Author: Denis Avetisyan
A new approach integrates spectral decomposition into diffusion models to improve the accuracy of long-term time-series predictions.
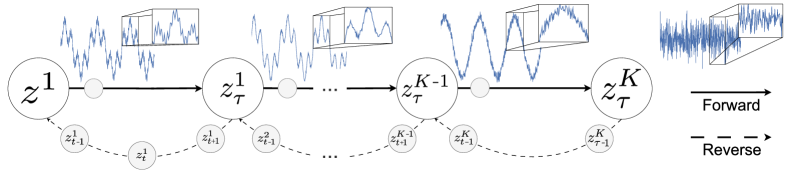
This review details a decomposable forward process within diffusion models that preserves signal structure for enhanced time-series forecasting performance.
While diffusion models have emerged as powerful tools for time-series forecasting, preserving long-term dependencies and structured patterns remains a challenge. This is addressed in ‘A Decomposable Forward Process in Diffusion Models for Time-Series Forecasting’, which introduces a model-agnostic approach that decomposes time-series signals into spectral components during the forward diffusion process. By strategically injecting noise based on component energy, the method maintains signal fidelity and improves the recoverability of crucial temporal features. Could this spectral decomposition strategy unlock further improvements in diffusion-based forecasting, particularly for complex, multi-scale time-series data?
Unveiling Temporal Dynamics: The Challenge of Complex Prediction
The ability to accurately predict future events based on historical data-time series forecasting-is fundamentally important across a surprisingly broad spectrum of disciplines, from financial markets and climate modeling to supply chain logistics and even epidemiology. However, many conventional forecasting techniques, such as autoregressive integrated moving average (ARIMA) models, encounter significant limitations when confronted with time series exhibiting complex, non-linear patterns and long-range dependencies. These methods often assume relatively simple relationships within the data, struggling to discern subtle influences that occur over extended periods, and thus failing to anticipate shifts or anomalies. The consequence is frequently diminished predictive power, necessitating the development of more sophisticated approaches capable of unraveling these intricate temporal dynamics and improving the reliability of future projections.
The predictive power of time series analysis is frequently compromised by the interplay of inherent patterns and extraneous noise. While trends and seasonality establish underlying structure, these signals are often masked by residual variations-random fluctuations or unexplained anomalies within the data. This obfuscation poses a significant challenge, as standard forecasting models struggle to differentiate between genuine dependencies and inconsequential noise, leading to diminished accuracy and unreliable predictions. Consequently, advanced techniques are needed to effectively filter noise and isolate the core drivers of temporal change, ultimately improving the robustness and reliability of time series forecasts across various disciplines.
Conventional time series analysis often stumbles when confronted with data exhibiting complex internal structures. Many established forecasting techniques presume relatively simple relationships-linear trends or readily identifiable seasonal patterns-and subsequently struggle to discern the nuanced, hierarchical dependencies inherent in real-world data. This inability to accurately model the underlying data-generating process manifests as persistent forecast errors, particularly over extended prediction horizons. The issue isn’t simply a lack of data, but a limitation in the algorithms’ capacity to disentangle genuine signals from noise and represent the intricate, often non-linear, relationships that govern the series’ behavior. Consequently, predictions can be significantly off-target, impacting decisions in fields ranging from financial markets to climate modeling, highlighting the need for more sophisticated analytical tools.

Deconstructing the Temporal Landscape: Isolating Core Components
Time series decomposition is a pre-processing step in forecasting that disaggregates a single time series into its underlying components. These components typically include the trend, representing the long-term direction of the series; seasonality, denoting repeating patterns within a fixed period; and residual noise, which encapsulates the remaining random variation. By isolating these components, analysts can better understand the drivers of the series and potentially improve the accuracy of forecasts, as each component can be modeled and projected independently. The general form of decomposition can be expressed as: y(t) = Trend(t) + Seasonality(t) + Residual(t) , where y(t) is the observed time series at time t .
Fourier Decomposition analyzes time series by transforming them into their constituent frequencies, effectively representing the signal as a sum of sine and cosine waves – it excels at identifying dominant, consistent frequencies. Wavelet Decomposition, conversely, utilizes wavelets – localized waves – to analyze signals at different scales and resolutions, providing better time-frequency localization. This makes Wavelet Decomposition particularly effective for non-stationary signals where frequencies change over time, as it can pinpoint when specific frequencies occur, a capability Fourier Decomposition lacks. The choice between the two depends on the signal characteristics; Fourier is suitable for stationary signals with consistent frequencies, while Wavelet is preferred for transient signals or those with time-varying frequency content. Both methods output frequency-domain representations, but their differing approaches to signal analysis result in varying degrees of accuracy and interpretability for different time series data.
Assessing the quality of time series decomposition is essential for accurate forecasting and analysis, and is frequently performed using the Signal-to-Noise Ratio (SNR). SNR quantifies the strength of the desired signal components – trend and seasonality – relative to the background noise or residual error. A higher SNR indicates a clearer separation of components, suggesting the decomposition effectively isolates the meaningful patterns within the data. SNR is calculated as the ratio of the power of the signal to the power of the noise; this can be expressed as SNR = 10 \log_{10} \frac{P_{signal}}{P_{noise}}, where P_{signal} and P_{noise} represent the signal and noise power, respectively. Low SNR values suggest the decomposition may be ineffective, potentially requiring adjustments to the decomposition method or parameters to improve component clarity and the reliability of subsequent analyses.

Generative Forecasting: Shaping Probabilistic Futures
Diffusion processes, utilized in time series forecasting as a generative modeling technique, operate by learning the probability distribution of observed data and subsequently sampling from this distribution to generate future values. These processes involve a forward diffusion stage, where data is progressively corrupted with Gaussian noise, and a reverse diffusion stage, where the model learns to denoise the data, effectively reconstructing the underlying distribution. By iteratively applying this denoising process, the model can generate plausible future time steps, providing a probabilistic forecast that reflects the uncertainty inherent in the data. The core principle relies on modeling the conditional probability of a time series value given its past, enabling the generation of forecasts beyond the observed data horizon. p(x_t | x_{t-1}) represents the conditional probability at each step, learned through training on historical data.
The Structured Forward Diffusion Process improves forecasting accuracy by explicitly modeling time series decomposition during the diffusion learning phase. Instead of directly applying diffusion to the raw time series data, the process operates on three distinct components: trend, seasonality, and residual noise, each obtained through decomposition techniques like Seasonal-Trend decomposition using Loess (STL). This component-wise diffusion allows the model to learn the separate dynamics of each element, capturing long-term trends, recurring seasonal patterns, and unpredictable fluctuations independently. By conditioning the generative process on these decomposed components, the model achieves a more refined understanding of the underlying data distribution and generates probabilistic forecasts that reflect the unique characteristics of each component.
By decomposing the time series into trend, seasonality, and residual noise, the structured diffusion process facilitates the capture of long-range dependencies that traditional methods may miss. This decomposition allows the model to learn the individual components’ dynamics and their interactions, improving forecasting accuracy over extended horizons. Furthermore, the diffusion process inherently generates probabilistic forecasts, providing not just point predictions but also a distribution representing the uncertainty associated with each prediction; this is achieved through the iterative denoising process which samples from the learned data distribution, enabling the quantification of forecast confidence intervals and the assessment of potential future scenarios.

Validating the Approach: Achieving State-of-the-Art Performance
The efficacy of the proposed forecasting model underwent rigorous testing utilizing the PTB-XL Dataset, a widely recognized and exceptionally demanding benchmark in the field of clinical time series analysis. This dataset, comprised of extensive physiological measurements collected from critical care patients, presents substantial challenges due to its complexity, high dimensionality, and the inherent uncertainty associated with clinical data. By evaluating performance specifically on PTB-XL, researchers ensured the model’s capabilities were assessed against a gold standard, enabling a robust and meaningful comparison with established forecasting techniques. The dataset’s difficulty stems from both the sheer volume of data points and the subtle, yet critical, patterns within the time series, requiring a model capable of discerning complex relationships to accurately predict future clinical states.
Rigorous evaluation of the proposed model utilized both Continuous Ranked Probability Score (CRPS) and Mean Squared Error (MSE) to quantify forecasting accuracy on the PTB-XL dataset. Lower values for these metrics indicate superior performance, and the results demonstrate a substantial advancement over established methods. Specifically, the model consistently achieved reductions in both CRPS and MSE, indicating improved calibration of probabilistic forecasts and a tighter fit to observed data. This improvement isn’t merely incremental; it signifies a notable step towards more reliable and precise clinical time series forecasting, potentially impacting the quality of data-driven decisions in healthcare settings. The consistent outperformance across these key metrics validates the efficacy of the proposed approach and its ability to address the challenges inherent in complex clinical data.
The capacity to produce reliable probabilistic forecasts represents a significant advancement with practical implications across numerous fields. Unlike deterministic predictions that offer a single outcome, this model delivers a range of possible future values alongside their associated probabilities, enabling more informed and nuanced decision-making. In clinical settings, for instance, these forecasts allow medical professionals to assess risks and tailor treatment plans based on the likelihood of different patient outcomes. Similarly, in resource management, probabilistic forecasts facilitate proactive planning by quantifying the uncertainty surrounding future demand. This nuanced approach, moving beyond simple predictions, empowers stakeholders to not only anticipate potential scenarios but also to evaluate the potential consequences of various actions, ultimately leading to more robust and effective strategies.
Beyond Prediction: Laying the Foundation for Advanced Analysis
Combining the structured diffusion process with established architectures like State Space Models presents a compelling pathway toward enhanced time series analysis. This integration leverages the strengths of both methodologies: diffusion’s capacity for generating plausible sequences and State Space Models’ efficiency in capturing long-range dependencies. By embedding the diffusion process within the state representation of these models, researchers aim to improve both the performance and scalability of time series forecasting. This allows for a more nuanced understanding of temporal data, particularly in complex systems where relationships aren’t immediately apparent, and opens possibilities for real-time applications requiring rapid and accurate predictions. The synergy between these approaches could potentially overcome limitations of traditional methods, enabling the development of more robust and adaptable time series models.
The synergy between Variational Autoencoders (VAEs) and diffusion processes presents a compelling avenue for advancements in time series representation learning. VAEs excel at distilling complex data into lower-dimensional latent spaces, capturing essential features while reducing noise; however, these latent spaces can sometimes lack the nuanced detail necessary for accurate time series modeling. Integrating diffusion processes addresses this limitation by enriching the VAE’s latent space with stochasticity and iterative refinement. This combined approach allows the model to not only compress the time series data but also to learn a more robust and generative representation, effectively ‘diffusing’ information into a richer, more expressive latent structure. Consequently, this improved representation facilitates superior performance in tasks such as anomaly detection, forecasting, and time series generation, as the model can better capture the underlying dynamics and dependencies within the data.
The development of this structured diffusion process establishes a resilient base for crafting advanced time series models, moving beyond simple forecasting to capture intricate relationships within data. By framing time series analysis as a controlled, probabilistic transformation, the approach effectively addresses the challenges posed by complex dependencies – patterns where past values significantly influence future outcomes in non-linear ways. This allows for the creation of models capable of not only predicting future values with greater accuracy, but also of generating plausible scenarios and quantifying uncertainty. The resulting framework facilitates reliable predictions even when confronted with noisy or incomplete data, offering a significant step forward in fields ranging from financial forecasting and climate modeling to medical diagnostics and anomaly detection.

The research detailed within this paper elegantly demonstrates how complex systems needn’t be governed by overarching design. Instead, forecasting accuracy improves through the decomposition of time-series data-allowing structured components to persist through the diffusion process. This aligns with the observation that order emerges from local rules, rather than imposed control. As Ludwig Wittgenstein stated, “The limits of my language mean the limits of my world.” Similarly, the limitations of traditional forecasting methods stem from an inability to adequately represent the underlying structure of time-series data. By focusing on preserving these inherent spectral components, the model expands the ‘world’ of possible accurate predictions, particularly for long-horizon forecasting, showcasing how small, localized improvements in representation can yield substantial global effects.
Where Do the Waves Lead?
The integration of spectral decomposition within diffusion models, as demonstrated, suggests a move beyond treating time-series data as monolithic entities. Order manifests through interaction, not control; the preservation of structured components isn’t a matter of imposing architecture, but of allowing inherent frequencies to persist through the noising process. Future work needn’t focus solely on refining the diffusion steps, but on more nuanced spectral analyses-methods that adapt to the evolving frequencies within the forecast horizon, rather than relying on static pre-processing.
A persistent challenge remains the computational expense. The very act of decomposition, while beneficial for signal fidelity, adds layers of complexity. It is tempting to seek ever-more-efficient algorithms, but perhaps a more fruitful path lies in accepting a degree of approximation-recognizing that perfect reconstruction is neither necessary nor achievable. Sometimes inaction is the best tool; a strategically ignored frequency may prove less detrimental than the computational cost of preserving it.
Ultimately, this line of inquiry points towards a broader shift. The pursuit of increasingly complex models often obscures a simple truth: information isn’t added by complexity, it’s revealed through appropriate interaction. The future likely holds hybrid approaches-diffusion models not as standalone predictors, but as components within larger systems that leverage the strengths of multiple paradigms. The waves will not cease, only reshape.
Original article: https://arxiv.org/pdf/2601.21812.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
2026-01-30 23:32