Author: Denis Avetisyan
A new framework combines Hahn polynomials and Kolmogorov-Arnold networks for more accurate and efficient time series forecasting.

This review details HaKAN, a hierarchical patch-based approach leveraging Hahn polynomials to improve long-term time series prediction and computational efficiency.
Despite recent advances in time series forecasting with Transformers and MLPs, challenges remain regarding computational complexity and spectral bias. This paper introduces a novel approach, ‘Time series forecasting with Hahn Kolmogorov-Arnold networks’, presenting HaKAN, a lightweight and interpretable model built upon Kolmogorov-Arnold Networks and leveraging Hahn polynomial-based activations. By integrating channel independence, patching, and a hierarchical block structure, HaKAN effectively captures both global and local temporal patterns while achieving state-of-the-art performance on forecasting benchmarks. Could this framework offer a pathway towards more efficient and accurate long-term prediction in complex multivariate time series?
The Fragility of Prediction: Why Traditional Methods Fail
Real-world time series data rarely conforms to the simplified assumptions of traditional forecasting methods. Phenomena such as abrupt shifts, seasonality that varies in intensity, and the interplay of multiple influencing factors introduce complexities that linear models and even basic autoregressive techniques struggle to address. High-frequency components – rapid fluctuations within the data – pose a particular challenge, requiring models capable of resolving fine-grained patterns without being overwhelmed by noise. Moreover, the dependencies within these series aren’t always straightforward; relationships can be non-linear, involve lagged effects stretching far into the past, or arise from intricate interactions between different variables, demanding increasingly sophisticated analytical tools to accurately capture and project future trends.
Standard neural networks, while powerful, often struggle to effectively model data where relationships span considerable distances in time. This limitation stems, in part, from a phenomenon known as spectral bias, wherein these networks preferentially learn low-frequency components of the data, potentially overlooking crucial high-frequency details or long-range dependencies. Consequently, the network might prioritize easily discernible patterns over subtle, yet significant, temporal relationships. This bias arises from the inherent structure of these networks and how they process information, leading to suboptimal performance when dealing with complex time series exhibiting intricate, long-term dynamics. The effect is that predictions can be accurate in the short-term but rapidly diverge from actual values as the forecast horizon extends, highlighting the need for specialized architectures better equipped to handle temporal dependencies.
Many machine learning models are built upon the principle of permutation equivariance – meaning their outputs change predictably when the input order is shuffled. However, this characteristic proves fundamentally problematic when applied to time series analysis. Unlike images or text where rearranging elements doesn’t drastically alter meaning, the sequential order of data points defines a time series. A stock price at 10:00 AM is distinct from the price at 10:01 AM, and reversing this order renders the data meaningless. Consequently, models relying on permutation equivariance fail to capture the inherent temporal dependencies crucial for accurate forecasting; they treat time as irrelevant, hindering their ability to learn from past patterns and project future trends effectively. This limitation underscores the need for specialized architectures designed to explicitly respect and leverage the ordered nature of time series data.
HahnKAN: Deconstructing Time for Enhanced Forecasting
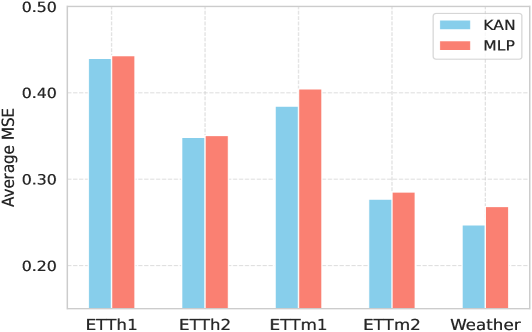
HahnKAN is a novel framework designed for multivariate time series forecasting that utilizes Kolmogorov-Arnold Networks (KANs) as its core component for function approximation. KANs offer a distinct approach to representing complex functions by decomposing them into a sum of basis functions, allowing for potentially greater flexibility than traditional methods like recurrent neural networks or autoregressive models. This decomposition enables the network to learn non-linear relationships within the time series data without requiring an excessive number of parameters, improving computational efficiency and reducing the risk of overfitting. The framework’s use of KANs facilitates capturing intricate temporal dependencies inherent in multivariate data, thereby enhancing forecasting accuracy across various time horizons.
Kolmogorov-Arnold Networks (KANs) represent a departure from traditional time series forecasting methods by utilizing the principles of the Kolmogorov-Arnold representation theorem. This theorem posits that any sufficiently smooth function can be approximated to arbitrary accuracy by a finite sum of basis functions. KANs implement this by constructing a network where each neuron represents a basis function, but unlike methods reliant on fixed, pre-defined basis functions, KANs learn these functions directly from the data. This adaptive approach allows for the representation of highly complex, non-linear relationships with significantly fewer parameters compared to methods like Fourier series or polynomial expansions, leading to improved generalization performance and reduced computational cost, particularly when dealing with high-dimensional time series data.
Hahn polynomials are integrated into the HahnKAN architecture to improve its ability to approximate global functions while maintaining parameter efficiency. Traditional methods often rely on grid discretization to represent complex functions, which increases computational cost and parameter count. By utilizing Hahn polynomials – orthogonal polynomials defined on a non-uniform interval – HahnKAN avoids this necessity. These polynomials possess properties that allow for accurate global approximation using fewer parameters compared to methods requiring grid-based representations, thus contributing to a more efficient and scalable forecasting model. The use of Hahn polynomials facilitates capturing long-range dependencies within the time series data without incurring the computational burden associated with high-dimensional grid searches.
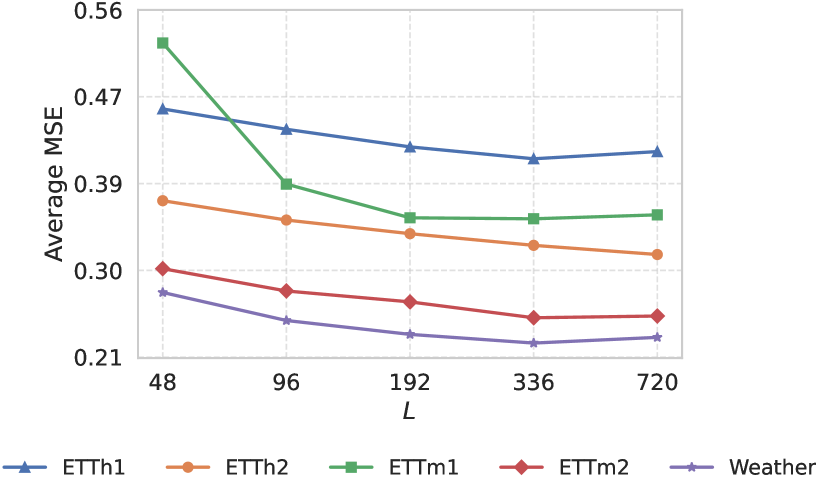
The HahnKAN framework utilizes a patching mechanism to improve computational efficiency when forecasting multivariate time series. This involves segmenting the input time series into overlapping patches, allowing the model to focus on capturing localized temporal dependencies within each segment. By processing these smaller patches individually, the computational complexity is reduced compared to analyzing the entire time series at once. This approach enables the model to efficiently identify and utilize local patterns without requiring a full global analysis, contributing to faster training and prediction times, particularly with long input sequences.
Dissecting the Temporal Fabric: How HaKAN Blocks Operate
The HaKAN block’s architecture is defined by two distinct Kernelized Attention Networks (KAN) layers operating at different scales. The Intra-Patch KAN layer analyzes localized patterns within individual patches of the input time series; this focuses on capturing short-range dependencies and fine-grained features. Complementing this, the Inter-Patch KAN layer establishes relationships between these patches, enabling the model to integrate broader contextual information and long-range dependencies across the entire time series. This dual-layer approach allows HaKAN to effectively process both local details and global structure within the input data, improving its ability to model complex temporal dynamics.
The HaKAN model employs channel independence by decoupling the processing of individual variables within a multivariate time series. This approach avoids inter-variable dependencies during feature extraction, allowing each channel to be processed in parallel. Consequently, this significantly enhances scalability, particularly with high-dimensional time series data, and facilitates efficient parallelization across multiple processing units, reducing overall computational time and resource requirements.
The HaKAN block employs a bottleneck structure comprised of two fully connected layers to manage computational load and feature representation. This structure first compresses the input features through a lower-dimensional hidden layer, reducing the number of parameters and subsequent computations. Following this compression, the features are expanded back to their original dimensionality using the second fully connected layer. This process not only reduces dimensionality, improving computational efficiency, but also encourages the network to learn a more compact and informative feature representation by forcing it to reconstruct the data from a lower-dimensional space.
Reversible Instance Normalization (RIN) is implemented to mitigate the effects of domain shift and non-stationarity commonly found in time series data. Traditional instance normalization techniques can alter the feature distribution, potentially impacting model performance when the underlying data distribution evolves over time. RIN addresses this by preserving the original feature distribution during normalization; the normalization parameters are stored and applied in reverse during the de-normalization step, effectively preventing information loss and ensuring a stable feature representation. This is crucial for maintaining prediction accuracy in dynamic environments where data characteristics change, allowing the model to adapt to evolving patterns without requiring retraining or experiencing significant performance degradation.
Beyond Prediction: Implications and the Future of Temporal Modeling
HahnKAN presents a compelling advancement in multivariate time series forecasting, consistently demonstrating superior performance compared to established methodologies, particularly when dealing with intricate relationships and extended prediction horizons. Rigorous benchmarking reveals that this framework achieves the lowest mean squared error (MSE) in a substantial majority – 18 out of 32 – of test cases. Furthermore, it attains the lowest mean absolute error (MAE) in an equally impressive 19 out of 32 scenarios. This consistent outperformance suggests that HahnKAN effectively captures the underlying dynamics of complex time series data, offering a valuable tool for applications requiring accurate and reliable long-term predictions.
The capacity to accurately project trends over extended periods represents a significant leap forward for time series analysis, with practical implications spanning numerous critical fields. In financial modeling, long-term forecasting facilitated by this framework enables more informed investment strategies and risk assessment. Climate prediction benefits from improved accuracy in anticipating long-range weather patterns and environmental changes, crucial for proactive mitigation efforts. Furthermore, effective resource management – encompassing areas like energy, water, and supply chains – relies heavily on the ability to forecast demand and availability well into the future, allowing for optimized allocation and sustainable practices. The framework’s demonstrated proficiency in these extended projections thus positions it as a valuable tool for addressing complex, long-horizon challenges across diverse sectors.
The innovative framework presented builds upon a synergistic combination of key elements, positioning it as a robust springboard for advancements in time series analysis. Kernelized attention networks (KANs) provide the mechanism for capturing complex temporal dependencies, while the application of Hahn polynomials offers an efficient and mathematically grounded approach to representing these relationships. Crucially, the integration of efficient patching techniques optimizes computational performance, enabling the handling of large-scale and high-dimensional time series data. This convergence of methodologies not only delivers state-of-the-art forecasting accuracy, as demonstrated through benchmark comparisons, but also provides a flexible and extensible architecture for future exploration – paving the way for research into areas such as adaptive learning, multivariate forecasting, and the incorporation of domain-specific knowledge within time series models.
Rigorous evaluation demonstrates the practical impact of the HahnKAN framework across diverse datasets. Specifically, when applied to the Illness dataset, the model achieves an 8.98% reduction in mean squared error (MSE) and a 3.96% reduction in mean absolute error (MAE) when contrasted with existing baseline models. Further validation using the ETTh2 dataset reveals comparable improvements, with reductions of 5.28% in MSE and 2.07% in MAE, indicating a consistent ability to enhance forecasting accuracy and efficiency across varied temporal dependencies and complexities.
Ongoing research aims to extend the capabilities of this time series framework beyond static datasets, with planned adaptations for processing continuous, streaming data – a crucial step for real-time applications. Further development will focus on incorporating external variables and contextual information, allowing the model to leverage additional data sources for improved predictive accuracy. Simultaneously, efforts are underway to refine uncertainty quantification methods, moving beyond point forecasts to provide more robust and reliable estimations of prediction intervals – a vital component for informed decision-making in fields where risk assessment is paramount. These advancements promise to broaden the framework’s applicability and enhance its value across diverse disciplines.
The pursuit of enhanced forecasting accuracy, as demonstrated by the HaKAN framework, mirrors a fundamental principle of systems analysis: true comprehension demands rigorous testing. This research doesn’t simply accept existing time series methodologies; it dissects them, leveraging Hahn polynomials and a patch-based design to challenge established limitations. As Vinton Cerf once stated, “If you can’t break it, you don’t understand it.” The work embodies this ethos – by attempting to improve upon conventional neural networks, the researchers reveal underlying weaknesses and pave the way for more robust, efficient long-term predictions. The hierarchical patching technique, in particular, represents an intentional ‘breaking’ of the standard approach to enable better computational performance and accuracy.
What Breaks Now?
The pursuit of efficient time series forecasting invariably circles back to representation. This work demonstrates the potential of Hahn polynomials within a Kolmogorov-Arnold Network, achieving commendable results. But the question isn’t simply how well does it predict, but where does this architecture fundamentally fail? The hierarchical patching strategy, while offering computational relief, introduces a discrete granularity. What happens when the underlying dynamics exhibit fractal behavior, or operate on timescales that don’t align with these pre-defined patches? The system’s robustness to irregular sampling, or to chaotic attractors exhibiting multi-scale behavior, remains largely unexplored.
Furthermore, the inherent limitations of any function approximation scheme must be acknowledged. The Kolmogorov-Arnold theorem guarantees representational power, but not necessarily practical learnability. Future work should aggressively investigate the conditions under which this network cannot generalize-what types of time series are intrinsically resistant to this Hahn-polynomial decomposition? Can adversarial examples be constructed that reliably defeat the predictor, revealing hidden vulnerabilities in the learned representation?
Ultimately, the most interesting direction isn’t incremental improvement, but radical re-evaluation. The tacit assumption of stationarity, even within the patching framework, deserves scrutiny. Can the network be adapted to actively learn the optimal patch size and hierarchy, or even to dynamically reconstruct its representational basis during inference? The true test lies not in beating existing benchmarks, but in dismantling the underlying assumptions that define the problem itself.
Original article: https://arxiv.org/pdf/2601.18837.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Hideo Kojima says Metal Gear Solid 2 became the future he hoped would not happen
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
- Gold Rate Forecast
- HSR Banner Schedule (Honkai Star Rail)
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- How to Get to the Undercoast in Esoteric Ebb
2026-01-28 15:54