Author: Denis Avetisyan
A new approach drastically cuts communication costs in federated graph learning, enabling more practical and privacy-preserving analysis of complex network data.
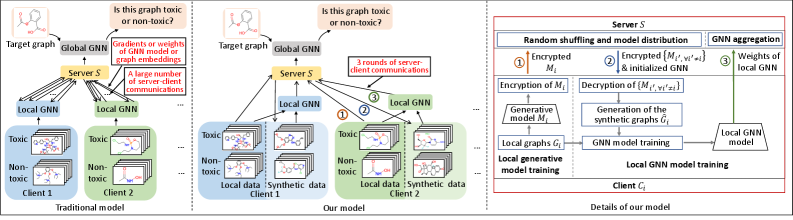
This research introduces CeFGC and CeFGC*, a federated learning framework utilizing generative diffusion models to enhance communication efficiency and performance on non-IID graph data.
Training graph neural networks in decentralized settings is hampered by substantial communication costs and the challenges posed by statistically diverse, non-IID data. This paper, ‘Communication-efficient Federated Graph Classification via Generative Diffusion Modeling’, introduces CeFGC, a novel federated learning framework that minimizes client-server communication to just three rounds by leveraging generative diffusion models. By enabling clients to generate synthetic graphs and share trained diffusion models-rather than raw data-CeFGC effectively aligns local and global objectives while enriching training data. Could this approach unlock more scalable and privacy-preserving graph learning across heterogeneous, real-world datasets?
Decentralized Graphs: A Recipe for Disaster
Graph Neural Networks (GNNs) have demonstrated remarkable performance in analyzing interconnected data, but this typically requires consolidating all information onto a single server. This centralization creates significant hurdles when dealing with real-world graphs that are inherently distributed – think social networks spanning multiple organizations or sensor data collected from numerous devices. The primary difficulties stem from privacy concerns – sharing raw graph data can expose sensitive user information – and communication costs; transmitting large graph structures across networks is bandwidth-intensive and slow. Consequently, applying standard GNN techniques to decentralized settings often proves impractical, necessitating the development of novel approaches that prioritize data privacy and minimize communication overhead while still retaining the ability to learn meaningful patterns from the distributed graph.
The pervasive nature of interconnected data means graph structures frequently reside across numerous independent entities – consider social networks spanning multiple platforms, financial transactions distributed among banks, or healthcare records held by various hospitals. This decentralized reality presents substantial hurdles for collaborative learning; directly pooling this data violates privacy regulations and incurs prohibitive communication costs. Each client possesses only a local fragment of the overall graph, hindering the development of a global model capable of capturing complex relationships. Consequently, algorithms must be designed to operate directly on these distributed fragments, enabling knowledge aggregation without requiring explicit data sharing, and addressing the unique challenges posed by incomplete and heterogeneous graph information held by each participant.
Standard federated learning, while effective for independent and identically distributed data, encounters significant hurdles when applied to graph-structured data. The interconnected nature of graphs introduces dependencies between neighboring nodes, violating the core assumption of data independence that underpins many federated algorithms. This dependency creates a “non-IID” (non-independent and identically distributed) scenario, leading to substantial performance degradation and model instability. Furthermore, the varying degrees and local structures of graphs across different clients-each possessing only a fragment of the complete network-complicate model aggregation. Simply averaging model updates, a common practice in federated learning, fails to account for these structural differences and can result in a suboptimal global model. Consequently, innovative solutions, such as graph-aware aggregation schemes, personalized federated learning, and techniques to mitigate the effects of non-IID data, are essential to unlock the benefits of collaborative learning on decentralized graph data.
The capacity to effectively address the hurdles of decentralized graph learning holds the key to harnessing insights from increasingly distributed datasets. Many real-world networks – social connections, financial transactions, and biological interactions – reside not on a single server, but across numerous independent entities. Successfully enabling collaborative analysis of these fragmented graphs promises breakthroughs in areas ranging from fraud detection and personalized medicine to smart cities and supply chain optimization. Overcoming the privacy and communication bottlenecks inherent in decentralized settings will unlock a wealth of previously inaccessible information, fostering innovation and driving progress across diverse scientific and technological domains. The development of robust, scalable, and privacy-preserving techniques is therefore not merely an academic pursuit, but a critical step towards realizing the full potential of graph data in a connected world.
CeFGC: A Generative Diffusion Approach – Reducing the Noise
CeFGC presents a federated learning framework leveraging Generative Diffusion Models to address challenges posed by non-Independent and Identically Distributed (non-IID) data and high communication costs in decentralized environments. The core innovation lies in training clients to learn a shared data distribution, enabling the exchange of model updates – representing the learned distribution – rather than transmitting raw graph data. This approach significantly reduces communication overhead, as model updates are substantially smaller than complete datasets, and allows for effective model generalization even when client data is heterogeneous. By focusing on distribution learning, CeFGC aims to improve both the efficiency and performance of federated learning on complex graph-structured data.
CeFGC minimizes communication costs in federated learning by enabling clients to exchange model updates instead of transmitting raw graph data. This is achieved through the learning of a shared data distribution, allowing for a substantial reduction in data transfer volume. Experimental results demonstrate communication overhead reductions ranging from 33 to 102 times compared to conventional federated learning methods, which typically require the transmission of complete graph datasets during each communication round. This approach is particularly beneficial in scenarios with high bandwidth limitations or large-scale graph structures, as it significantly decreases the burden on network resources.
CeFGC’s iterative refinement process enables collaborative model improvement through repeated cycles of local update and global aggregation. Each client trains a local model on its private data and then shares only model updates – gradients or parameter changes – with a central server. The server aggregates these updates to refine the global model, which is then redistributed to clients for the next round of training. This approach avoids the direct exchange of raw data, preserving data privacy, while still allowing the model to benefit from the collective knowledge of all clients. The iterative nature of this process facilitates progressive improvement of the global model’s performance over successive communication rounds.
CeFGC demonstrably improves upon the communication efficiency of traditional federated learning approaches in decentralized graph settings. Standard federated learning methodologies often require over 102 communication rounds to achieve convergence, incurring substantial overhead, particularly with large-scale graph data. CeFGC, however, achieves comparable or superior performance with only 3 communication rounds. This reduction is enabled by the framework’s focus on exchanging model updates rather than complete graph datasets, significantly minimizing data transfer requirements and accelerating the training process. Empirical results indicate a substantial decrease in total communication time, making CeFGC a viable solution for resource-constrained decentralized environments.
Experimental Validation: Because Theory Only Gets You So Far
CeFGC’s performance was rigorously assessed using three experimental paradigms designed to evaluate its adaptability. The single dataset setting tested the framework’s efficacy when trained and evaluated on a single graph dataset. The across-dataset setting examined performance when the model was trained on one graph dataset and tested on another, evaluating generalization capabilities. Finally, the across-domain setting pushed the framework further by training on graphs from one domain (e.g., social networks) and testing on graphs from a different domain (e.g., biological networks), providing a comprehensive measure of its versatility and ability to transfer learned knowledge between disparate graph structures.
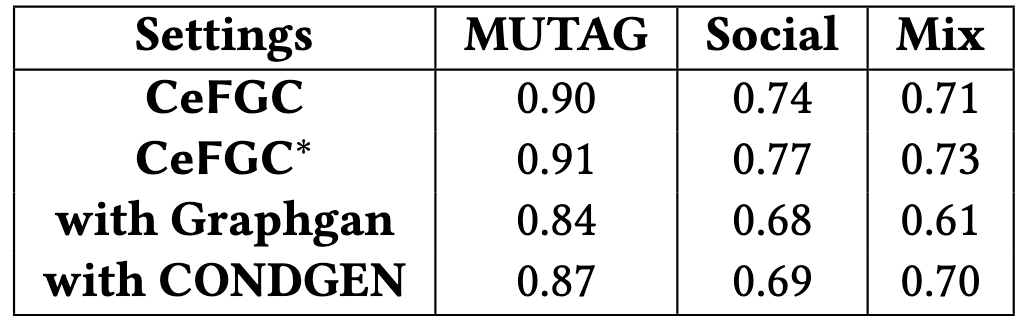
CeFGC consistently outperforms baseline decentralized graph learning methods when evaluated using the Area Under the Curve (AUC) metric. Performance gains are observed even with a limited number of communication rounds between participating nodes. Specifically, experimental results on the IMDB-M dataset demonstrate an improvement of up to 23.1% compared to existing approaches. This indicates CeFGC’s efficiency in converging to a high-performing model with reduced communication overhead, a critical advantage in decentralized learning scenarios.
To enhance model robustness and generalization, the CeFGC framework utilizes synthetic graph data augmentation. This technique involves generating artificial graph structures and feature sets, effectively increasing the size and diversity of the training dataset. By training on both real and synthetically generated graphs, the model becomes less susceptible to overfitting on the characteristics of a single dataset and improves its ability to perform accurately on unseen graph structures. This data augmentation strategy contributes to more stable and reliable performance across varying graph datasets and domains, particularly when limited real-world data is available.
Experimental results demonstrate CeFGC’s efficacy as a solution for decentralized graph learning. Specifically, the framework achieved an accuracy of 0.91 on the MUTAG dataset, indicating a high level of performance in a standard benchmark for graph classification. This score was obtained through testing across various experimental settings, validating the framework’s robustness and generalization capabilities in decentralized learning scenarios. The reported accuracy suggests CeFGC is a viable approach for applications requiring distributed graph analysis without centralized data access.
CeFGC*: Adding Labels – A Little More Information Never Hurts
CeFGC* builds upon the existing CeFGC framework by introducing a Graph Label Channel within the generative diffusion model. This channel facilitates the incorporation of node and edge label information directly into the data generation process. Specifically, label embeddings are concatenated with the graph’s feature vectors, providing the diffusion model with additional contextual data during both forward and reverse diffusion steps. This allows the model to generate graphs that are not only structurally plausible but also adhere to the specified label distributions, resulting in more informed and controllable graph generation compared to label-agnostic approaches.
CeFGC* demonstrates performance improvements by directly incorporating label information into the generative diffusion process. This label integration is particularly beneficial when dealing with complex graph structures, where distinguishing nodes and edges requires a higher degree of contextual understanding. Empirical results indicate that the model achieves enhanced generation quality and accuracy in these scenarios, surpassing the performance of CeFGC and other comparable generative models lacking explicit label awareness. The increased performance is attributed to the model’s ability to leverage label data to resolve ambiguities and generate more realistic and coherent graph representations.
The integration of label information into generative models, as demonstrated by CeFGC, represents a significant advancement in data generation capabilities. Traditional generative models often operate without explicit knowledge of data categories or attributes. By incorporating label-aware learning techniques, models can leverage these contextual cues to produce more accurate and relevant outputs. This approach allows the model to condition its generation process on specific labels, resulting in improved sample quality and increased control over the generated data distribution. The performance gains observed with CeFGC highlight the benefits of explicitly guiding the generative process with label information, particularly for complex datasets where categorical understanding is crucial.
CeFGC* integrates Homomorphic Encryption (HE) to protect data privacy during federated model updates. This allows model training to occur on decentralized datasets without requiring data owners to directly share their raw data. HE enables computations to be performed on encrypted data, meaning the central server receives only encrypted updates from participating clients. These encrypted updates are aggregated and used to update the global model, while the individual client data remains confidential throughout the entire process. The implementation utilizes a FHE scheme, ensuring strong privacy guarantees and maintaining model accuracy comparable to training on unencrypted data.
The pursuit of communication efficiency, as demonstrated by CeFGC and CeFGC, feels less like innovation and more like delaying the inevitable. This paper attempts to address the realities of federated learning – namely, the crushing weight of data transmission and the inherent messiness of non-IID data. It’s a clever application of generative diffusion models, certainly, but one can’t help but recall Claude Shannon’s observation that “communication is the transmission of information, but to really communicate is to establish commonality.” The framework builds layers of complexity to manage* the problem of data heterogeneity and bandwidth limitations, rather than solve it. The ‘commonality’ Shannon speaks of remains elusive, masked by increasingly elaborate architectures. It’s an expensive way to complicate everything, and someone, somewhere, will inevitably need to debug it at 3 AM.
What’s Next?
The presented framework, while demonstrating a reduction in communication overhead – a perennial bottleneck in federated learning – merely shifts the complexity. The generative diffusion models, lauded for their performance, introduce their own set of hyperparameter sensitivities and training instabilities. Expect production to find them. It’s a familiar dance: trade one problem for another, repackage it as progress. The non-IID data handling, while improved, still relies on assumptions about the underlying graph distributions. Reality, of course, rarely adheres to convenient assumptions.
Future work will undoubtedly focus on squeezing even more efficiency out of these models – perhaps through increasingly aggressive quantization or distillation techniques. The inevitable outcome? A brittle system, exquisitely tuned to a specific dataset, and prone to catastrophic failure when faced with anything remotely unexpected. It’s the cycle of life, really. Everything new is old again, just renamed and still broken.
The truly interesting question isn’t whether these models can function in a federated setting, but whether the marginal gains justify the operational cost. The answer, predictably, will depend on the tolerance for late-night alerts. And production, as always, will be the final arbiter. If it works – wait.
Original article: https://arxiv.org/pdf/2601.15722.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 10 Worst End-Game Couples In Sitcom History
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
2026-01-25 15:20