Author: Denis Avetisyan
A new benchmark reveals that even the most advanced language models struggle to grasp the subtle nuances of Japanese financial text.

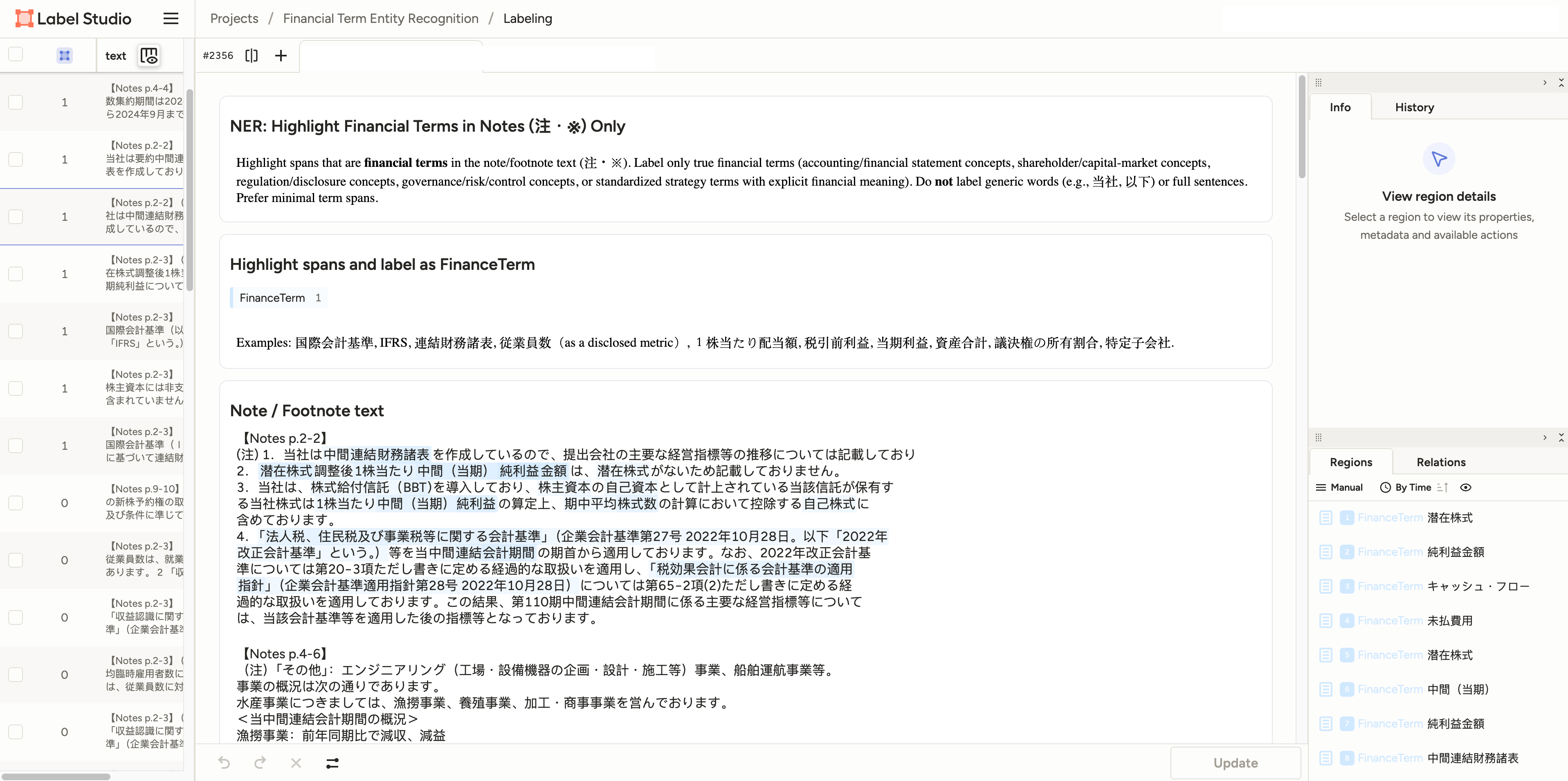
This paper introduces Ebisu, a comprehensive evaluation suite for assessing large language models’ performance on tasks requiring deep understanding of Japanese finance, including financial term extraction and implicit commitment recognition.
Despite advances in large language models, nuanced understanding of financial language remains a significant challenge, particularly in contexts demanding cultural and linguistic sensitivity. This is addressed in ‘Ebisu: Benchmarking Large Language Models in Japanese Finance’, which introduces a new benchmark designed to evaluate LLM performance on tasks requiring comprehension of complex Japanese financial communication. Results demonstrate that even state-of-the-art models struggle with both implicit commitment recognition and hierarchical financial terminology extraction, suggesting that scale and adaptation alone are insufficient. Can targeted linguistic and cultural grounding unlock substantial improvements in financial NLP for low-resource, high-context languages?
The Intricacies of Japanese Financial Language
The application of Large Language Models (LLMs) to financial communication faces considerable obstacles when dealing with languages possessing complex grammatical structures, notably Japanese. Unlike languages that rely heavily on word order, Japanese is agglutinative, meaning that grammatical functions are indicated by adding numerous suffixes to root words – a single concept can be expressed with a remarkably long and intricately modified word. This poses a significant challenge for LLMs, which are often trained on languages with simpler morphology and may struggle to accurately parse and interpret the nuanced meanings embedded within these complex Japanese terms. Successfully deciphering financial text, already dense with specialized terminology, requires not only recognizing the core concepts but also correctly identifying the subtle shifts in meaning conveyed by these agglutinative forms, demanding a level of linguistic sophistication that current LLMs often lack.
Japanese financial text presents unique challenges for natural language understanding systems due to the inherent characteristics of the language itself. Unlike English, which relies heavily on word order and prepositions, Japanese is an agglutinative language – meaning words are formed by stringing together numerous affixes, each carrying specific grammatical or semantic meaning. This creates exceptionally long and complex word structures, often conveying information within a single lexical item that would require an entire phrase in English. Furthermore, Japanese employs a head-final structure, placing key information – such as verbs and adjectives – at the end of sentences, requiring algorithms to parse the entire sentence before grasping its core meaning. Consequently, standard natural language processing techniques, frequently optimized for languages like English, prove inadequate; specialized approaches that account for both the agglutinative nature and head-final syntax are essential to accurately interpret financial data and extract meaningful insights from Japanese sources.
Accurate interpretation of Japanese financial texts requires more than simply translating words; it necessitates a deep understanding of the language’s inherent structure and the specialized vocabulary of the financial world. Japanese, unlike English, is an agglutinative language where complex meanings are often conveyed through suffixes and particles, demanding nuanced parsing beyond standard natural language processing techniques. Furthermore, the financial sector utilizes a unique lexicon – encompassing both kanji-based terms and modern loanwords – that frequently diverges from everyday usage. Successfully navigating this linguistic landscape requires models capable of discerning subtle grammatical cues and recognizing domain-specific terminology, ensuring precise comprehension of reports, contracts, and market analyses. Without this combined linguistic and contextual awareness, critical information can be easily misinterpreted, potentially leading to flawed investment decisions or inaccurate risk assessments.
Adapting Algorithms for Japanese Financial Discourse
Japanese Language Models (JLMs) are not constructed from a void; rather, they are built upon the foundation of pre-trained Large Language Models (LLMs). These LLMs, typically trained on massive datasets of general text and code, provide a foundational understanding of language structure, grammar, and semantics. This pre-existing knowledge is then transferred and refined through further training on Japanese-specific corpora. Utilizing this transfer learning approach significantly reduces the data and computational resources required compared to training a language model entirely from the ground up, and allows JLMs to benefit from the LLM’s inherent capacity for understanding complex linguistic patterns.
Financial domain adaptation is essential for Large Language Model (LLM) performance in Japanese finance due to the sector’s highly specialized terminology and distinct phrasing conventions. General-purpose LLMs lack inherent understanding of terms like “yūkabugata” (bearer shares) or the specific grammatical structures common in financial reports and regulatory filings. Adaptation techniques, including continued pre-training on large corpora of Japanese financial text and fine-tuning with task-specific datasets, enable LLMs to accurately parse and interpret these nuances. This process improves the model’s ability to correctly identify entities, relationships, and sentiment within financial documents, ultimately leading to enhanced accuracy in downstream tasks such as information extraction, risk assessment, and automated report generation.
Specialization of Large Language Models (LLMs) for the Japanese financial domain demonstrably improves performance on tasks such as sentiment analysis of financial news, named entity recognition within financial reports, and automated summarization of regulatory filings. Specifically, domain adaptation techniques, including continued pre-training on large corpora of Japanese financial text and fine-tuning on labeled datasets relevant to specific financial tasks, yield statistically significant gains in accuracy and F1-score compared to general-purpose LLMs. These improvements translate directly into enhanced efficiency and reliability for applications including fraud detection, risk assessment, and investor communication.
Introducing a Rigorous Benchmark for Japanese Financial AI
The Japanese Financial Benchmark is designed as a consistent and reproducible method for evaluating the performance of language models specifically within the domain of Japanese finance. This benchmark addresses the need for targeted assessment, moving beyond general language understanding to focus on tasks requiring specialized financial knowledge and nuanced comprehension of Japanese financial terminology. By providing a standardized suite of evaluation tasks and metrics, the benchmark facilitates objective comparison of different models and tracks progress in applying language AI to financial applications in Japan. The framework allows researchers and developers to quantify a model’s ability to process and interpret financial data, identify key information, and understand implicit meanings relevant to the Japanese financial landscape.
The Japanese Financial Benchmark assesses language model proficiency through targeted tasks, notably JF-TE (Financial Term Extraction) and JF-ICR (Implicit Commitment Recognition). JF-TE requires models to identify and classify financial terminology within Japanese text, evaluating their understanding of domain-specific vocabulary. JF-ICR, conversely, tests a model’s ability to infer commitments or obligations expressed implicitly within financial documents, demanding nuanced comprehension of contextual cues and semantic relationships. These tasks are designed to isolate and measure distinct language understanding capabilities crucial for applications within the Japanese financial sector.
Evaluation of language model performance on the Japanese Financial Benchmark utilizes established metrics: F1 Score for the JF-TE (Financial Term Extraction) task and Accuracy for the JF-ICR (Implicit Commitment Recognition) task. Empirical results demonstrate a positive correlation between model scale and performance on both tasks. Specifically, increasing model size yielded an improvement of +0.38 in F1 Score for JF-TE and an increase of +0.33 in Accuracy for JF-ICR, indicating that larger models exhibit enhanced capabilities in understanding and processing Japanese financial text.
Quantifying Performance Through Precise Ranking Metrics
Evaluating a model’s ability to correctly rank relevant financial terms requires nuanced metrics; therefore, the JF-TE task utilizes both F1 Score and HitRate@K. While F1 Score assesses the precision and recall of identified terms, HitRate@K specifically gauges the model’s ranking proficiency by measuring whether the correct financial term appears within the top K results. This is crucial because, in practical applications, users often focus on the highest-ranked suggestions. By employing HitRate@K – typically assessed at values like K=1, 5, and 10 – researchers can determine how effectively the model prioritizes the most relevant financial terminology, providing a more complete picture of performance than precision and recall alone and ensuring the model isn’t simply identifying terms, but presenting them in a useful order.
A consistent and reliable evaluation of ranking models requires a standardized framework, and the LM Evaluation Harness fulfills this need for the Japanese Financial Term Extraction (JF-TE) task. This tool streamlines the process of assessing model performance by providing a unified platform for running evaluations across diverse models and experimental settings. Critically, the Harness ensures reproducibility – allowing researchers to consistently replicate results – and facilitates comparability, enabling a direct assessment of advancements achieved by different approaches. By removing inconsistencies stemming from varied implementation details, the LM Evaluation Harness moves the field towards more robust and trustworthy benchmarks in Japanese financial language understanding and analysis.
The synergy between HitRate@K and F1 Score offers a robust evaluation of model capabilities in the complex domain of Japanese financial text. By assessing both the precision of identified financial terms and the model’s ability to rank them effectively, researchers gain a nuanced understanding of performance beyond simple accuracy. This comprehensive approach isn’t merely about quantifying success; it actively guides further development. Identifying specific strengths and weaknesses-where a model excels at pinpointing terms but struggles with prioritization, or vice versa-allows for targeted improvements in algorithms and training data. Consequently, this rigorous evaluation framework is accelerating progress in Japanese financial language understanding, promising more sophisticated tools for analysis, risk management, and ultimately, a deeper comprehension of this critical economic landscape.
The pursuit of accurate financial language processing, as demonstrated by the Ebisu benchmark, demands a relentless focus on logical completeness. Current large language models, while proficient in general language tasks, reveal deficiencies when confronted with the subtle nuances of Japanese finance. This echoes Blaise Pascal’s observation: “The eloquence of the tongue never convinces so much as the eloquence of the heart.” Just as genuine conviction requires internal consistency, a truly robust model must exhibit an unwavering adherence to the underlying logic of financial discourse, moving beyond superficial pattern recognition to achieve demonstrable, provable understanding of implicit commitments and complex terminology.
Future Directions
The presented benchmark, while establishing a measurable, if disheartening, baseline, does not, of course, solve the problem of natural language understanding in the Japanese financial domain. Rather, it precisely articulates the nature of the difficulty. Current large language models, trained on generalized corpora, demonstrate a predictable failure to grasp the subtle interplay of linguistic nuance and pragmatic context inherent in specialized discourse. The observed deficiencies are not merely matters of lexical coverage, but reflect a fundamental inability to reason about implicit commitments and financial reasoning.
Future work must move beyond superficial performance metrics. The asymptotic complexity of truly understanding such a language-incorporating both formal semantics and common-sense knowledge-is considerable. Attempts to brute-force this understanding through ever-larger models are likely to yield diminishing returns. A more fruitful path lies in the development of hybrid systems, integrating symbolic reasoning with statistical learning. The creation of formally verified knowledge graphs, representing the ontological structure of Japanese finance, represents a critical, though challenging, endeavor.
Ultimately, the pursuit of artificial intelligence in this domain is not simply a matter of achieving higher scores on a benchmark. It is an exercise in formalizing what it means to understand, and thus, a test of the limits of computational representation itself. The observed failures are, in a sense, elegant-revealing the profound gap between statistical correlation and genuine comprehension.
Original article: https://arxiv.org/pdf/2602.01479.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
2026-02-03 07:54