Author: Denis Avetisyan
A new benchmark assesses the ability of artificial intelligence to synthesize information from text, images, and videos for complex financial analysis.
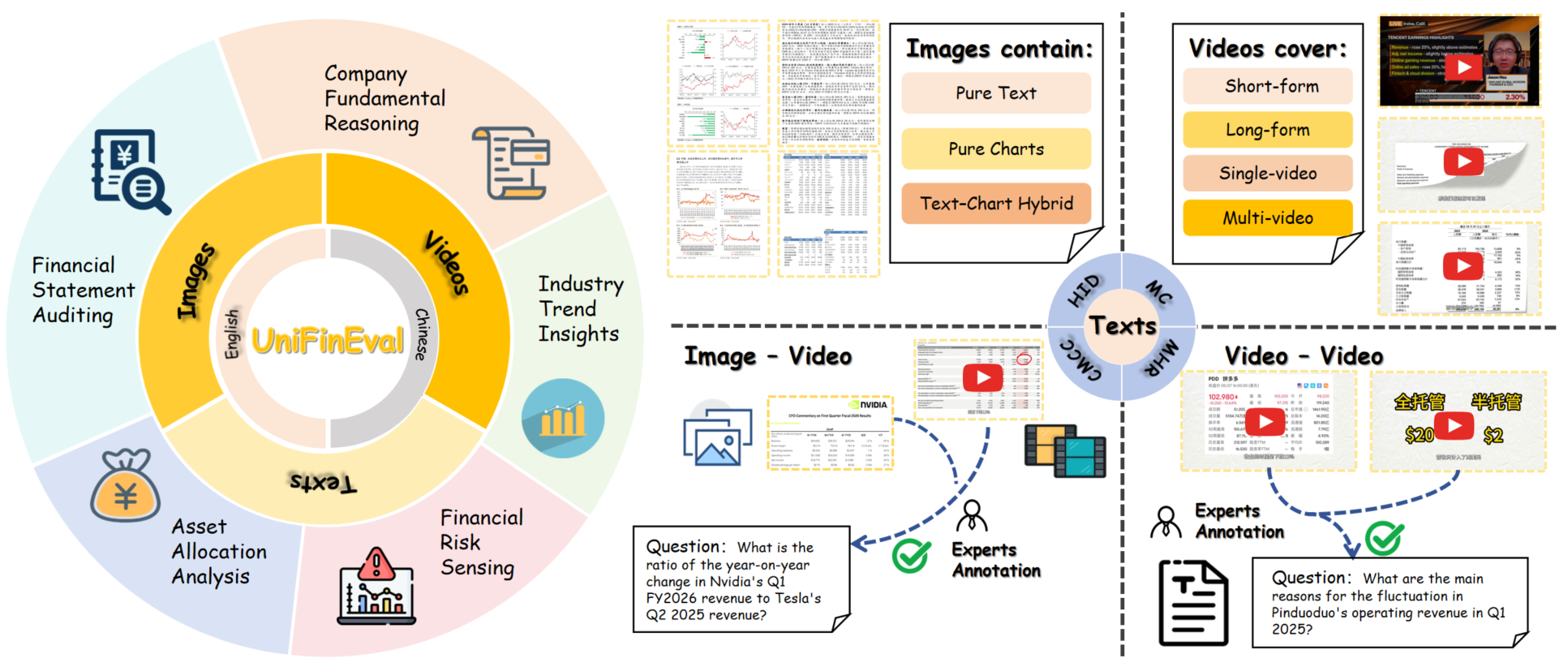
UniFinEval introduces a unified evaluation framework for multimodal large language models tackling high-information density financial tasks.
Despite the growing prominence of multimodal large language models in financial applications, existing benchmarks inadequately address the complexities of high-density financial data and the need for cross-modal reasoning. To address this gap, we introduce UniFinEval: Towards Unified Evaluation of Financial Multimodal Models across Text, Images and Videos, a novel benchmark designed to systematically evaluate MLLM performance across five core financial scenarios-from auditing and fundamental analysis to risk sensing and asset allocation. Constructed with a high-quality, 3,767 question-answer pair dataset in both Chinese and English, UniFinEval reveals a substantial performance gap between current models, including Gemini-3-pro-preview, and human financial experts. Can this benchmark catalyze the development of more robust and reliable MLLMs for real-world financial decision-making?
The Evolving Landscape of Financial Intelligence
For decades, financial analysis has been fundamentally shaped by human analysts poring over neatly organized datasets – balance sheets, income statements, and market statistics. However, this traditional approach increasingly falters when confronted with the sheer volume and variety of unstructured information now available. News articles, social media feeds, regulatory filings filled with qualitative descriptions, and even visual data like charts and infographics all contain potentially valuable signals. The difficulty lies in the fact that these sources aren’t easily quantifiable or integrated into standard analytical frameworks. Consequently, crucial insights often remain hidden within these complex, messy datasets, highlighting a significant limitation in current financial intelligence capabilities and creating a demand for tools that can effectively bridge the gap between structured data and the wealth of unstructured information now driving market dynamics.
Effective financial intelligence increasingly demands the ability to synthesize information presented in varied formats. Modern analysis isn’t limited to numerical datasets; instead, it necessitates interpreting textual reports, visual charts, and even images – such as those depicting market sentiment or company logos. This requires cross-modal reasoning, a sophisticated cognitive process where information from different modalities is integrated to form a coherent understanding. Successfully linking a textual earnings call transcript to a corresponding stock price chart, or correlating news images with market fluctuations, isn’t merely about data aggregation, but about discerning the relationships between these distinct data types. The capacity to perform this nuanced analysis is crucial for identifying emerging trends, assessing risk accurately, and ultimately, making informed financial decisions in a complex and rapidly evolving landscape.
The promise of large language models in financial analysis is tempered by a critical limitation: their struggle with multimodal data integration. While adept at processing text, these models often falter when tasked with synthesizing information from diverse sources like financial charts, images, and textual reports. This inability to accurately interpret and correlate these varying signals-a company’s stock performance visualized in a graph alongside news articles detailing executive changes, for instance-introduces inaccuracies into their analyses. Consequently, decisions informed by these flawed interpretations can lead to miscalculated risks, missed opportunities, and ultimately, suboptimal financial outcomes. The core issue isn’t a lack of data, but the model’s difficulty in establishing meaningful connections between different data modalities, hindering its capacity for holistic financial intelligence.
Introducing UniFinEval: A Standard for Rigorous Assessment
UniFinEval is a newly developed benchmark designed for evaluating large language models (LLMs) within the financial domain. The benchmark consists of 3,767 question-and-answer pairs, each constructed to represent realistic financial scenarios. These Q&A pairs are not simply factual recall exercises; they require models to demonstrate understanding and reasoning capabilities applicable to practical financial tasks. Data quality is a primary focus, with all pairs undergoing expert annotation to ensure accuracy and relevance for benchmark purposes. The scale of 3,767 pairs provides a statistically significant dataset for assessing model performance and comparing different LLM architectures and training methodologies.
UniFinEval assesses model capabilities across a range of critical financial tasks. These include company fundamental reasoning, which tests understanding of business drivers and financial health; asset allocation analysis, evaluating strategies for portfolio construction; financial statement auditing, verifying the accuracy and compliance of reported financials; industry trend insights, identifying and interpreting shifts in market sectors; and financial risk sensing, detecting potential threats to investment performance. Performance on these tasks is designed to reflect a model’s ability to handle the complexities of real-world financial decision-making processes.
UniFinEval’s data quality and relevance are assured through a rigorous expert annotation process. Each question-answer pair within the 3,767-item benchmark was reviewed and validated by financial professionals possessing domain expertise in areas such as fundamental analysis and financial auditing. This annotation process included verification of the factual accuracy of both questions and answers, assessment of the logical reasoning required to arrive at the correct answer, and confirmation that the provided answers accurately reflect established financial principles. The use of expert validation minimizes noise and ambiguity, resulting in a benchmark that provides a dependable and objective evaluation of large language model capabilities in complex financial scenarios.
UniFinEval distinguishes itself by requiring models to integrate information presented in multiple modalities – specifically text, images, and charts – to arrive at answers. This cross-modal reasoning capability is critical because real-world financial analysis rarely relies on a single data source; analysts routinely interpret textual reports, visual representations of data like stock charts, and image-based information such as company logos or infographics. The benchmark’s question-answer pairs are constructed to necessitate this synthesis, forcing models to move beyond single-modality processing and demonstrate a more holistic understanding of financial information, accurately reflecting the complexities of practical financial tasks.
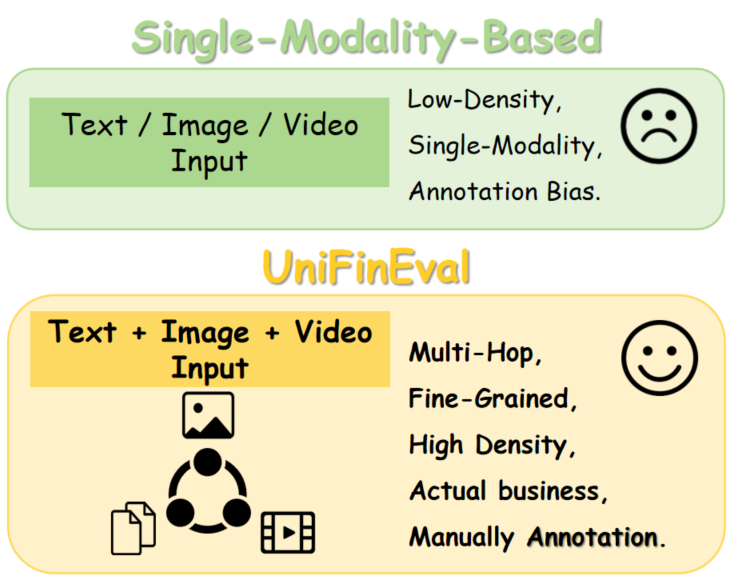
Validating Model Performance with UniFinEval
UniFinEval serves as a benchmark for assessing the capabilities of advanced multimodal large language models. Recent evaluations have included GPT-5.1, Gemini-3-pro-preview, and Qwen3-VL-235B-A22B-Thinking, representing a cross-section of leading models in the field. The framework is designed to provide a standardized methodology for comparing performance across different architectures and training datasets, facilitating objective analysis of model strengths and weaknesses in multimodal reasoning and understanding.
Zero-shot evaluation assesses a model’s capacity to generalize to unseen tasks without any prior training on those specific tasks. This methodology presents the model with a task description and expects a solution based solely on its pre-existing knowledge acquired during pre-training. The absence of task-specific fine-tuning allows for a more direct measure of the model’s inherent reasoning and knowledge transfer capabilities, providing insights into its adaptability and overall intelligence. Performance is then measured by comparing the model’s output to a known ground truth, quantifying its ability to correctly interpret and execute the given instructions without prior exposure to similar examples.
Across the UniFinEval benchmark suite, Gemini-3-pro-preview demonstrated the highest overall performance, achieving an average accuracy of 73.8%. This metric represents the aggregated results from a diverse set of financial reasoning tasks, evaluating the model’s ability to interpret and process complex financial data in a zero-shot setting. The reported accuracy is a weighted average, reflecting the relative importance of each task within the benchmark, and serves as a quantitative indicator of the model’s general financial intelligence compared to other evaluated LLMs, including GPT-5.1 and Qwen3-VL-235B-A22B-Thinking.
Detailed error analysis is a critical component of multimodal large language model (MLLM) evaluation because it identifies specific failure modes and informs targeted improvements. This process moves beyond aggregate accuracy scores to pinpoint the types of errors – such as misinterpreting visual cues, failing to integrate information from multiple modalities, or exhibiting logical reasoning flaws – that contribute to overall performance deficits. By categorizing these errors, developers can prioritize research and engineering efforts towards addressing the most impactful weaknesses, ultimately leading to more robust and reliable models. Error analysis also facilitates the creation of more effective training data and the development of targeted regularization techniques to mitigate recurring failure patterns.
Chain-of-thought reasoning is a prompting technique used in zero-shot evaluation that encourages large language models to explicitly state the intermediate steps taken to arrive at a final answer. This is achieved by including prompts that request the model to “think step by step” or to detail its reasoning process before providing a conclusion. By forcing the model to articulate its thought process, chain-of-thought prompting improves performance as it allows for easier identification of errors and biases in the model’s logic, and encourages a more structured and coherent approach to problem-solving without requiring task-specific training data.
The UniFinEval benchmark results indicate that Gemini-3-pro-preview achieved an accuracy of 61.1% on the Asset Allocation Analysis task. This performance level represents a relative weakness compared to its overall average accuracy of 73.8% across all UniFinEval tasks, and suggests a substantial performance gap exists when evaluating multimodal large language models on tasks demanding complex financial reasoning and analysis. This discrepancy indicates that while the model demonstrates strong general capabilities, its ability to effectively process and interpret data for sophisticated asset allocation scenarios requires further development.

Implications and Future Directions for Financial AI
The emergence of UniFinEval and its associated results demonstrate a pivotal shift in the landscape of financial analysis, driven by the capabilities of multimodal large language models. These models, proficient in processing and integrating diverse data types – including text, numerical data, and even visual information like charts – are proving adept at tasks previously requiring substantial human expertise. Initial evaluations suggest a significant potential to automate complex processes such as earnings call analysis, fraud detection, and credit risk assessment with increased accuracy and efficiency. This isn’t simply about automating existing workflows; the ability to synthesize information across modalities unlocks opportunities for novel insights and the development of more nuanced financial strategies, ultimately promising a more data-driven and intelligent approach to financial decision-making.
The capacity of multimodal large language models to synthesize information from diverse sources – textual reports, numerical data, and even visual charts – fundamentally alters the landscape of financial analysis. This improved cross-modal reasoning translates directly into more nuanced risk assessments, as models can identify subtle correlations and anomalies often missed by traditional methods. Consequently, investment decisions benefit from a more holistic understanding of market dynamics, potentially leading to higher returns and reduced volatility. Beyond investment, individuals stand to gain from enhanced financial planning tools capable of integrating complex personal data with broader economic trends, ultimately fostering greater financial security and well-being through data-driven insights.
Ongoing research endeavors are concentrating on refining both the methods used to instruct multimodal large language models and the models’ underlying structures to achieve greater proficiency in tackling intricate financial challenges. This includes exploring advanced prompting strategies – techniques that move beyond simple question-and-answer formats to guide models through multi-step reasoning processes – and innovating model architectures to better capture the nuances of financial data. The goal is to move beyond current capabilities, enabling these models to not only process information from diverse sources – such as financial reports, news articles, and market data – but also to synthesize it effectively and generate actionable insights for complex financial tasks, ultimately leading to more robust and reliable AI-driven financial solutions.
UniFinEval is poised to become a cornerstone in the advancement of financial artificial intelligence, offering a standardized and rigorous platform for evaluating and comparing the capabilities of emerging models. By providing a challenging and comprehensive benchmark, it directly incentivizes the development of more sophisticated AI systems capable of nuanced financial reasoning and decision-making. This, in turn, paves the way for truly intelligent financial assistants – tools that can not only process and analyze vast datasets, but also understand the complex interplay of economic factors and provide personalized, insightful guidance. The benchmark’s continued use will foster iterative improvements, accelerating the creation of AI solutions that enhance financial planning, risk management, and investment strategies for individuals and institutions alike.

UniFinEval attempts precision. It pares down evaluation to essential components, acknowledging that abstractions age, principles don’t. The benchmark’s focus on cross-modal reasoning within high-information density financial data mirrors a commitment to fundamental clarity. As Immanuel Kant stated, “All our knowledge begins with the senses.” This aligns with UniFinEval’s reliance on diverse inputs – text, images, and videos – to test a model’s grasp of financial concepts. Every complexity needs an alibi; UniFinEval provides a rigorous structure to justify evaluation criteria, ensuring models aren’t merely impressive, but demonstrably competent.
What Remains?
The proliferation of multimodal large language models has, predictably, outstripped the capacity to meaningfully assess them. UniFinEval represents a necessary, if belated, attempt to impose order. Yet, the benchmark itself does not solve the fundamental problem. It merely refines the question. If a model successfully navigates the curated complexity of a financial task – interpreting charts, extracting data from reports, correlating video commentary with textual analysis – has it truly understood anything? Or has it simply become adept at pattern matching within a pre-defined, high-information density environment?
Future work must resist the temptation to add further layers of complexity. Instead, it should focus on subtraction. The true test will not be the ability to process more data, but to identify the essential information. A model that can distill a quarterly report down to its core implications, independent of superficial visual or auditory cues, is a model approaching genuine understanding. Such a pursuit demands a shift in emphasis: from building ever-larger models to designing more rigorous, minimalist evaluations.
Ultimately, the field needs to confront the uncomfortable possibility that current benchmarks – even those striving for unification – are measuring proficiency in solving problems, not comprehension of the underlying principles. The pursuit of artificial intelligence should not be about building machines that appear intelligent, but about understanding what intelligence itself actually is. A seemingly modest goal, perhaps, but one far more challenging – and far more worthwhile – than simply adding another data modality.
Original article: https://arxiv.org/pdf/2601.22162.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- EUR ZAR PREDICTION
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
2026-02-02 22:04