Author: Denis Avetisyan
New research demonstrates a method for improving the reliability of AI agents by transforming failed actions into valuable learning opportunities.
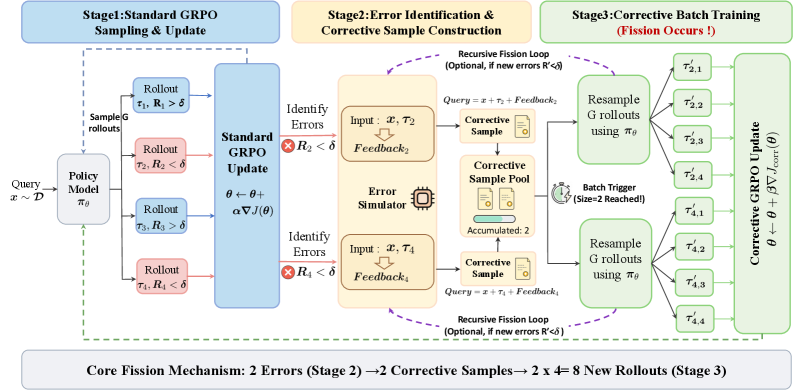
The Fission-GRPO framework uses reinforcement learning to enhance error recovery in language model-based tool-using agents, improving robustness and performance.
While large language models demonstrate increasing proficiency in tool use, their brittleness following execution errors remains a significant obstacle to reliable real-world deployment. This limitation is addressed in ‘Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors’, which introduces Fission-GRPO, a novel reinforcement learning framework that transforms these errors into corrective supervision signals. By augmenting failed trajectories with diagnostic feedback from a finetuned error simulator and resampling recovery rollouts on-policy, Fission-GRPO enables models to learn from their specific mistakes, yielding substantial improvements in error recovery and overall accuracy-a 4\% gain on the BFCL v4 Multi-Turn benchmark. Could this approach unlock more robust and adaptable agents capable of navigating the inherent uncertainties of complex tool-use scenarios?
The Fragility of Order: Tool Use and Temporal Decay
Despite remarkable advancements in natural language processing, Large Language Models (LLMs) frequently exhibit inconsistent performance when tasked with utilizing external tools. While capable of generating coherent instructions and understanding tool functionalities, these models struggle to reliably execute complex tasks requiring sustained interaction. The issue isn’t necessarily a lack of foundational knowledge, but rather a brittleness in applying that knowledge across varied scenarios and a difficulty in maintaining consistent accuracy over multiple steps. This inconsistency stems from the models’ reliance on pattern recognition within training data; when faced with unforeseen circumstances or slight deviations from familiar input, performance can degrade significantly, highlighting a crucial gap between theoretical capability and practical, dependable tool use.
A significant obstacle to reliable performance with Large Language Models lies in their limited capacity to gracefully recover from errors encountered during interactions with external tools. While these models can often initiate tool use successfully, a single failed attempt – a tool returning an unexpected result, or an API call failing – frequently derails the entire process. Unlike humans who intuitively diagnose and correct mistakes, LLMs often lack the mechanisms to detect these failures, adjust their strategy, or retry with modified parameters. This fragility stems from a reliance on pre-defined sequences and a difficulty in adapting to unforeseen circumstances, meaning even simple tasks can be rendered incomplete due to an inability to effectively troubleshoot and resume operation after an initial setback. Consequently, improving error recovery is crucial for building LLM-powered agents capable of dependable and consistent task completion in real-world scenarios.
The efficacy of large language models in real-world applications is increasingly challenged by the limitations of their training data; conventional methods often depend on static datasets that fail to reflect the dynamic nature of the environments they operate within. As policies governing tool use and external systems are updated, or as the systems themselves evolve, the models’ knowledge becomes quickly outdated, creating a ‘stale’ learning environment. This misalignment between training and operational conditions leads to decreased performance, as the models struggle to generalize to novel situations or adapt to changes in the external world. Consequently, continuous learning and the incorporation of feedback mechanisms are crucial for maintaining robust tool use and ensuring these models remain effective over time.
Successful interaction with external tools hinges on an agent’s ability to meticulously monitor and interpret its environment – a process known as state tracking. This isn’t merely about recording raw data; it demands a nuanced understanding of how each tool interaction alters the surrounding context and influences future actions. Without precise state tracking, an agent may misinterpret results, repeat ineffective commands, or fail to recognize when a task has deviated from its intended path. Consequently, robust tool use necessitates a dynamic internal representation of the world, allowing the agent to anticipate, adapt to, and recover from unexpected outcomes – essentially building a cognitive map that persists through a sequence of interactions and informs subsequent decision-making.
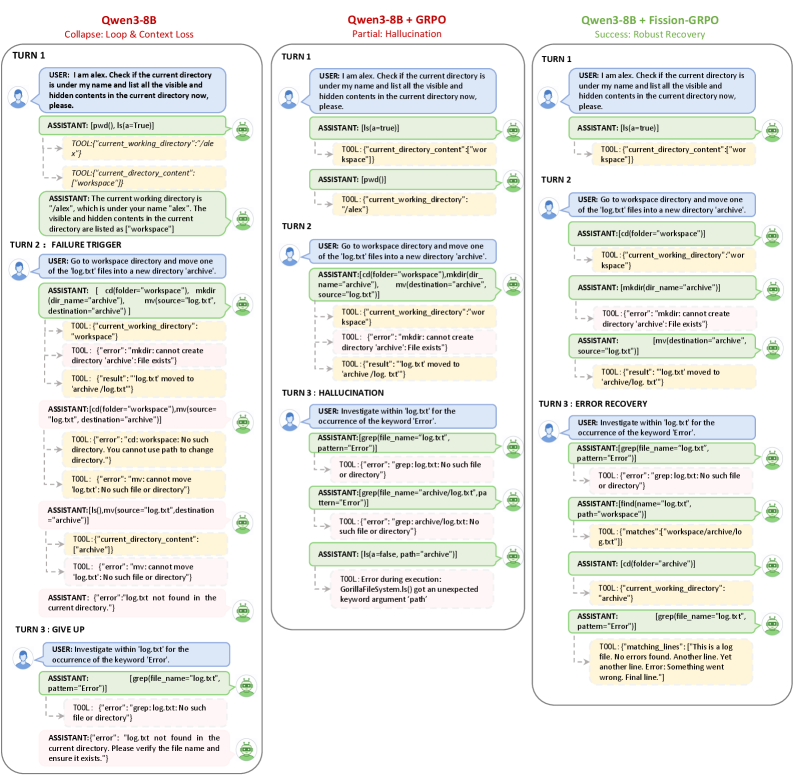
Corrective Supervision: Imposing Order on Systemic Errors
Fission-GRPO employs a novel framework to transform runtime execution errors into a form of dense, on-policy-aligned ‘Corrective Supervision’. This process involves capturing error events and converting them into actionable feedback signals used to directly update the agent’s policy. Unlike traditional error handling which often focuses on halting execution or providing minimal diagnostic information, Fission-GRPO generates detailed, context-specific supervision signals from errors. This enables the agent to learn from its mistakes in real-time, improving its ability to recover from and prevent future errors without requiring explicit human intervention or pre-defined recovery strategies. The on-policy alignment ensures that the learned corrections are directly relevant to the agent’s current behavioral policy, maximizing the efficiency of the learning process.
The Fission-GRPO system incorporates an Error Simulator, implemented using Large Language Models (LLMs), to produce diagnostic feedback that enhances error recovery capabilities. This simulator functions by receiving information about execution errors and generating detailed, contextually relevant feedback signals. The LLM is utilized to create realistic error descriptions and potential corrective actions, going beyond simple error codes to provide nuanced diagnostic information. This generated feedback is then used to train the agent, improving its ability to identify, understand, and recover from similar errors in future executions, thereby increasing system robustness and adaptability.
Fission-GRPO represents an advancement of the Generalized Rollout Policy Optimization (GRPO) framework by integrating dynamic error correction capabilities. GRPO traditionally relies on pre-defined recovery strategies; Fission-GRPO extends this by enabling the agent to learn from and adapt to errors encountered during execution. This is achieved through the generation of corrective supervision signals derived from runtime errors, effectively transforming failures into learning opportunities. The core GRPO algorithms for policy optimization and rollout management remain central to Fission-GRPO, but are augmented by the error-driven learning process, resulting in a more robust and adaptable system.
On-Policy Learning, as implemented within Fission-GRPO, facilitates agent improvement through direct interaction with its environment and subsequent learning from the resulting experiences. This contrasts with off-policy methods which learn from pre-collected data; on-policy learning ensures that the policy being updated is the same policy used to generate the experiences. Consequently, the agent’s learning process remains highly relevant to its current state and actions, promoting adaptability to dynamic environments and novel situations. The immediacy of feedback derived from its own execution allows for rapid refinement of the policy, maximizing performance gains and minimizing the impact of distributional shift between training and deployment.

Empirical Validation: Observing Resilience in Dynamic Systems
The Fission-GRPO agent was subjected to evaluation using the BFCL v4 Multi-Turn Benchmark, a testing suite specifically designed to assess the robustness of agents interacting with tools across multiple conversational turns. This benchmark presents a challenging environment due to its complexity and the need for consistent and accurate tool usage throughout extended dialogues. BFCL v4 distinguishes itself from simpler benchmarks by requiring agents to not only successfully utilize tools initially, but also to maintain functionality and recover from potential errors that occur during the course of a multi-turn interaction, providing a more realistic measure of agent reliability in complex scenarios.
Performance evaluations of Fission-GRPO were conducted against established baseline methods, specifically DAPO and Dr.GRPO, to quantify improvements in tool-using agent robustness. These comparative analyses revealed statistically significant gains achieved by Fission-GRPO; notably, an overall accuracy increase of 4% was observed, elevating performance from 42.75% to 46.75%. Furthermore, the Error Recovery Rate demonstrated a 5.7% improvement, indicating a heightened capacity to successfully navigate and correct errors encountered during interactions with external tools. These results consistently positioned Fission-GRPO as a superior performing model when benchmarked against these existing methodologies.
Quantitative evaluation on the BFCL v4 Multi-Turn Benchmark demonstrates that Fission-GRPO achieves a 4% absolute gain in overall accuracy, increasing performance from 42.75% to 46.75%. Furthermore, Fission-GRPO exhibits a 5.7% improvement in Error Recovery Rate, signifying a statistically significant enhancement in its capacity to successfully navigate and resolve errors encountered during interactions with external tools. This improved error recovery directly contributes to a more robust and reliable agent performance in complex, multi-turn scenarios.
Evaluation using the Qwen3 Model Family revealed substantial performance gains with Fission-GRPO. The Qwen3-1.7B model exhibited a relative improvement exceeding 160% compared to the Base model, which initially achieved 7.80% accuracy. Furthermore, testing with the Qwen3-4B model confirmed that Fission-GRPO consistently outperformed alternative methodologies within the same framework, indicating scalability and consistent benefit across different model sizes within the Qwen3 family.

The pursuit of robust tool use, as demonstrated by Fission-GRPO, inherently acknowledges the inevitability of systemic failure. Any complex system, even one employing corrective supervision from execution errors, will accrue a form of ‘memory’ – a record of past failures informing future actions. This aligns with John McCarthy’s observation, “It is often easier to explain why something works than to predict it.” The framework doesn’t eliminate errors, but rather reframes them as valuable data points, allowing the language model to adapt and improve. This acceptance of imperfection and emphasis on learning from it, rather than striving for flawless execution, is crucial for building systems that age gracefully, even amidst inevitable decay.
What’s Next?
The pursuit of robust agency, as exemplified by this work, is less about conquering error and more about accepting its inevitability. Fission-GRPO offers a compelling versioning strategy-a means of retaining valuable experience from failure, effectively building memory into systems designed to operate in imperfect environments. However, the corrective supervision itself remains a bottleneck. The current approach, while effective, relies on simulated errors. The true test will be how well these agents adapt to the unpredictable, and often bizarre, errors that emerge from real-world interaction.
A natural progression lies in exploring methods for intrinsic error detection-allowing the agent to recognize when its actions have diverged from expected outcomes without external prompting. This isn’t merely a technical challenge; it’s a philosophical one. Error signals are, after all, just information. The arrow of time always points toward refactoring, and the most successful agents won’t be those that avoid mistakes, but those that most efficiently transform them into improvements.
Ultimately, the field must grapple with the inherent limitations of current reinforcement learning paradigms. Can a system truly learn to anticipate novel failures, or is it forever bound to react to the past? The enduring question isn’t whether these agents can be made more robust, but whether they can age gracefully – accepting decay as an inherent property of existence, and continually rebuilding from the ruins.
Original article: https://arxiv.org/pdf/2601.15625.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- 币安人生 PREDICTION. 币安人生 cryptocurrency
- EUR USD PREDICTION
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
2026-01-26 02:56