Author: Denis Avetisyan
As cloud infrastructure grows, so does the deluge of alerts, demanding intelligent systems to prioritize critical issues and reduce operator burnout.
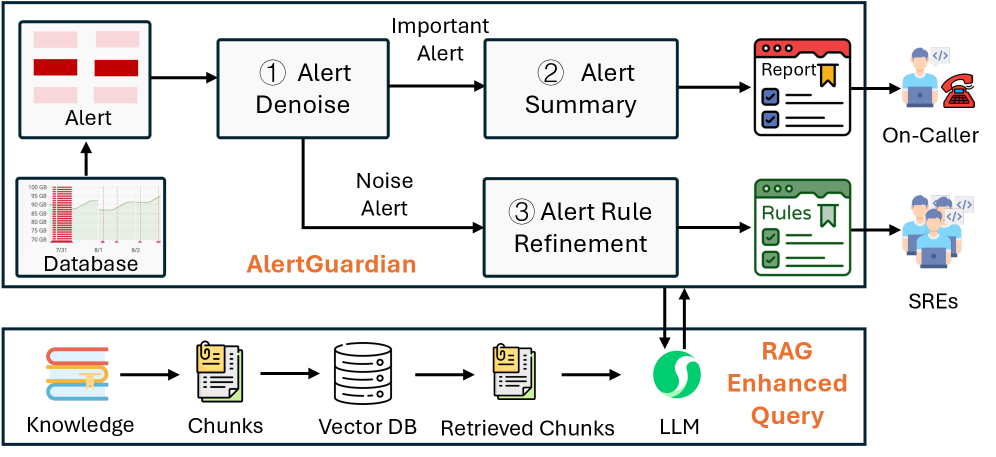
This paper introduces AlertGuardian, a framework leveraging large language and graph models for comprehensive alert lifecycle management, including denoising, refinement, and improved fault diagnosis.
Despite the critical role of alerts in maintaining the reliability of large-scale cloud systems, operational efficiency is often undermined by overwhelming volumes of notifications. This paper introduces AlertGuardian: Intelligent Alert Life-Cycle Management for Large-scale Cloud Systems, a novel framework designed to address this challenge by intelligently managing alerts throughout their entire life-cycle. AlertGuardian leverages large language models and graph-based techniques to significantly reduce alert fatigue and accelerate fault diagnosis. Can this approach pave the way for truly proactive and self-healing cloud infrastructure?
The Relentless Tide: Managing Alert Overload in Modern Systems
Contemporary cloud infrastructure, by its very nature, produces a relentless stream of operational alerts. This isn’t simply a matter of increased monitoring; the dynamic, distributed, and microservice-based architectures common today generate alerts at a scale previously unimaginable. Each component, transaction, and dependency potentially triggers notifications, resulting in thousands of alerts per day for even moderately complex systems. This sheer volume quickly overwhelms Site Reliability Engineers (SREs), creating a situation where genuinely critical issues are obscured by a flood of noise. The problem isn’t a lack of observability, but rather an inability to effectively process and prioritize the signals amidst the overwhelming data, leading to alert fatigue and increased risk of service disruptions.
Conventional alert management systems often depend on engineers to painstakingly define thresholds and rules for each monitored metric, a practice increasingly proving unsustainable in dynamic cloud environments. This manual configuration, while seemingly logical, generates a high volume of notifications – many of which are false positives or represent non-actionable events. Consequently, Site Reliability Engineers experience what is known as “alert fatigue,” a state of diminished responsiveness where genuine critical issues can be overlooked amidst the noise. The sheer number of alerts overwhelms cognitive capacity, increasing the risk of delayed responses and ultimately impacting system reliability; a precise, automated approach is required to effectively discern signal from noise and prioritize truly impactful incidents.
As cloud-native architectures evolve, systems are increasingly composed of interconnected microservices, dynamic infrastructure, and intricate data pipelines. This inherent complexity dramatically increases the sheer volume of potential alerts, but more critically, it obscures the causal relationships between them. Traditional, static threshold-based alerting struggles to differentiate between transient noise and genuine incidents within this dynamic environment. Consequently, SREs face a growing challenge in accurately filtering alerts, often overwhelmed by a flood of notifications that require manual investigation to determine true impact. This makes effective prioritization exceptionally difficult, increasing the risk of overlooking critical issues buried within the constant stream of less significant events and ultimately hindering the ability to maintain system reliability.
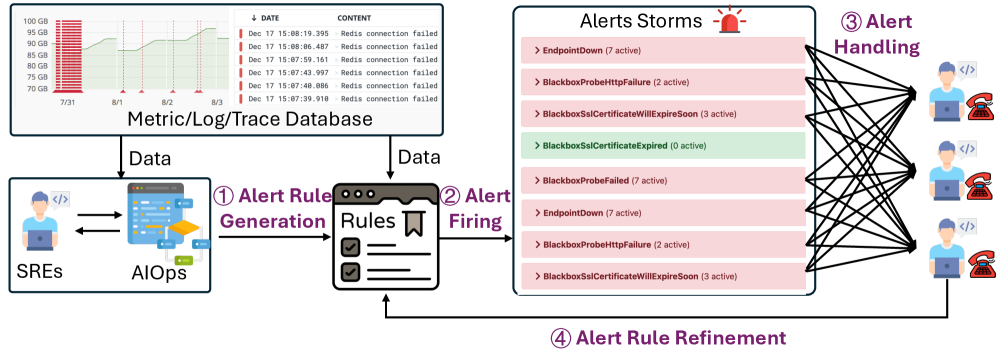
Refining the Signal: A Multi-Faceted Approach to Alert Management
Effective alert management is not a one-time configuration, but an iterative process of rule refinement. Initial alert rules, while addressing immediate needs, frequently generate a high volume of notifications, many of which are irrelevant or represent transient conditions – contributing to alert fatigue. Continuous refinement involves analyzing alert data to identify false positives, adjust thresholds for sensitivity, and correlate alerts to reduce redundancy. This process requires ongoing monitoring of alert performance metrics, such as mean time to resolution (MTTR) and the ratio of actionable alerts to total alerts generated. By systematically adjusting rules based on observed data, organizations can minimize noise, improve the signal-to-noise ratio, and ensure that alerts accurately reflect genuine issues requiring attention, ultimately enhancing operational efficiency and reducing response times.
Optimizing alert rule sets necessitates the implementation of techniques including rule aggregation, deduplication, and threshold adjustment. Rule aggregation combines multiple, similar rules into a single, more efficient rule, reducing computational load and simplifying management. Deduplication identifies and removes redundant rules that trigger on the same conditions, minimizing duplicate alerts. Threshold adjustment involves modifying the trigger values for alerts; raising thresholds decreases alert frequency at the cost of potentially missing critical events, while lowering them increases sensitivity and the potential for false positives. These techniques, when applied iteratively, contribute to a reduction in alert noise and improved signal-to-noise ratio, ultimately enhancing the effectiveness of alert management systems.
Temporal analysis refines alert rules by integrating time-based criteria, thereby minimizing false positives stemming from anticipated occurrences. This involves establishing conditions based on specific times, days of the week, or even recurring schedules. For example, a server backup process generating informational alerts can be configured to suppress notifications during its scheduled runtime. Similarly, scheduled maintenance windows can be defined to exclude associated alerts from triggering during those periods. By acknowledging and accommodating predictable events, temporal analysis significantly reduces alert fatigue and allows security teams to prioritize genuinely anomalous activity. The effectiveness of this technique relies on accurate identification of recurring patterns and precise definition of time-based conditions within the alerting system.

AlertGuardian: Leveraging Intelligence to Distill Critical Insights
AlertGuardian is an integrated framework designed to improve the management of alerts generated by complex IT systems. It combines graph learning models with Large Language Models (LLMs) to address challenges throughout the entire alert life-cycle, from initial signal detection to final resolution. The framework leverages graph learning to identify and suppress redundant or irrelevant alerts, reducing alert fatigue and focusing analyst attention on critical issues. Subsequently, LLMs, utilizing a Retrieval-Augmented Generation (RAG) approach, process remaining alerts to generate concise summaries and provide relevant contextual information, facilitating faster and more accurate diagnosis and remediation.
The AlertGuardian framework utilizes a graph learning model to reduce alert noise by identifying and filtering irrelevant signals. Evaluation across four distinct cloud systems demonstrated an alert reduction ratio ranging from 93.82% to 95.50%. This denoising process focuses on correlating alerts based on underlying relationships within the system, effectively suppressing redundant or false positive signals before they escalate. The model’s performance indicates a substantial decrease in the volume of alerts requiring manual investigation, leading to improved operational efficiency and reduced alert fatigue.
AlertGuardian leverages Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) to improve the quality and actionability of security alerts. RAG enables the LLM to access and incorporate relevant information from external knowledge sources during alert processing, facilitating detailed summarization and the provision of contextual insights beyond the alert data itself. This process significantly enhances diagnostic efficiency for security analysts and demonstrably improves action accuracy, achieving a measured rate of 98.5% in testing environments.

Beyond Reaction: Towards Proactive Reliability and Reduced Cognitive Load
Site Reliability Engineers (SREs) often face a deluge of alerts, a significant contributor to alert fatigue and diminished responsiveness. AlertGuardian addresses this challenge by intelligently filtering and summarizing incoming alerts, substantially reducing the cognitive load on SREs. This framework doesn’t simply suppress notifications; it prioritizes genuine incidents, enabling engineers to focus their attention and expertise where it matters most. By minimizing exposure to false positives and low-priority signals, AlertGuardian facilitates quicker identification of critical issues and accelerates incident response times, ultimately bolstering system stability and minimizing downtime. The result is a more effective and less stressed SRE team, capable of proactively maintaining service health rather than reactively battling a constant stream of noise.
The system achieves comprehensive observability by intelligently aggregating data from diverse monitoring sources, notably integrating with platforms like Prometheus to capture a wealth of alert attributes. This isn’t simply about collecting more data, but about contextualizing it; the framework correlates seemingly disparate signals – CPU usage, error rates, latency spikes – into a unified representation of system health. By analyzing these attributes, the system builds a dynamic profile of normal behavior, allowing it to rapidly identify anomalies that deviate from the established baseline. This holistic approach moves beyond isolated symptom detection, enabling a more accurate and proactive understanding of underlying issues and reducing the incidence of false positives that contribute to alert fatigue.
The system’s capacity to synthesize insights from historical incident reports represents a significant advancement in reliability engineering. By integrating these reports into a Retrieval-Augmented Generation (RAG) process, the framework enables Large Language Models to learn directly from past system failures and their resolutions. This learning loop dramatically improves the accuracy and relevance of alert summaries, ultimately achieving a 90.5% accuracy rate in root cause analysis. Further demonstrating its effectiveness, the system generated 117 actionable rules that were accepted, indicating a high degree of confidence in its diagnostic and preventative capabilities. This proactive approach shifts the focus from reactive incident response to predictive reliability, fostering a more resilient and stable system architecture.
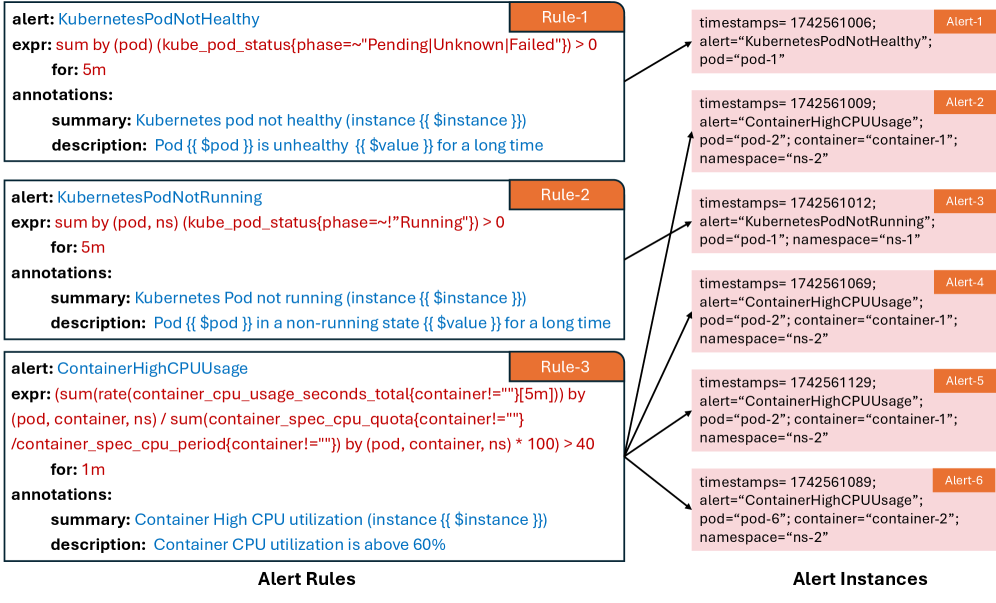
AlertGuardian embodies a principle of subtraction as much as addition. The system doesn’t merely add intelligence to alert processing; it actively removes noise and redundancy, streamlining the flow of information. This mirrors a core design philosophy: what remains after rigorous refinement is what truly matters. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” AlertGuardian, in a similar vein, doesn’t wait for perfect data; it intelligently processes what is available, filtering out the extraneous to facilitate swift and accurate fault diagnosis. The framework’s use of LLMs and graph neural networks isn’t about creating complexity, but about achieving clarity through focused analysis, addressing the critical issue of alert fatigue in large-scale systems.
The Road Ahead
AlertGuardian, in its attempt to impose order on the chaos of cloud systems, highlights a fundamental truth: the problem isn’t merely the volume of alerts, but the persistence of failure. A truly effective system wouldn’t require life-cycle management; it would preclude the need for alerts altogether. The framework’s reliance on denoising and refinement, while pragmatic, acknowledges an underlying acceptance of imperfection. Future work should not focus solely on making bad alerts ‘less bad’, but on engineering resilience into the systems generating them.
The application of large language models and graph neural networks represents a logical, if computationally expensive, progression. However, the current paradigm treats symptoms, not causes. A fruitful avenue lies in proactive anomaly detection – anticipating failure modes before they manifest as alerts. This demands a shift from reactive analysis to predictive modeling, ideally one requiring minimal human intervention, and even less instruction. A system that needs to be ‘taught’ what constitutes a fault has already conceded defeat.
Ultimately, the metric of success isn’t reduced alert fatigue, but silent operation. The absence of alerts should not be interpreted as a lack of monitoring, but as a testament to robust design. Clarity, after all, is courtesy – and the most courteous system is one that requires no explanation.
Original article: https://arxiv.org/pdf/2601.14912.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- 10 Worst End-Game Couples In Sitcom History
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Hatsune Miku cosplayer goes viral selling $15 cups of “foot juice” to thirsty anime fans
- Marvel’s New R-Rated Punisher Special Rotten Tomatoes Sets All-Time Audience Record
- DoorDash responds after customer uses AI to make food look bad and get a refund
2026-01-23 02:52