Author: Denis Avetisyan
New research shows that structuring AI systems like human organizations – with specialized roles and independent checks – dramatically improves their performance and error detection.
Applying organizational structures to multi-agent systems enhances reliability and data validation compared to single-agent approaches.
While artificial intelligence agents excel at rapid task completion, their inherent fallibility demands novel approaches to ensure reliable outcomes. This paper, ‘If You Want Coherence, Orchestrate a Team of Rivals: Multi-Agent Models of Organizational Intelligence’, introduces a system inspired by corporate structures, deploying teams of specialized AI agents with opposing incentives to proactively identify and mitigate errors. Our results demonstrate that this orchestration of imperfect components achieves over 90% internal error interception without sacrificing performance, offering a path towards robust AI systems built not on perfection, but on principled redundancy. Could this organizational approach unlock a new paradigm for building scalable and trustworthy AI applications?
The Fragility of Monolithic Intelligence
The SingleAgentSystem, representative of many traditional artificial intelligence approaches, often functions as a monolithic entity – a single, large model attempting to handle entire tasks without internal division. This architecture, while seemingly straightforward, introduces significant vulnerabilities; an error at any stage of processing can propagate throughout the system, leading to cascading failures and unpredictable outcomes. Unlike the distributed and redundant systems prevalent in natural and engineered resilience, these monolithic models lack inherent adaptability. When confronted with novel or unexpected inputs, the system struggles to isolate and correct the source of the problem, often resulting in complete task failure or demonstrably flawed results. This limitation underscores a critical difference between current AI and truly robust intelligence, highlighting the need for more modular and error-tolerant designs.
The effectiveness of many current AI systems is surprisingly reliant on meticulous PromptEngineering – a process of carefully crafting input instructions to nudge the model toward desired outputs. This isn’t a sign of inherent intelligence, but rather a workaround for fundamental limitations; the system’s performance is often less about genuine understanding and more about successfully interpreting the nuances of the prompt. Consequently, even minor variations in phrasing can dramatically alter results, demanding constant refinement and optimization. This iterative process is not only time-consuming and resource-intensive, but also introduces a fragility; a slightly ambiguous or unexpected input can easily lead to errors or irrelevant responses. The dependence on such delicate calibration highlights a core inefficiency, as the system expends considerable effort on how information is presented, rather than on truly understanding and processing the information itself.
The vulnerability of contemporary AI systems to single points of failure stands in stark contrast to the redundancy inherent in natural and engineered resilience. Biological organisms, for instance, don’t rely on a single component for vital functions; multiple overlapping systems ensure survival even with localized damage. Similarly, critical infrastructure – power grids, communication networks, and transportation systems – are designed with layered defenses and alternative pathways to maintain operation despite disruptions. This distributed approach, prioritizing graceful degradation over monolithic performance, offers significantly improved robustness. Unlike these systems, many AI agents concentrate processing and decision-making in a single model, creating a fragile dependency that can lead to catastrophic failures from even minor errors or adversarial attacks. The pursuit of truly reliable AI, therefore, requires a shift towards architectures that embrace redundancy and distribute responsibility, mirroring the proven strategies of resilient systems found throughout the natural world and in our most vital technologies.
Deconstructing Complexity: The Multi-Agent Paradigm
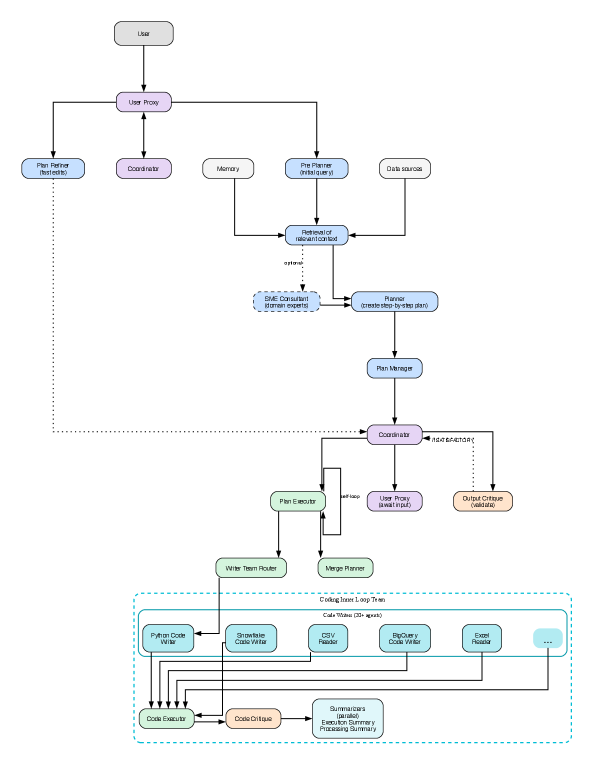
The MultiAgentArchitecture addresses computational complexity by partitioning tasks among multiple specialized agents. This distributed cognitive load allows for parallel processing and improved scalability compared to monolithic systems. Each agent focuses on a specific function, reducing the overall cognitive demands on any single component and enabling more efficient resource utilization. This specialization facilitates modularity, allowing for independent development, testing, and refinement of individual agents without impacting the entire system. Furthermore, the architecture promotes resilience; the failure of one agent does not necessarily compromise the functionality of others, contributing to a more robust and reliable system.
The MultiAgentArchitecture draws parallels to effective organizational design by distributing processing responsibilities across specialized agents, analogous to departments within a company. This compartmentalization allows each agent to focus on a defined task, maximizing efficiency and expertise. Furthermore, the architecture inherently incorporates redundancy and fault tolerance; the failure of a single agent does not necessarily compromise the entire system, mirroring how robust organizations can withstand the loss of individual employees or departments. This approach minimizes systemic risk and improves overall reliability by isolating potential failures and preventing their propagation throughout the system, thereby mitigating collective weaknesses.
The MultiAgentArchitecture relies on two primary agent types: the ExecutorAgent and the PlannerAgent. The PlannerAgent is responsible for defining high-level objectives and formulating the overall plan to achieve them, acting as the system’s goal-setting component. Conversely, the ExecutorAgent translates the plan provided by the PlannerAgent into concrete actions and manages their execution, including resource allocation and task sequencing. This division of labor enables a modular approach where the PlannerAgent focuses on ‘what’ needs to be done, while the ExecutorAgent focuses on ‘how’ to do it, promoting efficient task management and adaptability within the system.
Layered Oversight: Building Reliability Through Independent Validation
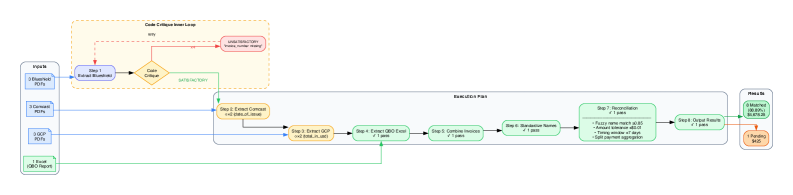
The MultiAgentArchitecture employs StageGatedOversight by integrating independent CriticAgents into each processing step. These agents do not contribute to the primary task execution; instead, they function solely to evaluate the outputs generated at each stage. This evaluation is comprehensive and based on predefined metrics, allowing for continuous monitoring of the system’s performance and adherence to required standards. The implementation ensures that progress is contingent upon critical review, providing a mechanism for early detection of errors or deviations before they propagate through the workflow.
VetoAuthority, as implemented within the MultiAgentArchitecture, functions as a critical safety mechanism by granting CriticAgents the ability to immediately terminate a process if pre-defined AcceptanceCriteria are not satisfied at any stage of execution. These criteria are explicitly defined and represent measurable standards for output quality or operational parameters. Upon detecting a violation of these criteria, the CriticAgent issues a veto, halting further progression and triggering pre-defined fallback or error-handling procedures. This ensures that flawed or potentially harmful outputs are not propagated through the system, prioritizing safety and reliability over continued operation under compromised conditions. The implementation is binary – the CriticAgent either permits continuation or issues a veto, with no intermediary states.
The MultiAgentArchitecture’s layered defense strategy is based on the Swiss Cheese Model of reliability, a concept originating in accident investigation. This model posits that failures are rarely caused by a single, massive error, but rather by a cascading series of smaller failures, or “holes,” in multiple layers of defense. Each layer, while not foolproof, is designed to catch errors that have passed through preceding layers. The effectiveness of the system isn’t reliant on any single layer being perfect; instead, it depends on the cumulative effect of multiple imperfect layers reducing the probability of a failure reaching the final outcome. Increasing the number of layers, and ensuring they are independent, significantly lowers overall risk by requiring multiple failures to align for a system breach to occur.
Demonstrable Impact: Error Reduction and Real-World Application
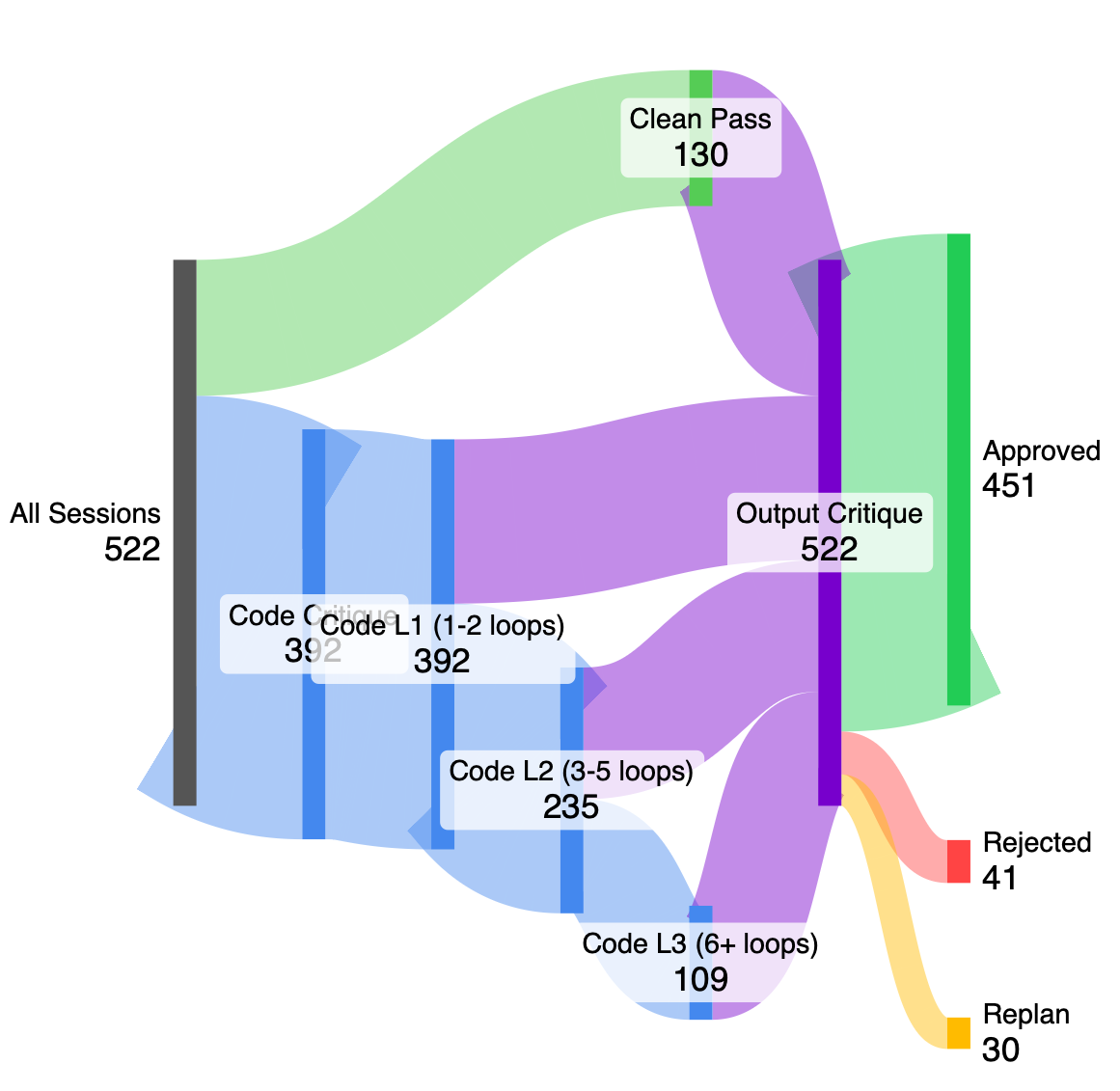
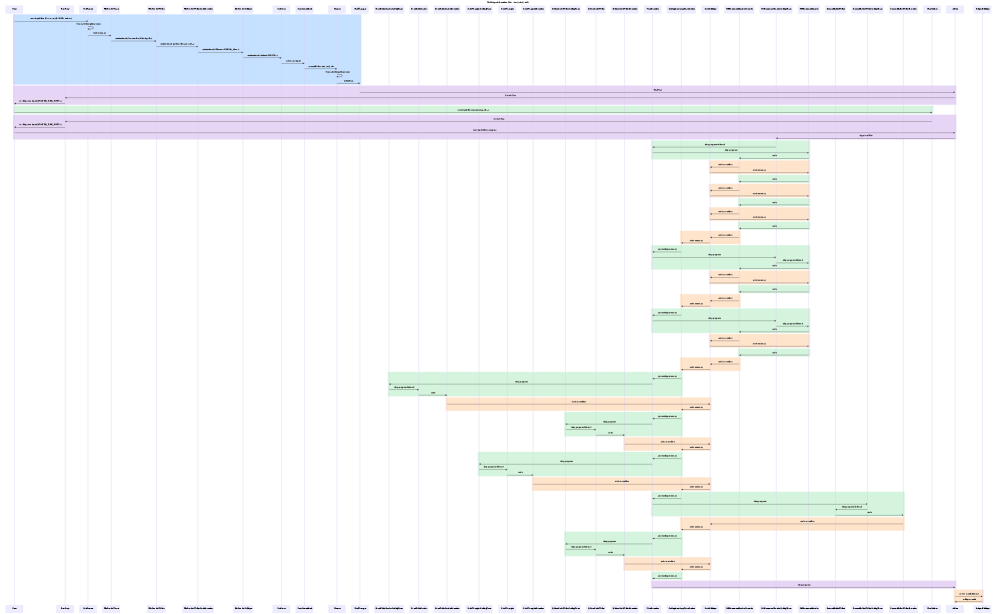
The MultiAgentArchitecture proves particularly effective in complex validation scenarios, such as the FinancialReconciliationTask. This task demands meticulous accuracy, as even minor discrepancies can lead to significant financial consequences. By employing specialized agents focused on specific aspects of the reconciliation process – identifying coding errors, verifying chart data, and cross-referencing transactions – the architecture surpasses the capabilities of conventional systems. This focused approach isn’t simply about identifying more errors, but about pinpointing those most critical to financial integrity, ultimately bolstering trust and reliability in automated financial processes. The system’s ability to swiftly and accurately validate financial data demonstrates its potential to reshape workflows and minimize costly mistakes.
The architecture leverages the power of specialized CriticAgents – notably CodeCritique and ChartCritique – to achieve a level of error detection unattainable by generalized systems. These agents aren’t simply evaluating for correctness; they possess focused expertise. CodeCritique, for instance, meticulously examines the underlying logic and syntax of code, identifying errors a broader system might overlook as stylistic anomalies or inconsequential. Similarly, ChartCritique concentrates on the accurate representation of data within charts and graphs, flagging inconsistencies or misleading visualizations. This granular approach allows the system to pinpoint subtle yet critical flaws, enhancing overall reliability and ensuring a higher degree of accuracy in complex tasks – a strategy that fundamentally improves performance beyond the capabilities of a single, all-encompassing evaluator.
The implemented MultiAgentArchitecture delivers a substantial improvement in error detection capabilities, evidenced by a measured 92.1% success rate. This represents a significant reduction from the initial 75% error rate, leaving a residual error margin of only 7.9%. This heightened accuracy is achieved through a system of cascaded critique, where specialized agent roles – notably CodeCritique and ChartCritique – collaboratively identify and rectify errors. The synergistic effect of these specialized agents results in a combined Inner Loop Catch Rate of 87.8%, demonstrating the efficacy of focused oversight in enhancing the reliability and precision of complex tasks.
Secure by Design: Towards Responsible and Adaptable Intelligence
Data isolation forms a foundational tenet within the MultiAgentArchitecture, functioning as a critical safeguard against potential vulnerabilities and ensuring system integrity. This principle dictates that raw, unprocessed data never directly dictate agent actions; instead, information undergoes a defined transformation and validation process before reaching decision-making components. By interposing this layer of abstraction, the architecture effectively decouples agents from the inherent noise, biases, or malicious content potentially present in incoming data streams. This not only enhances security by preventing data-driven exploits but also promotes more predictable and reliable agent behavior, fostering a robust and trustworthy AI system capable of operating effectively in dynamic and potentially adversarial environments. The implementation of data isolation is therefore central to building AI that is demonstrably safe and aligned with intended objectives.
The MultiAgentArchitecture is intentionally structured to prioritize modularity and scalability, fundamentally simplifying the process of incorporating new agents or adapting to evolving demands. This design philosophy treats each agent as an independent, self-contained unit, communicating via well-defined interfaces rather than direct data access. Consequently, adding new functionalities doesn’t require extensive system-wide revisions; instead, developers can introduce new agents with minimal disruption. This approach not only accelerates development cycles but also enhances the system’s resilience, allowing it to gracefully accommodate changing requirements and scale efficiently to handle increased workloads without compromising performance or stability. The resulting flexibility is crucial for long-term maintainability and ensures the architecture can readily adapt to unforeseen challenges in dynamic environments.
The development of truly responsible artificial intelligence hinges on adopting principles borrowed from well-established organizational structures. Just as resilient organizations prioritize compartmentalization, clear lines of authority, and fail-safe mechanisms, AI systems benefit from a similar approach. This means designing architectures that aren’t monolithic, but rather composed of modular, independently verifiable components. Such a structure not only enhances robustness by limiting the impact of any single point of failure, but also promotes reliability through rigorous testing and validation of individual modules. Ultimately, this embrace of organizational principles is paramount to building AI that is not simply intelligent, but also demonstrably trustworthy, fostering confidence in its deployment and ensuring alignment with human values.
The pursuit of robust artificial intelligence, as demonstrated by this research into multi-agent systems, echoes a fundamental principle of effective organization. Just as a complex organism requires specialized functions and checks against error, so too does a reliable AI. This study highlights that simply scaling a single agent does not guarantee improved performance; instead, structure dictates behavior. As Blaise Pascal observed, “The eloquence of the body is motion, but the eloquence of the mind is silence.” This resonates with the necessity of independent verification and veto authority within these systems – a calculated ‘silence’ that prevents the propagation of errors, ensuring the whole system functions coherently rather than relying on the unchecked output of a single, potentially flawed, component. The orchestration of diverse agents, each with a specific role, creates a resilient and intelligent collective.
Beyond Consensus: Charting a Course for Organizational Intelligence
The demonstrated efficacy of structuring multi-agent systems according to established organizational principles begs a crucial question: what, precisely, are these systems optimizing for? Reliability and error detection, as currently measured, represent necessary but insufficient conditions. A truly intelligent organization doesn’t merely avoid failure; it anticipates and adapts to changing circumstances. Future work must therefore move beyond simply verifying data or detecting errors, and begin to evaluate systems based on their capacity for robust, long-term strategic coherence. The current focus on independent verification and veto authority, while sound, implies a fundamentally adversarial environment. Can systems be designed where specialized roles foster synergistic collaboration, rather than simply checking each other’s work?
Furthermore, the inherent complexity of these organizational structures demands a rigorous re-evaluation of verification methodologies. Traditional testing protocols, designed for monolithic systems, are ill-suited to capture emergent behaviors arising from interactions between specialized agents. A deeper theoretical framework, drawing on insights from organizational sociology and complex systems theory, is required to understand how structure dictates behavior at scale. Simplicity, it must be remembered, is not minimalism; it is the discipline of distinguishing the essential from the accidental.
Ultimately, the challenge lies in moving beyond the engineering of isolated intelligent agents, and toward the cultivation of genuinely intelligent organizations. This necessitates a shift in focus from maximizing individual performance to optimizing collective resilience and adaptive capacity – a subtle but critical distinction.
Original article: https://arxiv.org/pdf/2601.14351.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- HoI4 fans harsh reactions to the announcement of another DLC pack
- 10 Worst End-Game Couples In Sitcom History
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Gold Rate Forecast
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-01-23 01:10