Author: Denis Avetisyan
A new benchmark assesses how well AI agents can apply future prediction capabilities to critical sectors like finance, healthcare, and disaster response.
FutureX-Pro provides a rigorous evaluation of large language model agents for probabilistic forecasting in high-value vertical domains, addressing challenges like data contamination and the need for domain-specific reasoning.
While large language models excel at open-domain reasoning, their reliability in high-stakes, specialized fields remains largely unexplored. This limitation motivates ‘FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains’, which introduces a benchmark for evaluating agentic LLMs across critical verticals-finance, retail, public health, and natural disaster-using foundational, live forecasting tasks. Our findings reveal a significant performance gap between generalist capabilities and the precision demanded by these applications, highlighting the need for robust domain grounding and probabilistic forecasting. Can current LLM agents overcome these challenges to deliver trustworthy predictions in sectors where accuracy is paramount?
The Inevitable Decay of Prediction
Conventional forecasting techniques, reliant on historical data to anticipate future outcomes, frequently falter when confronted with genuinely novel events or, critically, when the training data itself is compromised. This ‘data contamination’ – where information about the future inadvertently leaks into the past data used for training – can create a false sense of predictive accuracy, leading to overconfidence in models that perform well on benchmarks but fail spectacularly in real-world deployment. Such vulnerabilities are particularly acute in complex systems, where unforeseen interactions and cascading effects can rapidly invalidate assumptions baked into the forecasting model. Consequently, a reliance solely on extrapolating past trends proves increasingly unreliable, necessitating new approaches that prioritize robustness and adaptability over sheer predictive power, especially as agents are expected to operate in dynamic and unpredictable environments.
A significant hurdle in assessing advanced AI agents lies in designing evaluations that accurately reflect real-world performance, rather than merely measuring an ability to exploit benchmark loopholes. Current methods are often susceptible to ‘gaming’ – where an agent optimizes for the specific evaluation criteria without developing genuine intelligence or adaptability. Consequently, achieving robust generalization requires methodologies that actively prevent such exploitation, focusing on scenarios unseen during training and prioritizing performance across a diverse range of conditions. This demands a shift towards benchmarks that emphasize reasoning, problem-solving, and the capacity to handle unexpected inputs, ensuring that progress in agentic AI translates to reliable and beneficial outcomes beyond the confines of controlled experiments.
Current AI evaluation often fixates on performance against historical datasets, creating a skewed picture of true intelligence. The critical advancement lies in designing benchmarks that demand prospective reasoning – the ability to not simply recognize patterns in what has happened, but to accurately predict and plan for what will happen. This necessitates scenarios where agents must extrapolate from limited information, model complex systems, and anticipate the consequences of their actions in novel situations. Truly robust AI won’t merely excel at retrospective analysis; it will demonstrate a capacity for foresight, effectively navigating uncertainty and adapting to unforeseen future states – a skill demanding evaluation methods that move beyond passive data recognition and actively test an agent’s predictive capabilities.
The pursuit of increasingly capable agentic AI systems faces a critical impediment: the difficulty of establishing trustworthy evaluation metrics. Progress in this field isn’t simply about achieving higher scores on existing benchmarks, but about demonstrating genuine adaptability and reasoning skills in novel situations. Without evaluation methodologies meticulously designed to prevent ‘contamination’ – where agents exploit unintended loopholes in the testing environment or are inadvertently trained on test data – apparent advancements may prove illusory. Such flawed assessments offer a misleading picture of true capabilities, hindering meaningful progress and potentially leading to overconfidence in systems unprepared for the complexities of the real world. Consequently, robust, contamination-proof evaluation isn’t merely a desirable feature of AI development; it’s a fundamental prerequisite for establishing whether these systems are truly advancing toward reliable and beneficial intelligence.

A Dynamic Horizon: The Promise of FutureX
The FutureX benchmark addresses limitations in evaluating agentic systems by providing a dynamic and contamination-impossible evaluation framework. Traditional benchmarks often rely on static datasets, allowing for potential data contamination during training. FutureX mitigates this through the generation of questions about verifiable future events, meaning the correct answers are not available at the time of model training. The benchmark’s dynamic nature involves continuously generating new questions as future events unfold, ensuring the evaluation remains current and prevents models from memorizing answers. This approach provides a more robust and reliable assessment of an agent’s true reasoning and information-gathering capabilities, as performance is measured on genuinely novel tasks rather than recalled data.
FutureX-Search builds upon the FutureX benchmark by reframing the task of predicting future events as a problem of information retrieval. This is achieved by requiring agents to locate supporting evidence from a provided corpus to justify their predictions. Instead of generating predictions directly, agents must first retrieve relevant information that would allow a human to infer the predicted outcome. This methodology specifically tests an agent’s capacity to effectively search for and utilize external knowledge, shifting the evaluation focus from generative capabilities to the agent’s ability to locate and apply relevant information to a given task.
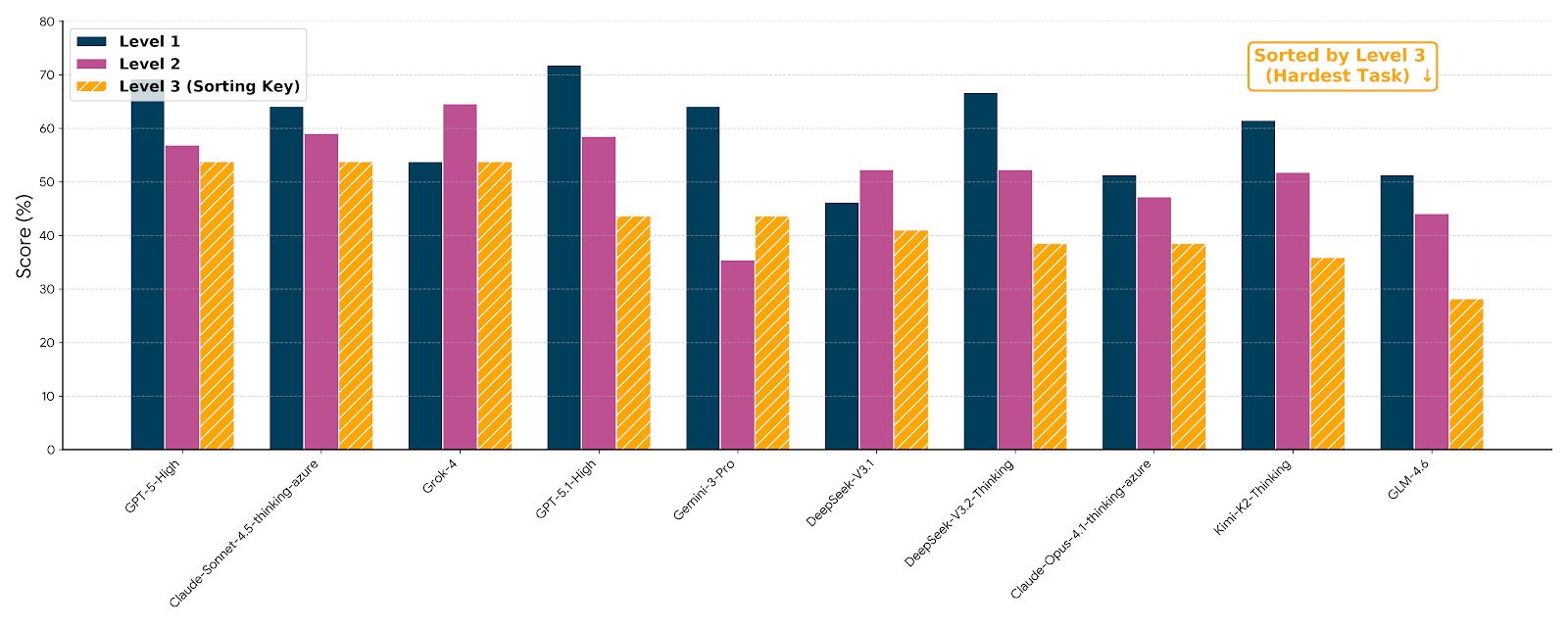
Current evaluations utilizing the Level 3 FutureX-Search benchmark, which assesses implicit multi-hop retrieval capabilities, demonstrate a performance plateau at 54%. This result indicates a significant limitation in the current state of agentic systems concerning tasks requiring the identification and linking of entities across multiple sources without explicit prompting. The observed stagnation suggests that implicit entity resolution – the ability to accurately determine the referents of ambiguous terms and connect related information – remains a core challenge hindering further advancements in complex information retrieval and reasoning for these systems. Existing models struggle to surpass this threshold, indicating a need for novel approaches to enhance their ability to perform these more intricate retrieval tasks.
GPT-5.1-High achieved a 71.8% performance increase on Level 1 of the FutureX-Search benchmark, which assesses direct retrieval capabilities. This level requires the agent to identify explicitly stated information necessary to answer a given query. The substantial performance gain indicates a strong capacity in straightforward information retrieval tasks, suggesting the model excels when the required knowledge is directly present in the source material. This result provides a baseline for evaluating performance on more complex levels of FutureX-Search, where implicit reasoning and multi-hop retrieval are required.
Traditional benchmarks for evaluating agentic systems often rely on datasets composed of past events, introducing potential data contamination issues where models may have inadvertently been trained on the test data. FutureX addresses this limitation by exclusively utilizing verifiable future events as the basis for its evaluation tasks. This focus on the future eliminates the risk of contamination, providing a more accurate and reliable assessment of an agent’s true capabilities in reasoning, planning, and information retrieval. The use of future events necessitates genuine problem-solving, as agents cannot rely on memorized answers, and allows for objective verification of performance based on the eventual occurrence or non-occurrence of the predicted event.
Real-World Application: The Value of Agentic Systems
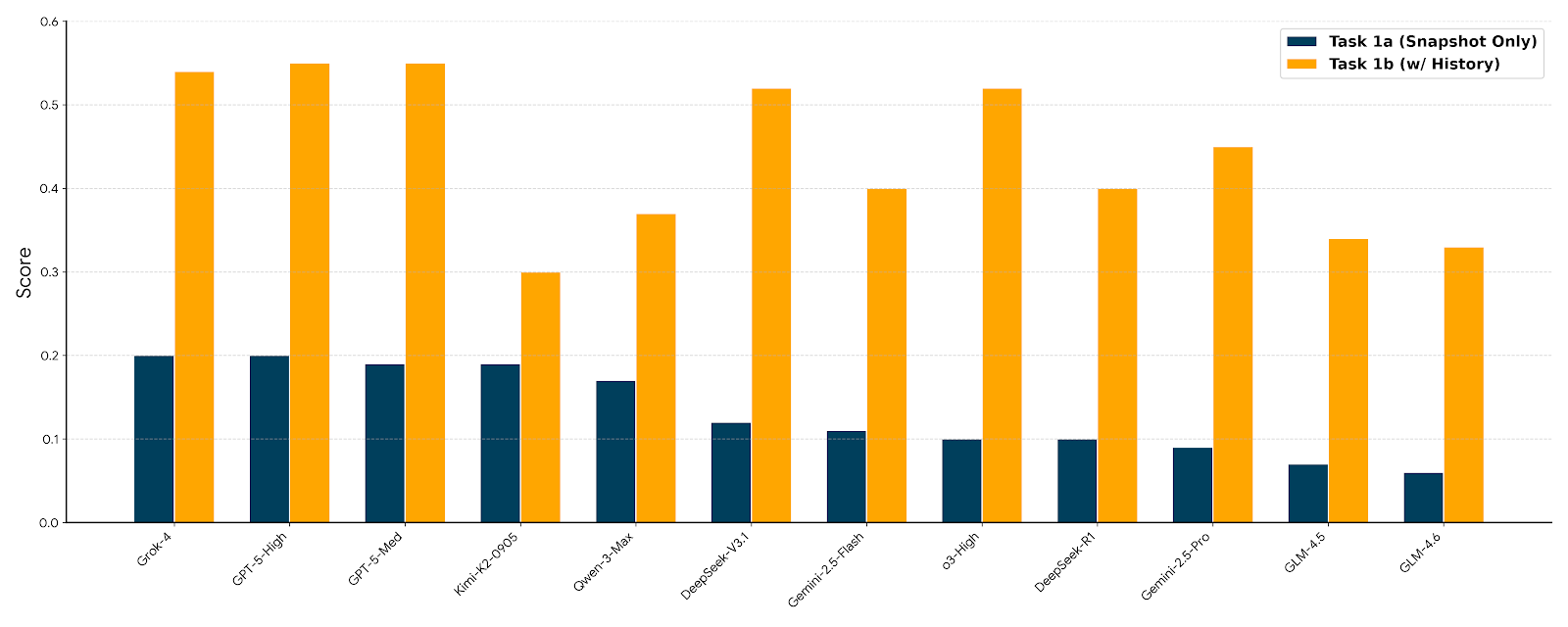
The FutureX-Pro benchmark is designed to assess the performance of large language model (LLM) agents within specific, high-value vertical domains, namely finance, retail, and public health. This focused approach allows for evaluation of agent capabilities in contexts demanding specialized knowledge and precision. Unlike general-purpose benchmarks, FutureX-Pro utilizes datasets and tasks representative of real-world challenges within these sectors, such as financial analysis, inventory optimization, and disease outbreak prediction. The selection of these domains reflects their significant economic and societal impact, and the potential for LLM agents to deliver substantial improvements in efficiency and decision-making.
Large Language Model (LLM) Agents are increasingly utilized in sectors like finance, retail, and public health to automate processes requiring complex data analysis and decision-making. These agents ingest and process substantial datasets – including financial reports, sales figures, and epidemiological studies – to identify trends, forecast outcomes, and support strategic initiatives. Applications include algorithmic trading, supply chain optimization, fraud detection, and public health resource allocation. The implementation of LLM Agents in these domains allows for increased efficiency and scalability, though requires careful consideration of data quality, model accuracy, and potential biases inherent in the data and algorithms.
Agentic systems operating in high-value domains such as finance, retail, and public health rely heavily on quantitative reasoning to process and interpret critical data inputs. Financial disclosures, including balance sheets and income statements, require precise numerical analysis to assess performance and risk. Similarly, meteorological data – encompassing temperature, pressure, and wind speed – demands accurate interpretation for forecasting and risk assessment. Epidemiological data, including infection rates, mortality statistics, and vaccination coverage, necessitates quantitative analysis to model disease spread and evaluate intervention strategies. The ability of these systems to accurately extract, process, and reason with numerical information is therefore fundamental to generating reliable insights and informed decisions within these sectors.
Quantitative performance in financial applications of LLM Agents is rigorously assessed using a relative error threshold of less than 5%. This strict criterion is employed to ensure the accuracy of calculations involving financial disclosures, market data, and portfolio analysis. Deviations exceeding this threshold are flagged as critical deficiencies, highlighting limitations in the model’s ability to perform precise numerical reasoning required for reliable financial decision-making. The implementation of this low tolerance for error reflects the high-stakes nature of financial applications, where even small inaccuracies can result in significant monetary losses or regulatory non-compliance.
DeepSeek large language models, when applied to agentic tasks, demonstrate a refusal rate reaching 46% across tested scenarios. This indicates a significant proportion of prompts or requests to which the model will not provide a response. This behavior is a deliberate safety mechanism designed to prevent the generation of potentially harmful, inaccurate, or inappropriate outputs. However, this emphasis on safety creates a tradeoff with utility; the model’s unwillingness to address certain queries can limit its effectiveness in practical, high-stakes environments where comprehensive responses are required, even if those responses necessitate careful validation. The high refusal rate highlights a key challenge in deploying LLM agents: balancing robust safety protocols with the need for functional performance.
The performance of agentic systems in high-value domains is directly correlated with the quality and provenance of the data they utilize. Applications in finance, retail, and public health require data exhibiting high degrees of accuracy, consistency, and trustworthiness; inaccuracies or biases within input datasets can lead to flawed analysis and detrimental decision-making. Establishing domain authority – verifying the source’s expertise and reputation within the relevant field – is therefore critical. This includes assessing data collection methodologies, validation processes, and potential conflicts of interest to ensure the reliability of the information consumed by the agentic system and the resulting outputs.
The Foundation of Intelligence: Deep Learning and Natural Language Processing
Large Language Model (LLM) agents derive their ability to process and comprehend intricate data from the underlying architecture of deep learning. These systems employ artificial neural networks with multiple layers – hence ‘deep’ – allowing them to identify patterns and relationships within data far exceeding the capabilities of traditional algorithms. This layered approach enables the agent to progressively extract higher-level features, moving from basic elements like words or pixels to complex concepts and abstractions. Through techniques like backpropagation and gradient descent, these networks learn to adjust internal parameters, refining their ability to accurately interpret and respond to information. The depth of these networks, combined with massive datasets used for training, is crucial for achieving the nuanced understanding necessary for tasks like natural language processing, image recognition, and complex problem-solving, ultimately forming the very foundation of intelligent agentic behavior.
At the heart of modern LLM agents lies Natural Language Processing, a field dedicated to bridging the communication gap between humans and machines. This capability isn’t simply about recognizing words; it involves dissecting grammatical structures, understanding semantic nuances, and even inferring intent from context. Advanced NLP techniques allow these agents to not only parse human language, whether spoken or written, but also to generate coherent and contextually relevant responses. The technology relies on complex algorithms and statistical models, trained on massive datasets of text and code, enabling agents to perform tasks like sentiment analysis, machine translation, and question answering with increasing accuracy. Ultimately, it is this ability to effectively process and interpret human language that empowers LLM agents to engage in meaningful interactions and unlock potential across diverse applications.
ByteDance Seed distinguishes itself as a pivotal force in the rapidly evolving landscape of agentic AI systems, dedicating substantial resources to both their creation and rigorous evaluation. The organization doesn’t simply build these advanced agents-systems capable of autonomous action and decision-making-but also prioritizes comprehensive testing methodologies to assess performance, safety, and reliability. This commitment extends beyond isolated benchmarks; ByteDance Seed focuses on real-world applications and scenarios, pushing the boundaries of what’s possible with large language model agents. Through iterative development and data-driven insights, the organization actively refines agentic capabilities, contributing significantly to the advancement of artificial intelligence and its potential to address complex challenges. This proactive approach positions ByteDance Seed as a key innovator shaping the future of autonomous systems and intelligent interaction.
The synergistic convergence of deep learning and natural language processing is extending the reach of artificial intelligence into domains long considered the exclusive province of human cognition. Previously intractable challenges – nuanced content creation, complex reasoning, and adaptive decision-making in unstructured environments – are now yielding to these combined technologies. This progress isn’t merely incremental; it represents a qualitative shift, enabling the development of systems capable of not just responding to information, but actively engaging with it, learning from it, and applying that learning to novel situations. Consequently, applications ranging from personalized education and advanced scientific discovery to sophisticated customer service and autonomous robotics are rapidly becoming increasingly viable, signaling a future where AI operates with a degree of autonomy and intelligence previously confined to the realm of science fiction.
The pursuit of predictive accuracy, as detailed in FutureX-Pro, reveals a fundamental truth about all complex systems. While the benchmark focuses on LLM agents and probabilistic forecasting within vertical domains, the underlying principle echoes across disciplines. The inevitability of decay, even in meticulously constructed models, isn’t necessarily due to inherent flaws, but simply the passage of time and the shifting realities they attempt to capture. As Bertrand Russell observed, “The only thing that you can be absolutely sure of is that things will change.” This observation resonates with the paper’s emphasis on data authority and the constant need to recalibrate predictions against evolving circumstances. Stability, in this context, isn’t permanence, but a temporary respite before the next wave of change necessitates adaptation and refinement.
What Lies Ahead?
The pursuit of predictive capacity, as exemplified by FutureX-Pro, inevitably encounters the limitations inherent in all complex systems. The benchmark’s emphasis on vertical domains is a necessary acknowledgment that generalized intelligence quickly dissipates when confronted with the specific gravity of real-world application. Uptime, in this context, is not a sustained state but a rare phase of temporal harmony before inevitable decay. The challenge isn’t merely building agents that can predict, but discerning when their predictions are likely to be useful, given the constant influx of novel, and often misleading, information.
Future work must address the insidious problem of data contamination – the inescapable fact that the past, as represented in training datasets, is already a distorted reflection of events. The benchmark implicitly accepts this, but future iterations should actively quantify the degree to which predictions are simply echoes of prior outcomes. More profoundly, research needs to shift from seeking perfect forecasts to understanding the rate of predictive decay. Technical debt, like erosion, is inevitable; the art lies in managing its consequences, not preventing its accumulation.
Ultimately, the value of probabilistic forecasting isn’t in its accuracy, but in its honesty. A system that reliably assigns low confidence to uncertain events is arguably more valuable than one that confidently asserts falsehoods. The focus should be less on extending the predictive horizon and more on building systems that gracefully acknowledge the limits of foresight. The future, after all, is not something to be known, but something to be navigated.
Original article: https://arxiv.org/pdf/2601.12259.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- What is Omoggle? The AI face-rating platform taking over Twitch
- Man pulls car with his manhood while on fire to raise awareness for prostate cancer
- Wartales Curse of Rigel DLC Guide – Best Tips, POIs & More
- Apple TV’s Imperfect Women Becomes No. 1 Most-Watched Show Globally
- Audible opens first ‘bookless bookstore’ in New York
- 10 Adorable Quotes from Diana in Pragmata
- Netflix’s Remake Of R-Rated Denzel Washington Classic Carries On A Rotten Tomatoes Trend
- Outer Range: The Underrated Western Sci-Fi Series That’s Aging Well
- Steam Drops 24 Free Downloads In Limited-Time Giveaway
2026-01-22 06:32