Author: Denis Avetisyan
A new approach to modeling spiking neural networks using hypergraphs promises to dramatically improve how these networks are deployed on specialized neuromorphic hardware.
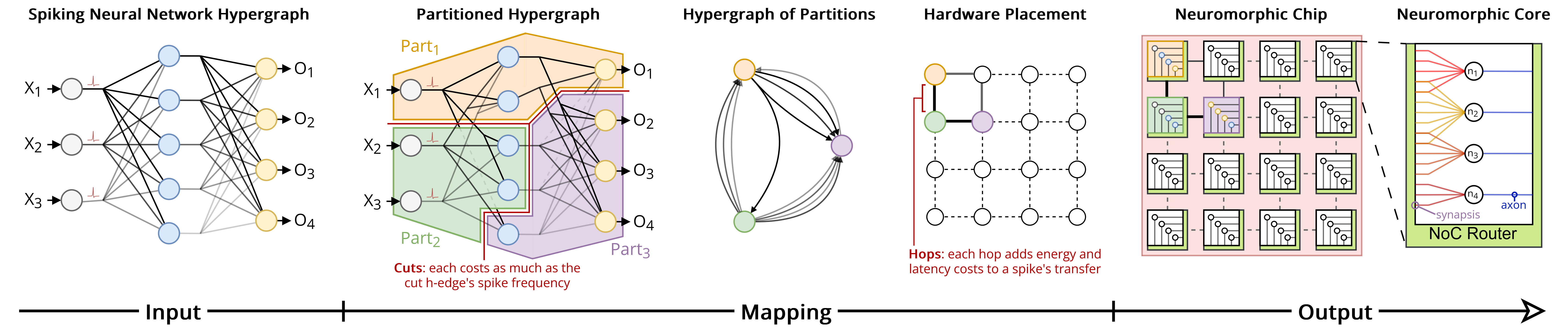
This review details how hypergraph-based partitioning and placement, optimized for synaptic reuse and connections locality, enhances the efficiency of mapping Spiking Neural Networks onto neuromorphic systems.
Mapping increasingly large Spiking Neural Networks (SNNs) onto neuromorphic hardware presents a significant challenge due to the computational complexity of partitioning and placing neurons across limited cores. This work, ‘A Case for Hypergraphs to Model and Map SNNs on Neuromorphic Hardware’, proposes a novel abstraction, representing SNNs as hypergraphs to better capture synaptic reuse and improve mapping efficiency. By explicitly modeling co-membership of neurons within hyperedges, we demonstrate a strong correlation with high-quality mappings and reduced communication traffic. Can this hypergraph-based approach unlock the full potential of neuromorphic computing for truly scalable and bio-plausible neural networks?
Beyond von Neumann: The Inevitable Limits of Conventional Computing
Contemporary computing systems, built upon the von Neumann architecture, face escalating energy consumption when tackling increasingly complex artificial intelligence workloads. This limitation is particularly acute in applications demanding real-time processing, such as autonomous vehicles or advanced robotics, where delays are unacceptable and continuous operation is critical. The fundamental bottleneck lies in the separation of processing and memory; every operation requires data to be fetched from memory, creating a substantial energy cost and limiting computational speed. As AI models grow in size and complexity-necessitating ever-larger datasets and more intricate calculations-the energy demands increase exponentially, hindering deployment on resource-constrained devices and raising concerns about environmental sustainability. This inherent inefficiency motivates the exploration of radically different computational paradigms, like those inspired by the brain’s remarkable energy efficiency.
Spiking Neural Networks represent a paradigm shift in computational design, moving away from the continuous, rate-based signaling of traditional artificial neural networks to a more biologically plausible, event-driven system. Unlike conventional models, SNNs don’t transmit information with constant values; instead, they communicate through discrete spikes – brief pulses of electrical activity. This approach mirrors the brain’s operation, where neurons only fire when a stimulus reaches a certain threshold, resulting in remarkably energy-efficient computation. The sparsity of these spikes-neurons are often inactive-means fewer transistors are engaged, dramatically reducing power consumption. Furthermore, the timing of these spikes isn’t just a byproduct of computation, but carries information itself, opening avenues for temporal coding and potentially more sophisticated processing capabilities. This event-driven nature allows SNNs to excel in real-time tasks and sensory processing, offering a promising pathway toward low-power, intelligent systems.
Realizing the potential of Spiking Neural Networks hinges on their successful implementation on Neuromorphic Hardware, yet this process introduces considerable engineering hurdles. Partitioning, the division of a large network into manageable segments for distribution across multiple hardware cores, becomes exceptionally complex due to the temporal dynamics inherent in spiking signals – a neuron’s firing time is critical information. Simultaneously, placement, determining the physical location of each neuron and synapse on the chip, presents a significant optimization problem; minimizing communication delays and power consumption requires careful consideration of both network topology and hardware constraints. These challenges are compounded by the limited connectivity and resource availability typical of current Neuromorphic systems, demanding novel algorithms and design methodologies to efficiently map complex SNN architectures onto physical substrates and unlock their full computational benefits.
Modeling Complexity: When Simple Graphs Aren’t Enough
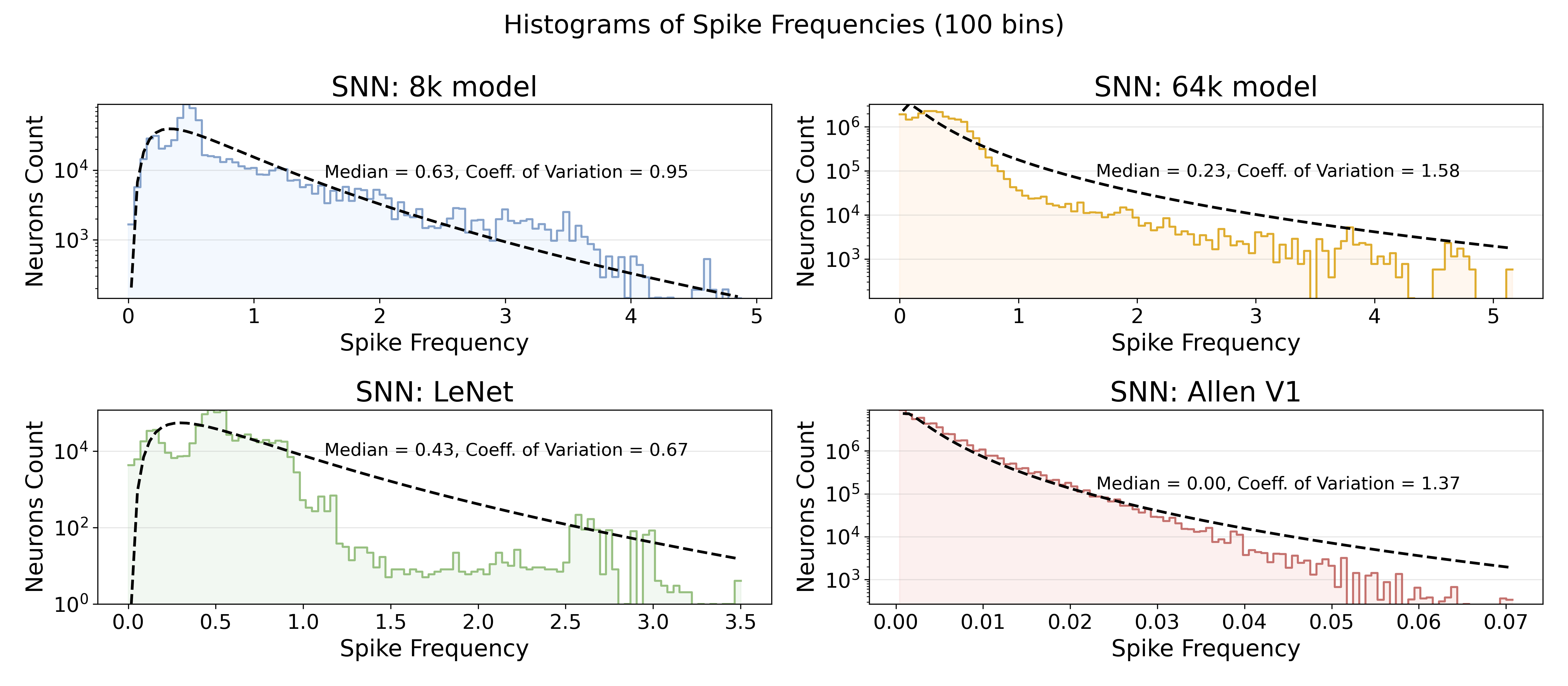
Spiking Neural Networks (SNNs) frequently exhibit connections where a single presynaptic neuron projects to multiple postsynaptic neurons, and conversely, a single postsynaptic neuron receives input from multiple presynaptic neurons. Traditional graphs, which represent relationships as pairwise connections between nodes, are insufficient to model this many-to-many connectivity. Hypergraphs generalize the graph structure by allowing connections, termed hyperedges, to link any number of nodes. In an SNN, a hyperedge can represent a synaptic connection between a set of presynaptic neurons and a set of postsynaptic neurons, accurately capturing the complex connectivity patterns present in these networks. This representation is crucial for accurately modeling and simulating SNN behavior, and for enabling efficient parallelization of SNN computations.
The computational demands of large-scale spiking neural networks (SNNs) necessitate distribution across multiple processor cores. Effective partitioning of the hypergraph representation of the SNN – dividing the network’s connections and neurons into subsets assigned to individual cores – is therefore critical for parallelization. Hierarchical Partitioning is a foundational technique for achieving this, operating by recursively dividing the hypergraph into smaller subgraphs based on edge cuts. This approach aims to minimize inter-core communication by reducing the number of connections that span different cores, ultimately improving computational efficiency and scalability. The quality of the partitioning directly impacts the overall performance of the distributed SNN simulation.
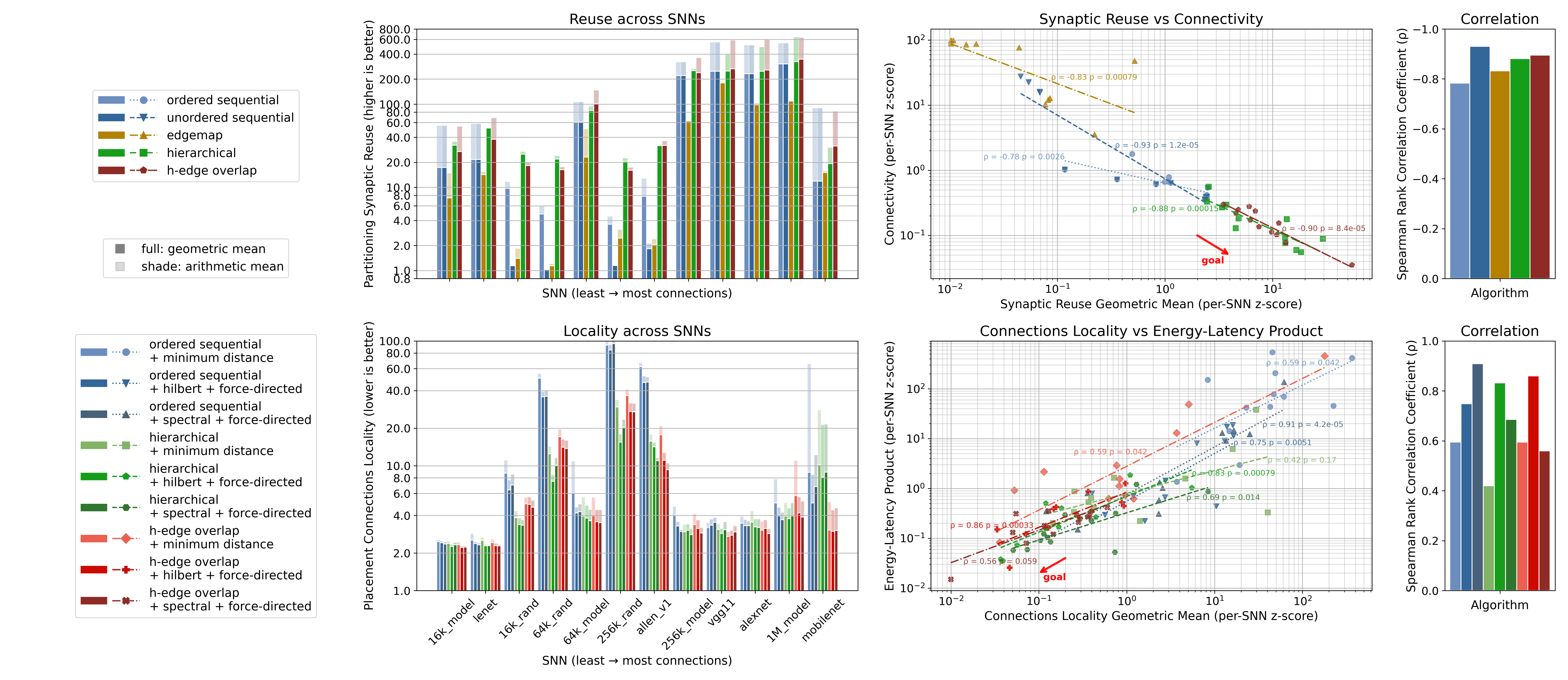
Overlap-Based Partitioning enhances communication efficiency in Spiking Neural Network (SNN) simulations by strategically grouping highly connected nodes during graph partitioning. This approach prioritizes maintaining connections between nodes assigned to different computational cores, a process termed Synaptic Reuse. By minimizing the need to transfer synaptic data between cores, communication costs are significantly reduced, achieving performance gains of 0.47x to 0.98x compared to traditional sequential and hierarchical partitioning methods. This reduction in communication overhead directly translates to faster simulation speeds and improved scalability for large-scale SNN models.

Optimizing Placement: A Balancing Act of Math and Physics
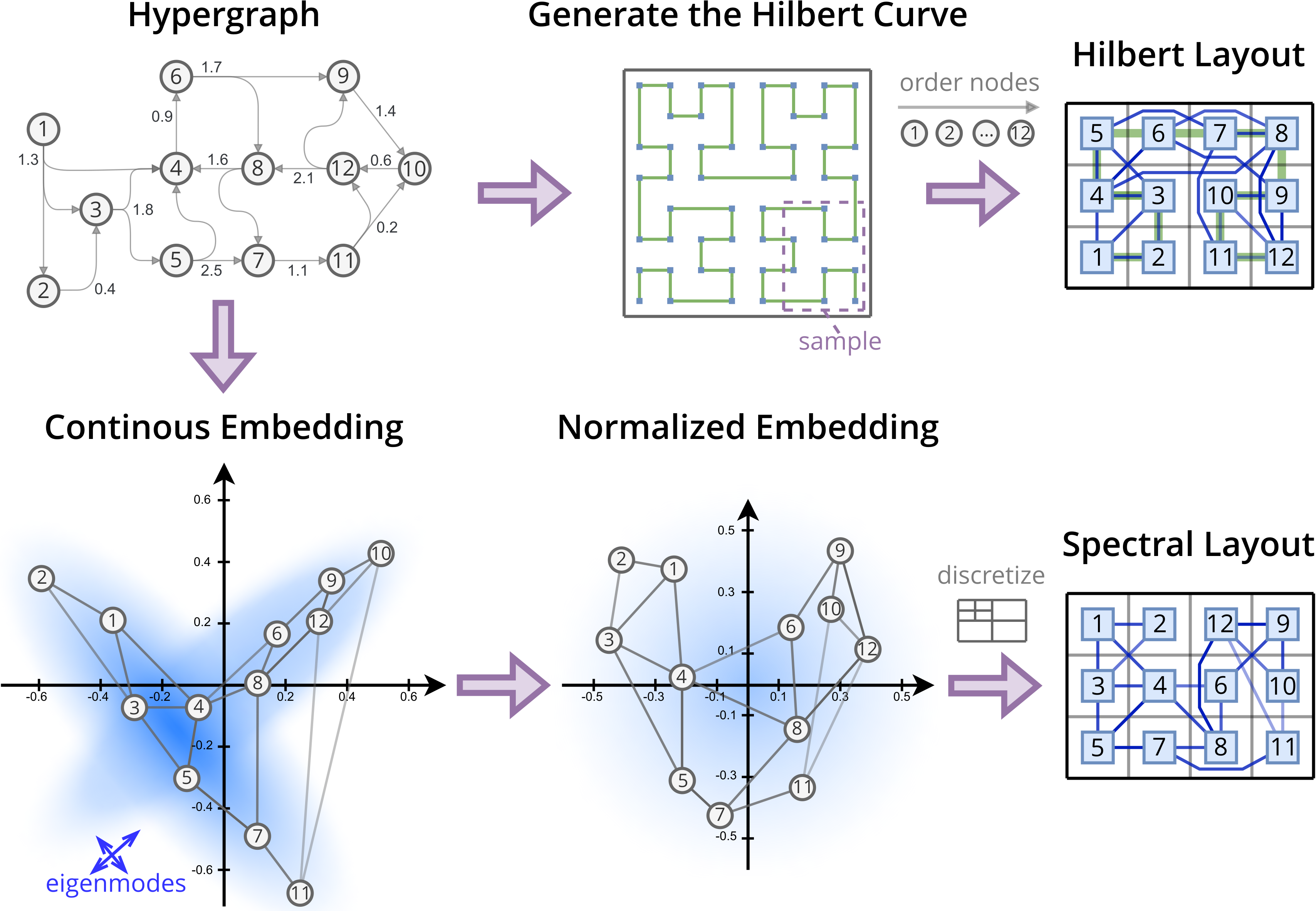
Spectral Placement is a node embedding technique that leverages the mathematical properties of the graph Laplacian. The graph Laplacian, a matrix representing the connectivity of a network, yields eigenvectors which, when used as coordinates in a 2D space, provide a low-dimensional embedding of the nodes. Specifically, the first two eigenvectors are commonly used to represent each node’s position. This embedding process aims to preserve the graph’s structure; nodes closely connected in the original graph will tend to be positioned near each other in the 2D embedding space. The resulting coordinates then serve as a starting point for core assignment algorithms, facilitating the grouping of related nodes and optimizing overall system performance. The \text{Laplacian matrix } L = D - A, where D is the degree matrix and A is the adjacency matrix, is central to this process.
Force-Directed Refinement algorithms operate post-spectral embedding to improve node placement by modeling the graph as a physical system. Nodes are treated as charged particles, with edges representing attractive or repulsive forces – typically, repulsive forces between connected nodes and attractive forces otherwise. The algorithm iteratively adjusts node positions using a relaxation process, calculating net forces and moving nodes proportionally to minimize a defined energy function. This minimization directly correlates with reducing network latency, as nodes with strong connections are pulled closer together, and overall wirelength is decreased. Various implementations utilize different force models and cooling schedules to control the refinement process and prevent oscillations, ultimately aiming for a stable, low-energy configuration that optimizes communication efficiency.
Maintaining connection locality is paramount in distributed system placement to reduce communication latency and network congestion. Techniques extending Spectral Placement, such as utilizing the Hilbert Space-Filling Curve, address this by mapping nodes based on their connectivity and relative positions within the graph structure. The Hilbert curve provides a space-filling property, ensuring that connected nodes are mapped to nearby locations in the 2D embedding space. This minimizes the physical distance between communicating nodes, thereby decreasing communication costs and improving overall system performance. By preserving the inherent locality of the graph during the mapping process, these techniques offer a practical method for optimizing placement in large-scale distributed environments.
Minimum Distance Placement is a core assignment technique that directly optimizes for connection length by iteratively assigning each node to the location that minimizes the sum of distances to its directly connected neighbors. This approach avoids the computational complexity of eigenvector decomposition used in Spectral Placement, offering a significantly faster alternative, particularly for large graphs. While potentially not achieving the same level of global optimization, Minimum Distance Placement provides a pragmatic balance between assignment quality and computational efficiency, making it suitable for dynamic graph scenarios or resource-constrained environments. The algorithm typically initializes node positions randomly and then iteratively refines them until convergence, or a predefined iteration limit is reached.
From Simulation to Reality: The Long Road to Practical SNNs
The burgeoning field of spiking neural networks (SNNs) has historically faced a barrier to entry for researchers accustomed to traditional artificial neural networks. To address this, the SNN ToolBox provides a streamlined pathway for converting pre-trained, conventional neural networks into their spiking equivalents. This automated translation process not only democratizes access to SNN technology but also allows for the rapid prototyping and deployment of existing models on neuromorphic hardware. By leveraging established architectures and weights, researchers can bypass the often-complex task of training SNNs from scratch, accelerating innovation in areas like low-power edge computing and real-time pattern recognition. The ToolBox effectively bridges the gap between the well-established world of artificial intelligence and the promising, yet relatively nascent, field of neuromorphic computation, expanding the potential applications of SNNs to a wider range of problems.
Recent advancements in spiking neural networks (SNNs) are increasingly drawing inspiration from the brain’s own computational strategies, notably through biologically-inspired models like those replicating the functionality of the biological visual cortex, V1. These models aren’t simply mimicking structure; they’re leveraging the inherent efficiency of neural coding with spikes to achieve remarkable performance with significantly reduced power consumption. By emulating the sparse, event-driven communication of biological neurons, these SNNs minimize unnecessary computations and energy expenditure. The resulting architectures demonstrate that high-performance computation isn’t necessarily tied to massive energy demands; instead, intelligent design mirroring natural systems can unlock a pathway toward truly efficient and scalable neuromorphic computing, offering a compelling alternative to traditional artificial neural networks.
Efficiently mapping spiking neural networks (SNNs) onto neuromorphic hardware demands careful consideration of both energy consumption and computational speed. Recent advancements demonstrate that optimized partitioning and placement strategies can dramatically reduce the Energy-Latency Product (ELP), a critical figure of merit for SNN efficiency. Through innovative techniques, researchers have achieved ELP reductions ranging from 0.51x to 0.87x when compared to existing state-of-the-art mapping methods. This improvement stems from a more intelligent distribution of neuronal computations and synaptic connections across the hardware, minimizing energy expenditure without sacrificing processing speed – a crucial step toward realizing practical, low-power neuromorphic computing systems.
Significant advancements in spiking neural network (SNN) efficiency stem from strategies that prioritize synaptic reuse and reduced communication overhead. Recent studies demonstrate a strong negative correlation – a Spearman’s Rank Correlation of -0.86 – between maximizing how often a single synapse participates in multiple computations and overall system energy consumption. This approach, coupled with techniques to minimize data transfer between processing units, unlocks the potential for truly scalable neuromorphic hardware. Results indicate these optimized partitioning and placement methods achieve up to a two-fold improvement in performance compared to conventional SNN mappings, suggesting a pathway towards energy-efficient artificial intelligence systems capable of handling complex tasks with minimal power requirements.
The pursuit of elegant mapping strategies for Spiking Neural Networks onto neuromorphic hardware feels, predictably, like building castles on shifting sand. This paper’s exploration of hypergraphs, while theoretically sound in its focus on synaptic reuse and connections locality, will inevitably encounter the harsh realities of production. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The hypergraph approach, much like any optimization, will eventually be strained by unforeseen network complexities and hardware limitations, demanding pragmatic adjustments and workarounds. It’s a beautiful abstraction, perhaps, but one destined to encounter the inevitable messiness of real-world deployment.
So, What Breaks Next?
This exercise in representing Spiking Neural Networks as hypergraphs, while neat, merely shifts the complexity. One anticipates a new set of partitioning problems will emerge as network scale increases. Optimization for synaptic reuse and connections locality is, after all, simply trading one bottleneck for another. The paper addresses mapping onto neuromorphic hardware, but fails to account for the inevitable variance within that hardware. Each chip will have its own quirks, its own preferred pathways, and the carefully optimized hypergraph will, predictably, require recalibration. It always does.
The focus on connections locality is admirable, but ignores the fact that truly interesting computation often arises from remote interactions. This feels like a local maximum, a clever solution to an immediate problem that sidesteps the deeper question of how to build genuinely intelligent systems. One suspects that the next iteration will involve dynamic hypergraphs, self-reconfiguring networks that adapt to hardware failures and changing computational demands. And, naturally, a completely new set of debugging headaches.
Ultimately, this work offers a sophisticated tool for a very specific task. The real challenge remains: building systems that don’t require such meticulous hand-tuning. It’s a fleeting victory, this hypergraph optimization. Everything new is just the old thing with worse documentation, and a fancier name.
Original article: https://arxiv.org/pdf/2601.16118.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 10 Worst End-Game Couples In Sitcom History
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- DoorDash responds after customer uses AI to make food look bad and get a refund
2026-01-26 01:28