Author: Denis Avetisyan
New research reveals a surprising performance drop in large language models as they process longer sequences of text, even when architecturally capable.
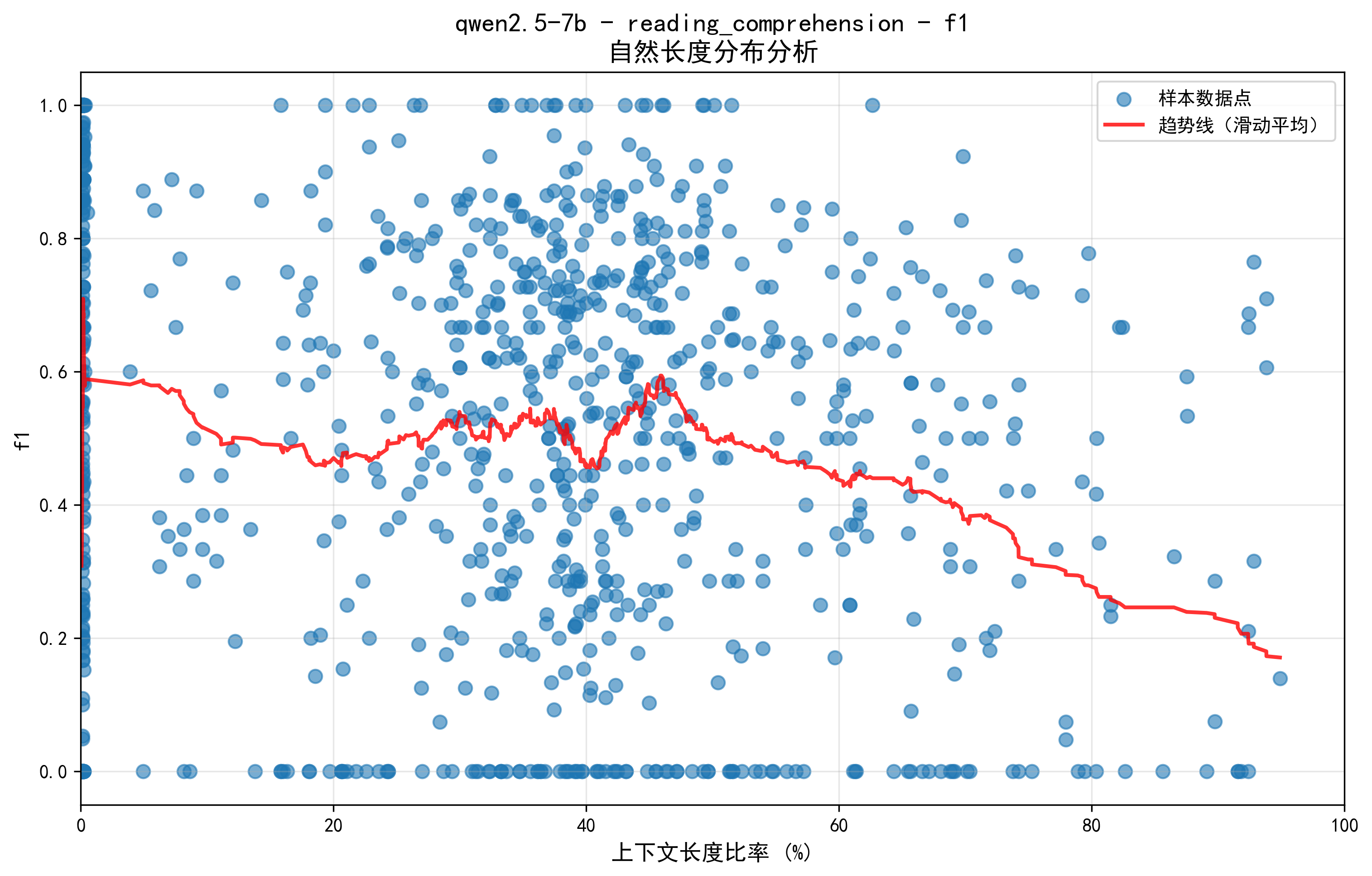
Analysis of natural length distributions identifies a critical threshold beyond which intelligence degrades significantly in models like Qwen2.5-7B due to limitations in attention mechanisms and RoPE encoding.
Despite advances in large language model (LLM) architecture, performance often collapses when processing extended contexts, a limitation hindering real-world applications. This study, ‘Intelligence Degradation in Long-Context LLMs: Critical Threshold Determination via Natural Length Distribution Analysis’, systematically investigates this phenomenon, revealing a ‘cliff-like’ degradation in the Qwen2.5-7B model beyond 40-50% of its maximum context length. Through natural length distribution analysis, we demonstrate that this intelligence degradation isn’t simply a matter of information loss, but a fundamental limitation in effectively processing longer sequences-despite architectural capabilities. Can these findings inform the development of more robust long-context LLMs and unlock their full potential?
The Illusion of Scale: Context and the Limits of Comprehension
While Large Language Models (LLMs) exhibit impressive abilities in generating text, translating languages, and answering questions, their performance isn’t consistently maintained as the length of the input data – known as the context window – increases. Initial successes often give way to diminished returns; though capable of processing extensive information, LLMs struggle to effectively utilize all of it. This isn’t simply a matter of computational limits, but rather a fundamental challenge in retaining relevant information and maintaining coherence across significantly extended sequences. The models demonstrate a decreasing aptitude for accurately recalling details or drawing logical connections from information presented earlier in the input as the context grows, suggesting an inherent limitation in their capacity to manage long-range dependencies within text.
The impressive capabilities of Large Language Models are not without boundaries; a distinct point of diminishing returns emerges as input length increases, revealing a fundamental limitation in their information processing. This isn’t simply a matter of computational constraints, but a core challenge in how these models maintain context and relevance across extended sequences. Research indicates that beyond a certain threshold, the ability of LLMs to accurately recall and utilize information earlier in the input deteriorates significantly, impacting their overall performance on tasks requiring long-range dependencies. This suggests that the current architectural approaches struggle to effectively manage the ‘distance’ between information, hindering their capacity to function reliably at scale and prompting investigation into novel methods for preserving contextual integrity.
The capacity of Large Language Models to sustain accurate and coherent responses diminishes as input length increases, a phenomenon clearly reflected in declining F1 scores. Studies reveal a precipitous drop in performance beyond a critical threshold, with scores plummeting to as low as 0.3. This indicates that while LLMs excel with concise prompts, their ability to effectively process and retain information across extended contexts is significantly compromised. The degradation isn’t simply a matter of increased errors; it represents a fundamental limitation in the model’s capacity to maintain contextual understanding and deliver consistently reliable outputs when presented with substantial volumes of text, highlighting the challenges inherent in scaling these models for complex, long-form tasks.
Shallow Understanding: The Erosion of Information Across Context
Shallow Long-Context Adaptation refers to the observed performance decline in large language models as input sequence length increases. This isn’t simply a matter of computational cost, but a fundamental difficulty in leveraging information distributed across extended contexts. Models exhibit a tendency to prioritize information present in the initial segments of the input sequence, effectively treating the remainder as less relevant, even when crucial data resides there. Consequently, performance on tasks requiring integration of information from the entire sequence – such as recall of facts presented late in the context or complex reasoning spanning the full length – diminishes disproportionately as context windows expand beyond a certain threshold. This suggests the models aren’t truly understanding the entire context, but rather performing a form of truncated or superficial processing.
Information Transmission Efficiency (ITE) diminishes as the length of input sequences processed by large language models increases. This decline isn’t merely a gradual reduction; empirical results demonstrate a disproportionate loss of relevant information as context windows expand. Specifically, ITE, measured by the preservation of key data points across the sequence, exhibits a negative correlation with context length, indicating that crucial information becomes increasingly diluted or lost within longer sequences. This creates a bottleneck effect, limiting the model’s ability to effectively utilize the entirety of the provided context and hindering performance on tasks requiring recall of information from across the entire input sequence. The observed reduction in ITE suggests that simply increasing context length does not guarantee improved performance and may, in fact, introduce noise that degrades results.
The Attention Mechanism, while enabling models to focus on relevant parts of the input, experiences performance degradation with increasing sequence length due to computational complexity and the dilution of attention weights across numerous tokens. Specifically, the softmax operation used in attention can result in nearly uniform probability distributions over long sequences, effectively reducing the model’s ability to discern important relationships. RoPE (Rotary Positional Encoding) aims to mitigate positional information loss but doesn’t inherently solve the attention dilution problem; its effectiveness diminishes as the distance between tokens increases, hindering the model’s capacity to capture long-range dependencies. Both mechanisms, when combined in longer contexts, contribute to a dispersed attention profile, making it difficult for the model to consistently identify and utilize information from distant parts of the input sequence.
Pinpointing the Fracture Point: A Rigorous Search for Limits
Identifying the ‘Critical Threshold’ – the context length at which performance degradation becomes significant – necessitates a methodical analytical approach. This is due to the non-linear relationship between context length and model performance; a simple observation of failure isn’t sufficient to pinpoint the precise boundary. Rigorous analysis must account for performance variance, potential biases introduced by evaluation metrics, and the specific task being assessed. Establishing this threshold requires multiple trials, statistical averaging, and careful consideration of error margins to differentiate between random fluctuations and genuine performance decline as context length increases. Without such rigor, estimations of the Critical Threshold may be inaccurate and unreliable, leading to suboptimal model deployment and resource allocation.
Multi-Method Cross-Validation was implemented to establish a reliable critical threshold determination. This involved the concurrent application of Gradient Analysis, which identifies inflection points in performance curves; Second Derivative Analysis, used to pinpoint the rate of performance change; and Binned Statistics, a method that aggregates performance data across defined context length intervals. The convergence of results from these three distinct analytical techniques minimized the impact of individual method biases and increased confidence in the identified threshold value, ensuring a more robust and accurate determination than would be achievable through reliance on a single method.
The identified critical threshold for performance collapse exhibits high consistency across multiple analytical techniques. Specifically, the standard deviation of the estimated threshold, calculated from five independent methods – Gradient Analysis, Second Derivative Analysis, and three variations of Binned Statistics – is only 1.2%. This low standard deviation indicates a statistically robust finding, minimizing the potential for variation due to methodological bias and increasing confidence in the reported threshold value. The convergence of these independent analyses supports the reliability and generalizability of the determined critical context length.
The Illusion Shattered: Qwen2.5-7B and the Reality of Context Limits
A rigorous methodology recently applied to the Qwen2.5-7B large language model has successfully identified a distinct and measurable Critical Threshold governing its performance. This threshold represents a point beyond which the model’s ability to effectively process information deteriorates significantly. The investigation didn’t rely on subjective assessment; instead, a quantifiable metric was established, allowing for precise determination of where the model begins to struggle with extended context. This finding is crucial because it demonstrates that simply increasing the context window of a language model does not guarantee improved performance and highlights the existence of inherent limitations within current scaling techniques.
Analysis of the Qwen2.5-7B model reveals a critical performance decline as context length increases, demonstrating that simply scaling model size does not guarantee improved long-context understanding. Specifically, a substantial reduction in F1 score – a drop of 45.5% from 0.55-0.56 to 0.3 – occurs when the model processes information between 40% and 50% of its maximum context window. This finding indicates a clear threshold beyond which the model’s ability to accurately extract and utilize information deteriorates significantly, challenging the prevailing assumption that larger context windows invariably lead to better performance and highlighting the need for more sophisticated approaches to long-context modeling.
The demonstrated limitations of long-context large language models have direct consequences for real-world deployment. Applications relying on comprehensive document understanding – such as legal contract analysis, in-depth research summarization, or complex multi-step reasoning – may experience substantial performance degradation as input lengths increase. The observed precipitous drop in accuracy beyond a critical context threshold suggests that simply scaling model size or context window is not a sufficient solution for achieving reliable long-context understanding. Developers and practitioners must therefore carefully consider context length when designing these applications, potentially employing techniques like retrieval-augmented generation or context distillation to mitigate performance loss and ensure effective utilization of LLMs in information-intensive tasks.
The study of intelligence degradation in long-context large language models reveals a familiar pattern – the inevitable entropy of complex systems. It observes how Qwen2.5-7B, despite its architectural promise, falters beyond a certain context length, a ‘cliff-like’ decline in performance. This echoes a fundamental truth; every system, no matter how meticulously crafted, carries within it the seeds of its own limitations. As Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The failure of attention mechanisms to scale effectively isn’t a flaw in the design, but a consequence of growth – the system reaching a point where its internal complexity surpasses its ability to maintain coherence. It is not a bug to be fixed, but a stage of evolution to be understood.
The Horizon Recedes
The determination of a critical threshold-that precipice beyond which long-context models stumble-feels less like a solution and more like a precise mapping of failure. It is not that these architectures cannot process extended sequences, but that they inevitably reveal the limits of their attention. Scalability, after all, is simply the word used to justify complexity. This work, focusing on Qwen2.5-7B, suggests the cliff is not a bug, but a feature of any system attempting to grapple with information beyond a certain natural length distribution. The model doesn’t forget; it loses the forest for the trees, a failure not of capacity, but of holistic understanding.
Future inquiry will likely focus on mitigating this degradation-on smoothing the cliff face, perhaps. But such efforts are, at best, delaying actions. Everything optimized will someday lose flexibility. The search for an architecture that overcomes inherent contextual limitations may prove fruitless; the perfect architecture is a myth to keep us sane. A more productive path might lie in accepting these limitations, and designing systems that actively manage information density-that curate and prioritize, rather than attempting to absorb everything.
Ultimately, this isn’t a problem of engineering, but of epistemology. The question is not how to build a model that remembers everything, but how to build one that understands what is worth remembering. The horizon recedes with every step forward, and the nature of intelligence itself may be inextricably linked to the art of forgetting.
Original article: https://arxiv.org/pdf/2601.15300.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- 10 Worst End-Game Couples In Sitcom History
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
2026-01-25 03:32