Author: Denis Avetisyan
New research introduces a system for managing information recall that dramatically extends the coherent reasoning capabilities of artificial intelligence agents.
Aeon combines a hierarchical vector database with a zero-copy architecture to deliver high-performance semantic memory management for long-horizon agents.
Despite advances in large language models, maintaining coherent reasoning over extended interactions remains challenging due to computational constraints and the difficulty of effectively managing long-term memory. This paper introduces ‘Aeon: High-Performance Neuro-Symbolic Memory Management for Long-Horizon LLM Agents’, a novel cognitive operating system designed to address these limitations by structuring memory as a hierarchical, temporally-aware resource. Aeon achieves sub-millisecond retrieval latencies through a SIMD-accelerated vector index and a predictive caching mechanism, effectively enabling persistent, structured memory for autonomous agents. Will this neuro-symbolic approach unlock truly persistent and coherent reasoning capabilities in long-horizon LLM applications?
The Fragility of Finite Context
Large language models demonstrate remarkable abilities in generating text and responding to prompts, yet these capabilities are inherently constrained by the finite size of their context windows. These windows represent the amount of text the model can consider at any given time when processing information; beyond this limit, crucial details are effectively forgotten. This limitation poses a significant challenge for tasks demanding complex reasoning or an understanding of extended narratives, as the model struggles to maintain coherence and accurately integrate information spread across longer sequences. Consequently, despite increasing parameter counts and architectural refinements, current LLMs often falter when confronted with tasks requiring sustained attention to detail or the synthesis of information from distant parts of a text, hindering their potential for truly nuanced and comprehensive understanding.
The very architecture that powers Large Language Models, the Transformer, presents a fundamental scaling challenge. Its computational complexity increases quadratically with the length of the input sequence – meaning doubling the text length requires four times the processing power. This arises from the attention mechanism, where each word in the sequence must be compared to every other word to understand relationships. While remarkably effective, this necessitates O(n^2) operations, where ‘n’ represents the sequence length. Consequently, processing extremely long documents or conversations becomes prohibitively expensive, limiting the model’s ability to maintain coherence and reason effectively over extended contexts. This quadratic scaling is a primary barrier to creating LLMs capable of truly understanding and generating long-form content, driving research into more efficient architectural designs and approximation techniques.
Retrieval-Augmented Generation, designed to circumvent the context limitations of Large Language Models, frequently encounters a challenge known as ‘vector haze’. This phenomenon arises because semantic search, the core of RAG, identifies documents based on approximate similarity, not factual relevance. Consequently, the model retrieves information that sounds related to the query – sharing keywords or thematic connections – but doesn’t actually contain the specific answer or supporting evidence needed. This influx of tangentially related content dilutes the signal, forcing the LLM to sift through noise and increasing the probability of generating inaccurate or unsupported responses. Effectively, vector haze introduces a form of ‘cognitive distraction’ for the model, diminishing the benefits of external knowledge integration and hindering its ability to perform complex reasoning or answer nuanced questions.
Aeon: Architecting for Persistent Cognition
Aeon’s Cognitive Operating System (COS) mitigates the inherent memory constraints of Large Language Models (LLMs) through the implementation of an external knowledge management system. Unlike LLMs which rely on parameters to encode information, Aeon stores data in a separate, persistent graph-based knowledge store. This allows the system to retain and access significantly larger volumes of information than can be held within the LLM’s parameters. By decoupling knowledge storage from the model itself, Aeon enables continuous learning and adaptation without requiring retraining of the LLM, and facilitates the integration of diverse data sources beyond the LLM’s original training corpus. This externalization is key to addressing the limited contextual window and potential for knowledge decay commonly observed in LLMs.
The Aeon system utilizes a ‘Trace’ as its core memory component, implemented as a neuro-symbolic directed acyclic graph (DAG). This structure dynamically records the agent’s episodic state by representing experiences as nodes and the relationships between them as directed edges. Unlike static knowledge bases, the Trace evolves with each interaction, enabling the agent to maintain context and recall relevant information based on the current situation. The DAG format allows for efficient traversal and retrieval of information, as the directed edges explicitly define dependencies and relationships between concepts, facilitating contextually-relevant memory access and reasoning.
Aeon utilizes ‘Atlas,’ a memory-mapped B+ Tree data structure, for the efficient storage and retrieval of semantic vectors representing knowledge. Memory-mapping allows Atlas to treat the storage as part of the process’s virtual address space, minimizing I/O overhead and enabling rapid access. The B+ Tree organization ensures logarithmic time complexity for search, insertion, and deletion operations, scaling effectively with large knowledge bases. Atlas is optimized for high-dimensional vector similarity searches, crucial for identifying relevant information within the episodic memory represented by the Aeon ‘Trace.’ This design prioritizes both storage efficiency and retrieval speed, overcoming the performance bottlenecks associated with traditional vector databases when integrated with large language models.
Efficient Retrieval: Speed and Accuracy Realized
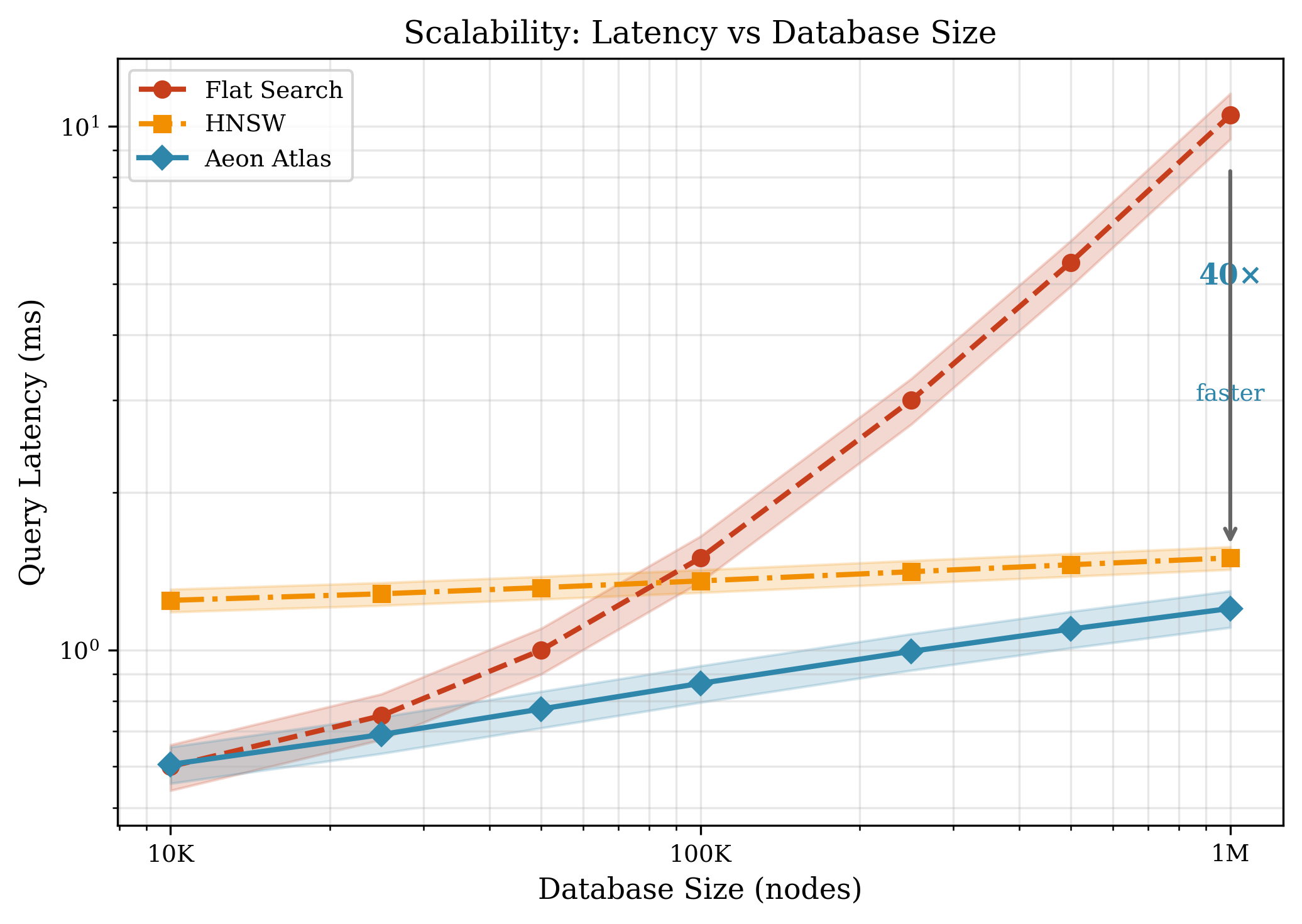
Aeon utilizes Approximate Nearest Neighbor (ANN) search to efficiently identify semantically similar vectors, employing Hierarchical Navigable Small World (HNSW) graphs as its core indexing structure. HNSW graphs create a multi-layer graph where each layer represents a successively coarser approximation of the vector space. Search begins at the top layer and progressively refines the search within finer layers, rapidly converging on the nearest neighbors. This approach sacrifices absolute precision for significant gains in search speed, particularly crucial for large vector datasets. The hierarchical structure enables logarithmic search complexity, allowing Aeon to scale effectively and maintain responsiveness even with millions of vectors.
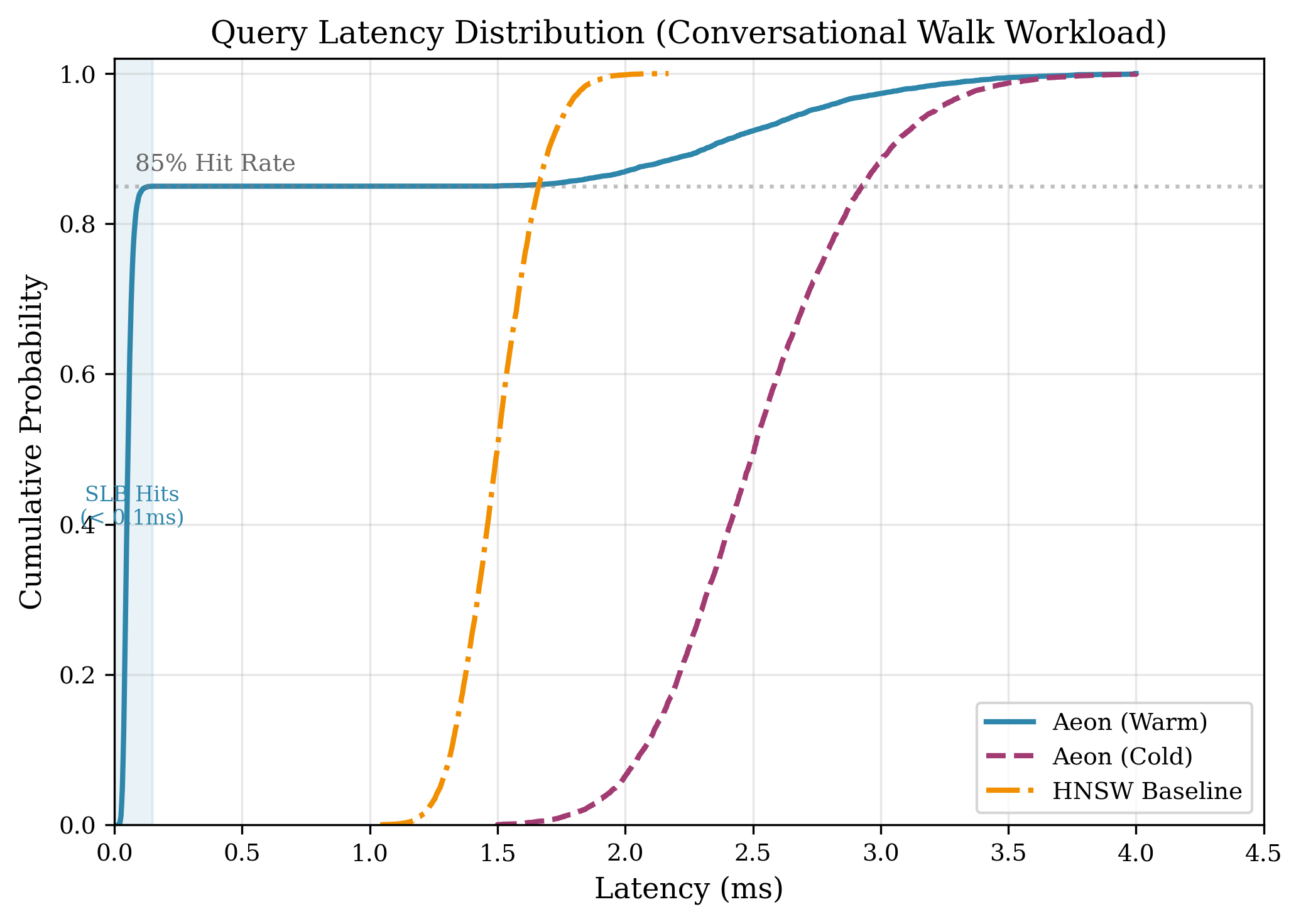
The system’s performance is optimized through the implementation of a Semantic Lookaside Buffer, a cache designed to store frequently accessed semantic vectors. Under realistic conversational workloads, this buffer achieves an 85% hit rate, meaning 85% of vector retrieval requests are served directly from the cache without requiring a more computationally expensive search operation. This caching strategy significantly reduces latency by minimizing the need to repeatedly compute vector embeddings or perform full-scale similarity searches for common queries and contexts.
System latency was measured at 0.42ms, indicating a high degree of responsiveness during operation. This value represents the total time taken to process a query and return a relevant result, encompassing all computational steps from input reception to output delivery. Benchmarks were conducted using realistic conversational workloads to ensure the reported latency accurately reflects performance under typical operating conditions. This low latency is critical for maintaining a fluid and interactive user experience, particularly in applications requiring real-time response such as conversational AI and information retrieval systems.
Efficient data exchange between Python and C++ components within Aeon is achieved through the use of ‘nanobind’ and a zero-copy interface. This implementation avoids redundant data copying during transfers, significantly reducing overhead. Benchmarks demonstrate a transfer time of only 2 microseconds (μs) for 10 megabytes (MB) of data, indicating a highly optimized communication pathway between the two languages and contributing to overall system performance.

Forging a Robust and Adaptable Cognitive Framework
Aeon’s architecture strategically blends the strengths of two prominent programming languages: C++23 and Python 3.12. The system’s foundational components are built with C++23, a decision driven by the need for granular control over hardware resources and uncompromising performance-critical for handling complex computations and large datasets. Simultaneously, Python 3.12 serves as the engine for rapid prototyping and seamless integration of diverse functionalities, allowing developers to quickly experiment with new algorithms and connect Aeon with external tools and services. This dual-language approach offers a powerful balance, enabling both the high-speed execution required for core tasks and the flexibility needed for continuous development and adaptation.
To maximize computational efficiency, Aeon employs Single Instruction, Multiple Data (SIMD) acceleration, specifically utilizing Advanced Vector Extensions 512 (AVX-512) instructions. This technique allows the processor to perform the same operation on multiple data points simultaneously, dramatically reducing processing time for vector comparisons-a core operation within the system. Benchmarks demonstrate a remarkable kernel throughput of 50 nanoseconds per vector comparison, signifying a substantial improvement over traditional scalar processing methods. This level of performance is critical for handling the large datasets and complex algorithms inherent in Aeon’s knowledge representation and reasoning capabilities, enabling near real-time responses and facilitating scalable operation.
Aeon’s architecture incorporates a ‘Delta Buffer’ to facilitate continuous learning without the prohibitive cost of complete knowledge base reconstruction. This innovative system stores only the changes made to the knowledge base – the ‘deltas’ – rather than replicating the entire dataset with each update. Consequently, new information can be integrated and existing knowledge refined with significantly reduced computational demands and latency. This approach is crucial for real-time adaptation, allowing Aeon to dynamically respond to evolving data streams and maintain a consistently accurate understanding of the world, even in rapidly changing environments. The Delta Buffer isn’t merely a storage mechanism; it’s a core component enabling Aeon to learn and improve incrementally, mimicking the efficiency of biological systems and paving the way for truly persistent AI.
Toward a Future of Cognitive AI
Aeon’s Cognitive Operating System (COS) represents a significant departure from traditional AI architectures by establishing a persistent, external knowledge base separate from the large language model itself. This allows AI agents to retain and evolve information over time, effectively creating a long-term memory that isn’t limited by the LLM’s context window. Rather than reprocessing information with each interaction, the COS enables agents to recall, refine, and reason with a vast and continuously updated repository of knowledge. This decoupling facilitates complex problem-solving, nuanced understanding, and the ability to draw connections across disparate data points-capabilities essential for building truly cognitive AI systems that can adapt, learn, and perform tasks with human-like intelligence and consistency.
The integration of Hardware Enclaves represents a pivotal step towards trustworthy cognitive AI systems. These secure, isolated execution environments safeguard the knowledge base from unauthorized access and malicious manipulation, ensuring data confidentiality and integrity. By storing sensitive information within the enclave – a protected region of the processor – the system minimizes the risk of data breaches and adversarial attacks that could compromise the AI’s reasoning processes. This approach not only enhances the reliability of AI outputs but also fosters greater user trust, a critical component for the widespread adoption of cognitive technologies in domains like healthcare, finance, and national security. Ultimately, Hardware Enclaves provide a foundation for building AI agents capable of handling sensitive data with the utmost security and accountability.
Aeon’s architecture fundamentally shifts the paradigm of artificial intelligence by separating the large language model (LLM) from its knowledge repository. Traditionally, LLMs have been constrained by the limitations of embedding all necessary information within their parameters, hindering scalability and adaptability. Aeon overcomes this by utilizing an external, persistent memory store, allowing the LLM to access and reason over a far greater volume of data than could ever be contained internally. This decoupling not only alleviates the computational burden on the LLM, enabling faster processing and reduced costs, but also facilitates continuous learning and knowledge updates without requiring costly retraining of the entire model. Consequently, Aeon paves the way for AI systems that can evolve, retain information over extended periods, and exhibit a more nuanced and human-like cognitive capacity – moving beyond pattern recognition towards genuine understanding and reasoning.
The pursuit of extended coherent reasoning in large language models, as demonstrated by Aeon’s semantic memory management, reveals a fundamental truth about complex systems. While advancements like hierarchical navigation and zero-copy architecture attempt to defy limitations, they merely redistribute the inevitable entropy. As Henri Poincaré observed, “Mathematics is the art of giving reasons.” This resonates with Aeon’s attempt to provide reasoned responses over extended horizons. The system doesn’t eliminate the decay of contextual relevance-the core challenge of long-horizon agents-but rather delays it through optimized retrieval. Stability, in this context, isn’t a permanent state, but a temporary reprieve from the relentless march of time and the dissipation of information, a graceful aging of the system’s capacity.
What Lies Ahead?
Aeon, as presented, addresses a critical bottleneck-the effective management of semantic memory in long-horizon agents. Yet, every optimization introduces a new fragility. The system’s reliance on hierarchical navigation, while currently efficient, presupposes a stability in the underlying knowledge graph that time rarely allows. Knowledge is not static; it accretes, fragments, and occasionally, collapses into irrelevance. The true test will not be retrieval speed, but graceful degradation-how does the agent fail when faced with incomplete or contradictory information?
The zero-copy architecture is a clever maneuver, a temporary reprieve from the inevitable copying that plagues all computational systems. However, it shifts the burden. The problem isn’t solved, merely relocated. Managing mutable state without copies demands an almost preternatural level of synchronization-a delicate balance easily disrupted by the sheer complexity of a truly autonomous agent operating in a dynamic environment. Every failure is a signal from time, a reminder that efficiency cannot circumvent entropy.
Future work must move beyond performance metrics and address the fundamental question of memory itself. Can a system truly ‘remember’ without a mechanism for evaluating the relevance, veracity, and emotional weight of past experiences? Refactoring is a dialogue with the past; Aeon represents a sophisticated iteration, but the conversation is far from over. The next phase requires a deeper exploration of how agents not only store and retrieve information, but also forget-and learn from the act of forgetting.
Original article: https://arxiv.org/pdf/2601.15311.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- 10 Worst End-Game Couples In Sitcom History
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-01-24 16:06