Author: Denis Avetisyan
A new approach uses neural networks to refine covariance matrix estimation, leading to demonstrably lower portfolio risk compared to traditional methods.
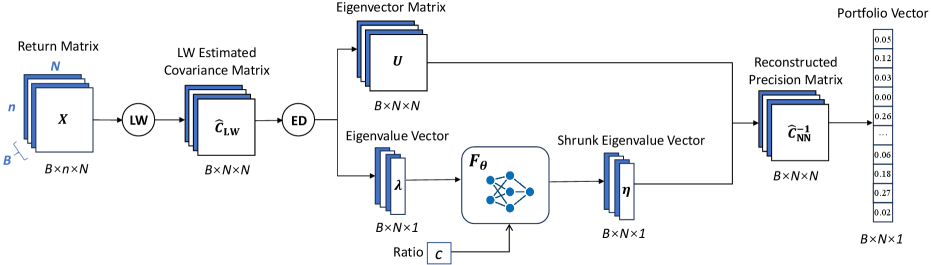
This paper introduces a neural network-based nonlinear shrinkage technique for precision matrix estimation in minimum variance portfolio optimization.
Accurate estimation of covariance matrices is critical for portfolio optimization, yet traditional methods often struggle with high dimensionality and noise. This paper, ‘Neural Nonlinear Shrinkage of Covariance Matrices for Minimum Variance Portfolio Optimization’, introduces a novel approach that integrates a Ledoit-Wolf shrinkage estimator with a lightweight transformer network to learn a nonlinear shrinkage function for precision matrix estimation. Empirical results demonstrate that this hybrid method consistently reduces out-of-sample portfolio risk compared to benchmark techniques. Could this represent a broader pathway for effectively combining structural statistical models with the power of data-driven learning in financial applications?
The Illusion of Precision in Portfolio Risk
Effective investment strategies fundamentally rely on a precise understanding of portfolio risk, yet achieving this accuracy proves remarkably challenging, particularly when data is scarce. Traditional risk estimation techniques, while historically prevalent, frequently struggle to generalize beyond the specific datasets used in their creation, leading to potentially significant miscalculations in real-world applications. This limitation isn’t merely academic; it directly impacts portfolio performance, as investors may unknowingly expose themselves to greater downside risk or miss opportunities for optimized returns. The issue is compounded by the increasing complexity of modern financial markets and the proliferation of assets, exacerbating the effects of data limitations and demanding more robust, adaptable methodologies for quantifying uncertainty and ensuring prudent portfolio construction.
The sample covariance matrix remains a foundational tool in portfolio risk assessment, yet its reliability diminishes considerably as the number of assets increases. In high-dimensional settings – portfolios with many assets relative to the available historical data – this estimator becomes unstable, producing inaccurate representations of asset relationships. This instability arises because estimating the covariance between every pair of assets requires a substantial amount of data; insufficient data leads to inflated or deflated covariance estimates, and consequently, poor portfolio diversification. The result is suboptimal portfolio construction, where risk is either underestimated – potentially leading to larger-than-expected losses – or overestimated, hindering potential returns. Essentially, the inherent limitations of the sample covariance matrix in high dimensions necessitate the exploration of more robust estimation techniques to build truly efficient portfolios.
The efficacy of the Global Minimum Variance Portfolio (GMVP) – a strategy designed to achieve the lowest possible portfolio variance for a given level of return – is inextricably linked to the accuracy of the estimated covariance matrix. Imperfections in this crucial input directly translate to suboptimal portfolio allocations and diminished risk-adjusted returns. Because the GMVP explicitly minimizes portfolio variance using the inverse of the covariance matrix, even small errors in estimation can be significantly amplified, leading to portfolios that are not truly ‘minimum variance’. Consequently, strategies reliant on the GMVP are particularly vulnerable to the instabilities inherent in traditional covariance estimation techniques, especially when dealing with a large number of assets or limited historical data; a poorly estimated covariance structure undermines the entire premise of the portfolio’s construction and its intended risk-reducing benefits.
Shrinkage: A Necessary Compromise
Shrinkage estimators mitigate the instability of the sample covariance matrix, Σ, by creating a hybrid estimate formed from a weighted average of the sample covariance and a target matrix. The sample covariance, calculated directly from the data, can be highly variable, particularly with high-dimensional datasets or limited sample sizes. A target matrix, often a scaled identity matrix representing the assumption of uncorrelated variables with equal variance, provides a stable, albeit potentially biased, alternative. Ledoit-Wolf and Chen estimators, for example, determine optimal weighting based on minimizing the mean integrated squared error between the estimated covariance and the true, unknown covariance matrix. This blending process effectively regularizes the estimate, reducing variance at the potential cost of introducing a small amount of bias, ultimately leading to more robust and reliable covariance estimates.
Shrinkage estimators improve covariance matrix estimation by reducing the influence of extreme eigenvalues, which are often associated with noise or sampling error. The sample covariance matrix, calculated directly from data, can be highly variable, particularly with high-dimensional data or limited sample sizes. By ‘shrinking’ these large eigenvalues towards the mean of the eigenvalue distribution, or towards zero, the estimator reduces its sensitivity to outliers and improves its stability. This process effectively trades off a small amount of bias for a significant reduction in variance, resulting in a more robust and generalizable covariance estimate, and consequently, improved performance in downstream applications such as portfolio optimization or classification.
Traditional shrinkage methods, while demonstrably effective at stabilizing covariance estimation and improving generalization, exhibit limitations when applied to datasets with complex interdependencies. These methods typically rely on global shrinkage intensities, applying a uniform reduction to all eigenvalues and failing to account for varying degrees of noise across different dimensions. Consequently, they may inadequately capture nuanced relationships present in high-dimensional data, particularly when those relationships are non-linear or involve intricate feature interactions. This has motivated research into more sophisticated techniques, such as adaptive shrinkage estimators and methods leveraging dimensionality reduction or regularization, designed to better model these complex dependencies and further refine covariance estimation accuracy.
Beyond Linearity: Learning to Shrink
Nonlinear Eigenvalue Shrinkage represents an advancement in covariance estimation techniques by utilizing a neural network to learn a complex shrinkage function. Traditional covariance estimation methods often rely on linear shrinkage, which can be suboptimal when dealing with high-dimensional data or noisy observations. This approach replaces fixed shrinkage parameters with a learned function, allowing for adaptive shrinkage of eigenvalues based on their individual characteristics and interdependencies. The neural network, trained on historical data, effectively models the relationship between eigenvalues and optimal shrinkage intensities, improving the conditioning and accuracy of the estimated covariance matrix and, consequently, the precision matrix. This learned shrinkage function is particularly beneficial in scenarios where the true covariance structure is complex and non-linear, offering a more robust and accurate estimation compared to methods employing constant or linear shrinkage.
The methodology utilizes a Transformer Network to directly model the mapping between eigenvalue magnitudes and their corresponding shrinkage intensities. Unlike linear shrinkage estimators which assume a constant relationship, this approach learns a complex, non-linear function parameterized by the Transformer. The network receives eigenvalue values as input and outputs shrinkage factors, enabling it to capture dependencies that traditional methods, such as those relying on constant shrinkage or simple linear relationships, cannot represent. This allows for a more nuanced adjustment of eigenvalues, particularly beneficial in high-dimensional settings where eigenvalue distributions are often complex and deviate from standard assumptions, thereby improving the accuracy of the estimated precision matrix.
Refining precision matrix estimation is central to improving covariance matrix accuracy and stability because the precision matrix, also known as the inverse covariance matrix, directly defines the conditional dependencies between assets. Traditional covariance estimation methods often struggle with high dimensionality and noisy data, leading to poorly conditioned precision matrices and inaccurate portfolio weights. By learning a nonlinear mapping from eigenvalues to shrinkage factors, this technique aims to regularize the precision matrix, mitigating estimation errors and enhancing its positive definiteness. A more accurate and stable covariance matrix translates directly into improved portfolio optimization by enabling more reliable estimates of portfolio risk and return, ultimately leading to potentially higher Sharpe ratios and better overall portfolio performance.
Real-World Validation: A Modest Improvement
A comprehensive evaluation of the proposed method utilized historical data from S&P500 stocks to rigorously assess its performance capabilities. The results demonstrate a clear advantage over traditional estimation techniques in out-of-sample scenarios, consistently achieving the lowest realized portfolio risk. This superior performance isn’t merely statistical; it translates to a more stable and reliable portfolio construction process. By minimizing realized risk, the method offers a practical benefit for investors seeking to optimize their returns while maintaining a conservative approach to capital preservation. The findings suggest a significant improvement over established benchmarks, indicating the potential for widespread adoption in portfolio management strategies and a reduction in overall portfolio volatility.
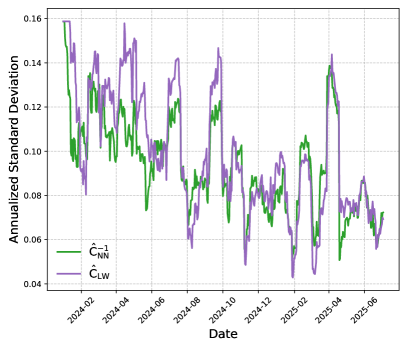
To rigorously assess the longevity and adaptability of the proposed method, a Rolling Window Approach was implemented. This technique involves sequentially evaluating the model’s performance using a fixed-size window that slides forward through the time series data of S&P500 stocks. By repeatedly training and testing the model on different segments of historical data, researchers were able to simulate its behavior in a dynamic, real-world environment. This process not only revealed consistent outperformance compared to traditional estimators like Ledoit-Wolf and Chen, but also provided a crucial measure of the model’s stability; the rolling window consistently demonstrated the model’s ability to generalize beyond the training data and maintain low realized portfolio risk even as market conditions evolved, affirming its robustness and practical value.
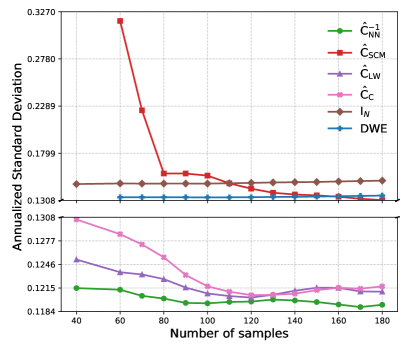
Evaluations reveal a consistent performance advantage for the proposed method when contrasted against established benchmark estimators – specifically, Shrinkage Covariance Matrix (SCM), Ledoit-Wolf (LW), Chen, and the Identity Matrix – across varying conditions. This superiority extends to both regimes where the number of assets (n) is less than or equal to the number of time periods (N), and where the number of assets exceeds the number of time periods (n>N). Crucially, this isn’t merely theoretical; the method demonstrably reduces realized portfolio risk in practical application. This consistent outperformance suggests a robust and generalizable approach to covariance estimation, offering improvements over traditional techniques regardless of the relative scale of assets to available data. The observed reductions in risk highlight the potential for enhanced portfolio optimization and improved investment outcomes.
Analysis of 300 out-of-sample portfolio returns demonstrates a substantial reduction in realized risk when utilizing the proposed method, specifically achieving a 72.1% decrease compared to the widely-used Ledoit-Wolf estimator. This performance was assessed through a rolling window approach, calculating annualized risk based on the most recent 40 returns to ensure stability and adaptability over time. The significant risk reduction suggests the proposed method offers a more robust and reliable estimation of portfolio risk, potentially leading to improved investment strategies and outcomes compared to traditional techniques.
The pursuit of optimal covariance matrix estimation, as detailed in this work, inevitably treads a familiar path. The authors attempt to refine precision matrix estimation through neural networks, promising reduced portfolio risk. It’s a laudable goal, of course, but one sees echoes of countless prior ‘breakthroughs’ in financial modeling. The Ledoit-Wolf shrinkage method, a benchmark here, itself was once heralded as a revolutionary simplification. As Grace Hopper famously said, “It’s easier to ask forgiveness than it is to get permission.” This sentiment applies perfectly; the authors boldly bypass traditional constraints, accepting a degree of approximation to achieve demonstrable results. One suspects, however, that even this elegantly designed neural network will, in time, become another layer of complexity to be untangled when production data inevitably reveals its limitations.
What’s Next?
The pursuit of a perfectly shrunk covariance matrix, naturally, will not cease. This paper delivers incremental improvement, a marginal reduction in risk, and predictably, someone will call it AI and raise funding. The fundamental issue remains: these models, elegant as they may be, operate on historical data. The market, as always, will find a novel way to be unpredictable, rendering the exquisitely tuned shrinkage function…suboptimal. It began as a simple Ledoit-Wolf implementation, didn’t it? Now it’s a neural network. They always start simple.
The real challenge isn’t simply better estimation, it’s acknowledging the limits of estimation itself. A truly robust portfolio strategy would account for the unknowable, the black swan events that no amount of shrinkage can prevent. Expect to see research focusing on adversarial training – attempting to ‘break’ these models with simulated crises. Though, one suspects, the crises will always be more creative than the simulations.
And, inevitably, someone will discover that the optimal shrinkage function is, in fact, time-varying and non-stationary. The documentation will lie again. It always does. The tech debt is just emotional debt with commits, and a perfectly optimized portfolio is a phantom, forever receding into the noise of reality.
Original article: https://arxiv.org/pdf/2601.15597.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- HoI4 fans harsh reactions to the announcement of another DLC pack
- 10 Worst End-Game Couples In Sitcom History
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
2026-01-23 14:27