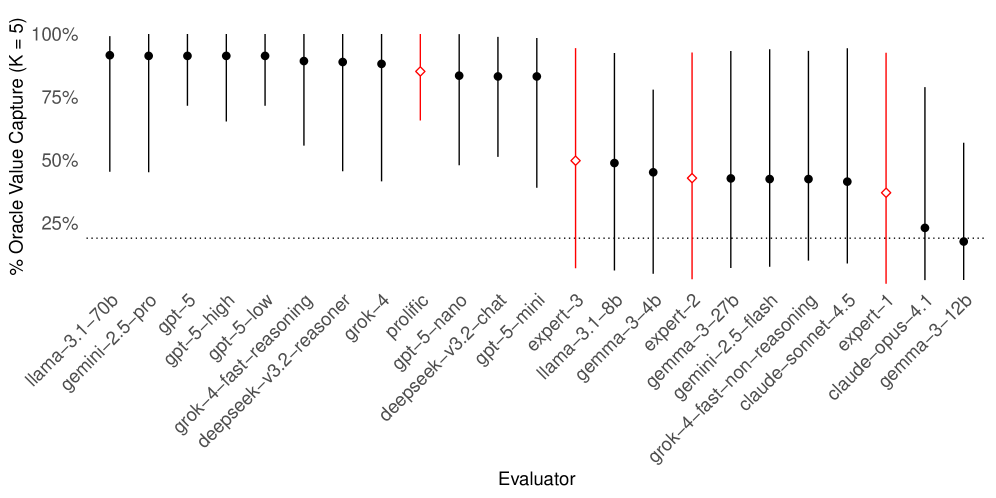
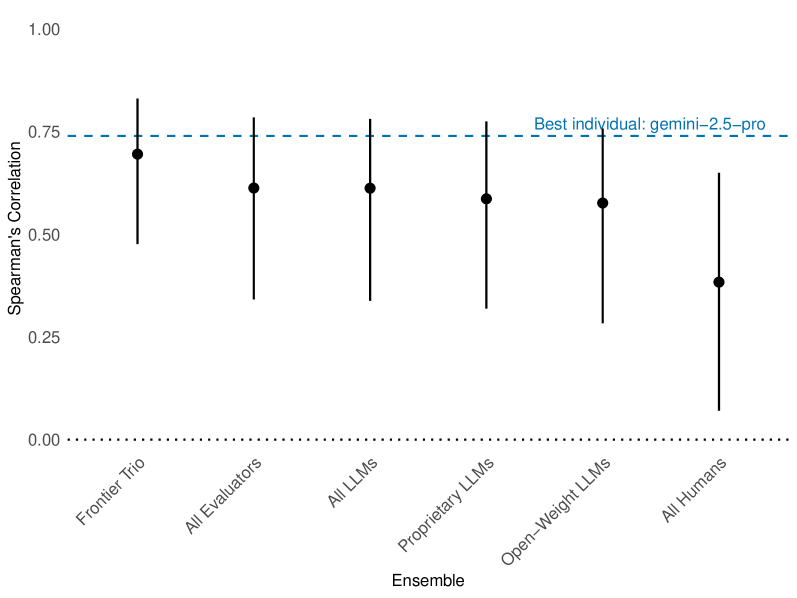
Analysis of aggregated Large Language Models (LLMs) revealed a minimal improvement in predictive correlation-an increase of only 0.03-suggesting that basic ensemble methods offer limited gains. Comparative evaluation using Prolific crowdworkers demonstrated human capability in identifying top projects, achieving 85% value capture; however, this level of performance was consistently surpassed by the top-performing LLMs, indicating superior predictive accuracy despite the marginal benefits observed from LLM aggregation.
Beyond Prediction: Forging a Synergistic Partnership Between Human Insight and Artificial Intelligence
Despite demonstrable successes in certain predictive applications, large language models are not infallible. A phenomenon termed “Outcome Compression” limits their ability to accurately assess probabilities across a full spectrum of potential results, often flattening nuanced outcomes into overly simplified predictions. Furthermore, inherent biases present within the training data – reflecting existing societal patterns and prejudices – can systematically skew model outputs, leading to unfair or inaccurate forecasts. These limitations underscore that while LLMs excel at identifying correlations, they struggle with genuine causal understanding and often lack the contextual awareness necessary for robust, reliable prediction, particularly in complex, real-world scenarios.
The most significant advancements aren’t realized through artificial intelligence operating in isolation, but rather through deliberate human-AI collaboration. While large language models excel at processing vast datasets and identifying patterns, they often lack the nuanced judgment and contextual understanding inherent in human intuition. This partnership leverages the speed and analytical power of AI to augment, not replace, human expertise. By combining AI-driven insights with a human’s ability to interpret ambiguity, assess ethical implications, and anticipate unforeseen consequences, organizations can move beyond simple prediction to achieve truly strategic foresight. This synergistic approach allows for more robust decision-making, particularly in complex and rapidly evolving environments, ultimately fostering innovation and sustainable competitive advantages.
Organizations increasingly recognize that the confluence of artificial intelligence and human expertise yields markedly superior strategic outcomes. AI systems excel at processing vast datasets and identifying patterns, providing data-driven insights that might elude human analysis; however, these systems often lack the contextual understanding and nuanced judgment crucial for navigating complex, real-world scenarios. Integrating AI-generated insights with the domain knowledge, critical thinking, and ethical considerations of human experts allows for a more holistic and informed decision-making process. This collaborative approach doesn’t simply augment human capabilities, but rather transforms the strategic landscape, fostering adaptability and resilience in the face of uncertainty and enabling proactive responses to emerging challenges – ultimately driving sustained competitive advantage.
The integration of human insight with artificial intelligence promises a fundamental shift in how organizations approach strategy. This isn’t simply about improved accuracy in forecasting, but about cultivating a capacity for strategic foresight – the ability to anticipate future challenges and opportunities with greater precision. By complementing AI’s analytical power with human domain expertise, nuanced judgment, and ethical considerations, businesses can move beyond reactive problem-solving toward proactive adaptation. This synergistic approach fosters resilience in rapidly changing environments and enables the sustained competitive advantage that comes from anticipating – and shaping – the future, rather than merely responding to it. Ultimately, the value lies not in replacing human strategists, but in augmenting their capabilities, creating a powerful cycle of learning and innovation.
The study’s findings regarding LLMs’ predictive accuracy on Kickstarter campaigns highlight a compelling shift in strategic foresight. These models don’t merely extrapolate from past data; they demonstrate an ability to assess complex, novel ventures with greater precision than human evaluators. This echoes David Hume’s assertion: “The mind is not a passive receiver of impressions, but an active interpreter of them.” The LLM, similarly, isn’t simply absorbing project descriptions; it’s actively processing nuanced features to formulate predictions. The venture tournament methodology provided a rigorous, prospective testing ground, and the consistently superior performance of the LLMs suggests a fundamental change in how future predictions can be made. If a pattern cannot be reproduced or explained, it doesn’t exist.
Beyond Prediction: Charting Future Landscapes
The demonstrated capacity of large language models to anticipate venture success, while noteworthy, merely scratches the surface of a deeper question. Each successful prediction isn’t an endpoint, but an invitation to dissect the underlying patterns. The models don’t know which projects will succeed; they identify subtle structural dependencies within the data that correlate with positive outcomes. The challenge now lies in extracting these dependencies – in translating algorithmic correlation into human-understandable strategic insight. Simply achieving higher accuracy is a sterile pursuit without interpreting the ‘why’ behind the forecast.
Future work must move beyond benchmark datasets and embrace truly prospective analysis. The venture tournament framework offers a compelling methodology, but scaling such experiments – and crucially, extending the forecasting horizon – will be essential. Current models excel at short-term prediction; assessing their ability to anticipate disruption, to identify genuinely novel ventures, remains largely unexplored. The limitation isn’t computational power, but the availability of data rich enough to capture the pre-history of innovation.
Ultimately, the strategic value of these models resides not in replacing human judgment, but in augmenting it. The most fruitful avenue of research lies in developing interfaces that allow humans to interrogate the models’ reasoning, to visualize the patterns they detect, and to challenge their assumptions. The goal isn’t to build an infallible predictor, but to create a symbiotic system where algorithmic foresight and human intuition converge.
Original article: https://arxiv.org/pdf/2602.01684.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Infinity Nikki Candlelight Reverie Challenge and Rewards Guide
- Brent Oil Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- EUR ZAR PREDICTION
- Tennis pro begs umpire for bathroom break to avoid “sh*tting on court”
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
2026-02-04 05:48