Author: Denis Avetisyan
New research demonstrates how artificial intelligence can enhance the detection of structural defects in critical underground infrastructure like culverts and sewers.

This review explores deep learning techniques – including data augmentation, few-shot learning, and the novel FORTRESS architecture – for accurate defect segmentation with limited labeled data.
Effective structural inspection of critical drainage infrastructure is often hampered by the scarcity of labeled data required for robust defect segmentation. This research, detailed in ‘AI-Based Culvert-Sewer Inspection’, addresses this challenge through a suite of innovative deep learning techniques. Specifically, the authors demonstrate improved performance via data augmentation, a novel architecture-FORTRESS incorporating depthwise separable convolutions and adaptive Kolmogorov-Arnold Networks-and few-shot learning approaches. By significantly reducing the need for extensive annotation, can these methods pave the way for more efficient and scalable infrastructure monitoring systems?
The Data Scarcity Problem: Why Infrastructure Monitoring Needs a Fix
The promise of proactive infrastructure maintenance through structural health monitoring is frequently constrained by a fundamental challenge: the scarcity of labeled data needed to train effective defect detection systems. Unlike image recognition tasks with readily available datasets, identifying anomalies in structures – such as cracks, corrosion, or material degradation – demands specialized inspections and expert annotation. These inspections are often costly, time-consuming, and potentially dangerous, limiting the volume of labeled examples available for machine learning algorithms. Consequently, developing robust and reliable systems for automatically pinpointing structural issues is hampered not by a lack of analytical techniques, but by the practical difficulties of acquiring sufficient, high-quality training data that accurately represents the range of potential defects and operating conditions.
The promise of deep learning for infrastructure monitoring is often hampered by a fundamental requirement: vast quantities of labeled data. These neural networks, while powerful, necessitate extensive datasets to accurately learn patterns and reliably identify structural defects. However, in practical scenarios – such as bridge inspections or pipeline monitoring – acquiring this data proves exceptionally challenging and costly. Labeling requires expert knowledge, often involving manual examination of images, sensor readings, or physical inspections, which are time-consuming and resource-intensive. Consequently, the prohibitive cost and logistical difficulties of obtaining sufficiently large, accurately labeled datasets frequently render traditional deep learning approaches impractical for widespread implementation in real-world infrastructure health management.
The practical challenge of identifying structural defects is often compounded by a significant data imbalance. In infrastructure monitoring, certain defect types – such as critical cracks or corrosion at specific joints – are inherently rare compared to the prevalence of normal, undamaged states. This disproportionate representation, known as ‘ClassImbalance’, can severely bias the performance of machine learning models. Algorithms trained on such skewed datasets tend to prioritize the detection of common, normal conditions, effectively overlooking or misclassifying the less frequent, yet potentially catastrophic, defects. Consequently, models may exhibit high accuracy overall, but demonstrate poor sensitivity to the very failures they are designed to prevent, necessitating specialized techniques to address this critical issue and ensure reliable structural health assessments.

Bridging the Data Gap: Few-Shot Learning and Targeted Augmentation
Few-shot learning addresses the challenge of training effective machine learning models when labeled data is scarce. Traditional supervised learning methods require large datasets for generalization; however, few-shot learning techniques enable models to achieve acceptable performance with only a handful of annotated examples per class. This is accomplished by leveraging prior knowledge or meta-learning, allowing the model to quickly adapt to new tasks with minimal training. The approach is particularly valuable in domains where data annotation is expensive, time-consuming, or impractical, such as specialized medical imaging or rare event detection, offering a practical solution for deploying machine learning in data-constrained environments.
Prototypical Networks address few-shot learning by learning an embedding space where data points are clustered around class prototypes. These prototypes are computed as the mean of the embedded support set examples for each class. Classification is then performed by assigning a query point to the class whose prototype is nearest in the embedding space, typically measured using Euclidean distance. This approach allows for effective generalization from limited examples because it focuses on learning a meaningful representation space rather than memorizing specific instances; the network learns to compare new data to representative exemplars, enabling classification even with only a few labeled samples per class.
Data augmentation techniques address limitations caused by insufficient training data by creating modified versions of existing samples. These modifications can include geometric transformations such as rotations, flips, and zooms, as well as alterations to color properties like brightness and contrast. By systematically applying these transformations, the effective size and variability of the training dataset are increased without requiring the acquisition of new labeled data. This process improves model generalization by exposing it to a wider range of input variations, ultimately enhancing robustness and performance, with observed improvements of approximately 10% in bidirectional training scenarios.
Data augmentation techniques artificially expand training datasets by creating modified versions of existing images. These transformations, which can include rotations, flips, and color adjustments, expose the model to a wider range of variations, enabling it to learn features that are less sensitive to specific image characteristics and thus more generalizable. Implementation of bidirectional training, a specific data augmentation strategy, demonstrated an approximate 10% improvement in model performance, indicating a measurable benefit to utilizing these expanded datasets for machine learning tasks.
![Prototypical networks learn to classify query images by embedding both support and query images, then comparing query image features to class prototypes generated from the support set using Masked Average Pooling and average pooling [catalano23].](https://arxiv.org/html/2601.15366v1/figures/theory/prototypical_network.png)
Dynamic Label Injection: A Targeted Approach to Augmentation
DynamicLabelInjection is a data augmentation technique developed to specifically address limitations within the ‘StructuralDefectSegmentation’ task. This method generates synthetic training data by programmatically injecting defect instances – representing structural flaws – from source images into target images. The process aims to increase the volume and diversity of training examples, particularly focusing on under-represented defect types. This targeted augmentation differs from general techniques by focusing on the specific characteristics of structural defects, allowing the model to learn more robust feature representations for accurate segmentation.
DynamicLabelInjection generates synthetic training data by transferring defect instances from source images onto target images. This process directly addresses data diversity limitations and class imbalance common in structural defect segmentation tasks. Specifically, identified defects-such as cracks or voids-are extracted from images where they are present and then realistically composited into images that may initially lack those specific defect types or have a lower representation of them. The resulting synthetic images, paired with corresponding adjusted labels, effectively increase the prevalence of under-represented defect classes and expose the model to a broader range of defect appearances, thereby improving generalization and segmentation accuracy.
The strategic injection of defects into training images facilitates the model’s acquisition of a more robust feature space for anomaly detection. This process exposes the segmentation network to variations in defect morphology, scale, and position that may not be adequately represented in the original dataset. Consequently, the model develops an enhanced capacity to generalize across diverse defect presentations and identify subtle anomalies which would otherwise be missed due to limited training examples. The increased variability in injected defects effectively simulates a wider range of real-world defect scenarios, leading to improved performance on unseen data and reduced false negative rates during defect segmentation.
Traditional data augmentation techniques often apply generic transformations, which may not effectively address the specific challenges of defect segmentation. DynamicLabelInjection improves upon these methods by directly targeting data augmentation to the underrepresented defect classes, increasing their prevalence in the training set. This targeted augmentation strategy results in a more balanced dataset, allowing the segmentation model to learn more robust feature representations for subtle defect characteristics. Consequently, the model demonstrates improved performance metrics – specifically, increased precision and recall – in identifying and delineating structural defects compared to models trained with conventionally augmented or non-augmented datasets.
![Dynamic label injection augments training data by replacing defect-free samples with synthetically defective ones created by injecting defects from other images, as described in [caruso24].](https://arxiv.org/html/2601.15366v1/figures/theory/dli.png)
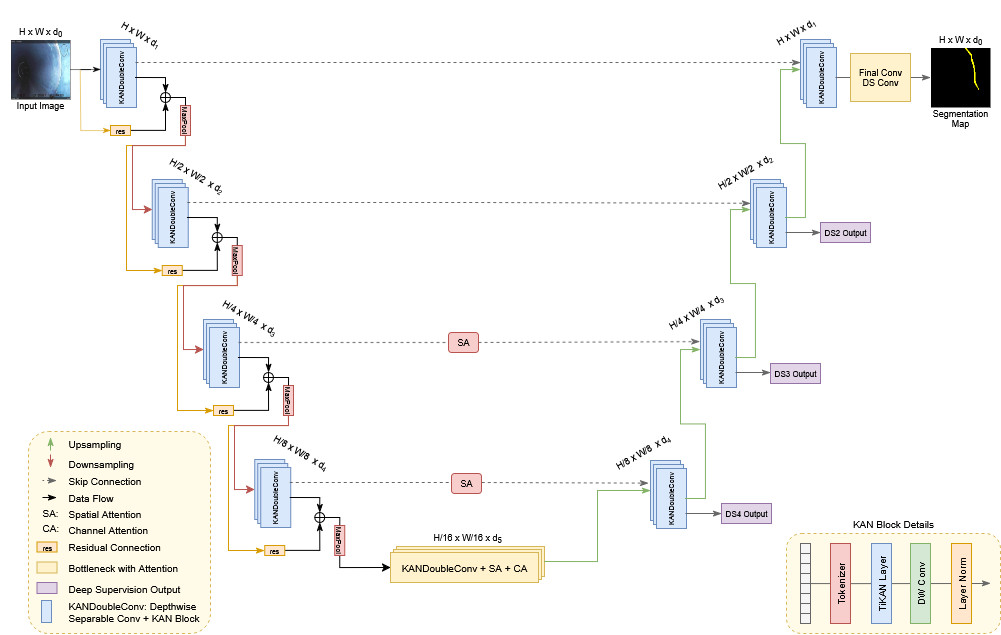
FORTRESS: An Efficient Architecture for Robust Defect Segmentation
A new deep learning architecture, dubbed FORTRESS, offers a compelling solution for the challenging task of structural defect segmentation. This innovative design prioritizes both accuracy and computational efficiency, addressing a critical need in fields like civil infrastructure inspection and materials science. By enabling precise identification of defects – such as cracks, corrosion, or spalling – FORTRESS facilitates timely maintenance and prevents potentially catastrophic failures. The architecture’s novelty lies in its ability to achieve high performance with a significantly reduced model size, making it suitable for deployment on resource-constrained platforms and enabling real-time analysis of complex structural data. This advancement promises to streamline defect detection workflows and enhance the reliability of critical infrastructure systems.
The FORTRESS architecture significantly reduces computational demands and model complexity through the implementation of Depthwise Separable Convolutions. Traditional convolutional layers process all input channels simultaneously, demanding substantial resources. In contrast, Depthwise Separable Convolutions decompose this process into two steps: first, a depthwise convolution applies a single filter to each input channel, and second, a pointwise convolution linearly combines the outputs. This decomposition dramatically reduces the number of parameters and computational operations required, enabling the model to maintain high performance with a significantly smaller footprint. By strategically employing this technique, FORTRESS achieves a substantial reduction in model size and computational cost without compromising its ability to accurately identify structural defects.
The FORTRESS architecture integrates a Kernel Attention Network (KAN) to refine its representation of structural defects, achieving greater accuracy in segmentation. KAN efficiently captures complex patterns by learning kernel functions that emphasize salient features while suppressing noise, thereby enabling the model to discern subtle anomalies often missed by conventional methods. This approach moves beyond simple feature extraction, allowing the network to understand the relationships between features and their significance in identifying defects. By representing these relationships as learned kernels, KAN provides a more robust and adaptable function representation, ultimately improving the model’s capacity to generalize to varied defect types and imaging conditions.
The FORTRESS architecture distinguishes itself through the implementation of multi-scale attention mechanisms, enabling the robust detection of structural defects regardless of their size or prominence. This attention to scale, coupled with other architectural innovations, results in a model that achieves an F1 Score of 0.771 and a Mean IoU of 0.643 – demonstrably surpassing the performance of existing defect segmentation methods. Crucially, this enhanced accuracy is achieved with remarkable efficiency; FORTRESS requires only 2.89 million parameters – a 63% reduction compared to the next best performing model – and operates at 1.17 GFLOPS, highlighting its potential for deployment in resource-constrained environments.
The pursuit of automated defect segmentation, as demonstrated by this research into culvert-sower inspection, inevitably invites a certain skepticism. The team champions FORTRESS and few-shot learning to address data scarcity, but it’s a temporary reprieve. As Yann LeCun once stated, “If you don’t have a plan, you’re part of someone else’s plan.” This neatly encapsulates the reality: each advance in deep learning architecture-be it CNNs or KANs-merely delays the inevitable accumulation of technical debt. The ‘novelty’ of improved segmentation will eventually be eroded by the introduction of new failure modes, necessitating further architectural adjustments. The cycle repeats. It’s not about eliminating the problem, but continually refining the crutches.
So, What Breaks Next?
The pursuit of automated defect segmentation, particularly in the constrained environments of limited labeled data, will inevitably encounter the usual brick walls. FORTRESS, KANs, and the various data augmentation strategies presented here are, at best, temporary reprieves. Production, as always, will reveal the corner cases – the oddly lit culvert, the unexpectedly textured sewer, the defect that looks like normal wear and tear. The current focus on architectural novelty feels…familiar. A slightly different arrangement of convolutional layers isn’t a solution, merely a rebranding of existing problems.
The real challenge isn’t building a more elegant algorithm, but accepting that perfect generalization is a fantasy. Future work will likely circle back to simpler models, prioritizing robustness and interpretability over sheer representational capacity. Expect to see more emphasis on uncertainty quantification – knowing when the algorithm is likely to be wrong is almost as useful as knowing what is wrong.
Ultimately, this field, like all others, will discover that everything new is old again, just renamed and still broken. The interesting question isn’t whether these techniques will succeed, but how spectacularly they will fail, and what entirely predictable mess will be left behind for the next generation to clean up.
Original article: https://arxiv.org/pdf/2601.15366.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Gold Rate Forecast
- All Itzaland Animal Locations in Infinity Nikki
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- How to Get to the Undercoast in Esoteric Ebb
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- $2B AI cow collars use “cowgorithm” to herd cattle with no fences
- TV Characters That Underwent Dramatic Appearance Changes Over Time
2026-01-24 05:43