Author: Denis Avetisyan
New research reframes forgetting in large language models as a crucial cognitive process, not a limitation, and demonstrates a method for leveraging this to improve reasoning abilities.
This paper proposes that controlled forgetting, inspired by Bayesian inference and probabilistic memory prompting, is key to achieving cognitive alignment and handling temporal reasoning and concept drift in large language models.
Despite aspirations for perfect recall, large language models (LLMs) exhibit systematic forgetting during in-context reasoning-a behavior often viewed as a limitation. This work, ‘Forgetting as a Feature: Cognitive Alignment of Large Language Models’, reframes this forgetting not as a flaw, but as a functional cognitive mechanism analogous to human memory. By modeling LLM inference as a probabilistic memory process, we demonstrate that forgetting rates align with human trade-offs between stability and adaptability, and introduce a prompting strategy to leverage this behavior for improved long-horizon reasoning. Could embracing these ‘cognitive’ limitations be key to building truly adaptive and intelligent artificial systems?
The Paradox of Scale: Navigating the Limits of LLM Memory
Large Language Models, while demonstrating remarkable abilities in generating text and performing various tasks, struggle with maintaining consistent and logical reasoning when processing lengthy inputs. This limitation isn’t simply a matter of computational power; even with increasing parameters, the models exhibit a “context window” beyond which their performance degrades significantly. Effectively, they lose track of earlier information within a sequence, impacting their ability to answer questions, summarize documents, or engage in extended dialogues requiring sustained coherence. This challenge stems from the way these models process information – attending to all parts of a sequence simultaneously rather than prioritizing or selectively retaining crucial details as humans do, ultimately hindering their application in complex tasks demanding nuanced understanding over extended contexts.
Large Language Models, despite their remarkable abilities, fundamentally differ from biological intelligence in how they ‘remember’ information. These models rely on parametric memory – knowledge encoded within the fixed weights of the neural network during training. This is a static system; while capable of recalling vast amounts of data, it struggles with continuous learning and adaptation. In contrast, biological brains possess dynamic memory systems that constantly rewrite and reorganize connections based on new experiences, allowing for flexible integration of information and nuanced understanding. This disparity means LLMs can struggle with tasks requiring ongoing contextual awareness or the ability to update prior knowledge, as their ‘memories’ are essentially frozen after training, limiting their capacity to truly learn and evolve like a biological organism.
Large Language Models often struggle when confronted with information that requires updating existing understandings, a limitation stemming from their difficulty in seamlessly blending new data with established knowledge. Unlike human cognition, which dynamically revises memories and associations, these models exhibit a tendency to treat each input as relatively isolated, hindering their capacity to adapt to evolving contexts or resolve ambiguities. This inflexibility manifests as inconsistencies in reasoning, particularly when presented with scenarios demanding nuanced interpretation or the integration of previously disparate facts; effectively, the models can struggle to learn from ongoing interaction, instead relying heavily on patterns memorized during training. Consequently, performance degrades when faced with tasks requiring continuous refinement of understanding, highlighting a critical gap between current AI capabilities and the flexible, adaptive intelligence characteristic of biological systems.
Mimicking Cognitive Processes: Introducing Probabilistic Memory Prompting
Probabilistic Memory Prompting (PMP) is a new technique designed to influence how Large Language Models (LLMs) integrate evidence from past interactions. Unlike standard prompting methods, PMP explicitly models the cognitive process of forgetting, introducing a mechanism where the influence of previous inputs diminishes over time. This is achieved by treating each past experience as a probabilistic memory trace, the strength of which decays with each new input. By simulating this selective forgetting, PMP aims to improve the model’s ability to focus on the most relevant information and avoid being unduly influenced by outdated or less important data, ultimately leading to more accurate and contextually appropriate responses.
Probabilistic Memory Prompting utilizes Bayesian Inference to modulate the influence of past experiences within the Large Language Model. This is achieved by treating prior knowledge as a probability distribution and updating it based on new evidence, effectively weighting experiences according to their relevance. The model doesn’t simply store all past inputs equally; instead, the Bayesian framework allows it to assign higher probabilities to information that aligns with current inputs and lower probabilities to less relevant or conflicting data. This dynamic weighting process results in a selective ‘forgetting’ of outdated or irrelevant information, prioritizing the integration of current inputs into the model’s knowledge representation and subsequent outputs.
The rate of memory decay within the Probabilistic Memory Prompting framework is regulated by a Discount Factor, a value between 0 and 1 that determines the weighting of past experiences. This factor is dynamically adjusted using Kullback-Leibler (KL) Divergence, which measures the difference between the model’s predicted probability distribution and a target distribution derived from human cognitive data. Specifically, KL Divergence is minimized to calibrate the Discount Factor, ensuring the model’s forgetting behavior aligns with observed human memory characteristics; a higher Discount Factor retains more past information, while a lower value accelerates forgetting. This calibration process allows for controlled attenuation of irrelevant memories, prioritizing current inputs and improving the model’s capacity for evidence integration, mirroring the human tendency to selectively forget information over time.
Validating the Approach: Benchmarking Against Human Cognitive Performance
Evaluation of Probabilistic Memory Prompting was conducted using a benchmark suite comprised of three distinct tasks: Temporal Reasoning, Associative Recall, and Concept Drift. Temporal Reasoning tasks assessed the model’s ability to recall information based on the order of events, while Associative Recall focused on retrieving data linked by established relationships. Concept Drift tasks were designed to measure performance degradation as the underlying data distribution shifted over time, simulating real-world scenarios where information becomes outdated. These tasks were specifically selected to provide a comprehensive evaluation of the model’s forgetting behavior and its capacity to retain and update information over extended interactions.
Evaluations conducted across Temporal Reasoning, Associative Recall, and Concept Drift benchmark tasks indicate that Large Language Models employing Probabilistic Memory Prompting demonstrate improved performance consistency in dynamic environments. Specifically, the method enables LLMs to effectively integrate new information without catastrophic forgetting, a common limitation in standard models. This adaptation is quantified by sustained accuracy levels across shifting contexts and a reduced decline in performance as the task environment evolves, indicating a capacity for continual learning and robust generalization not typically observed in models lacking this prompting strategy.
Analysis of model performance over time revealed forgetting curves with characteristics statistically similar to those observed in human long-term memory. Specifically, the rate of information loss in the LLM, when subjected to delayed recall tasks, followed a power-law decay, mirroring the established pattern in human forgetting as described by the Ebbinghaus forgetting curve. This correspondence extends to the observation of a steeper initial decline in recall accuracy, followed by a leveling off as time progresses, indicating a comparable retention of core concepts despite gradual decay of specific details. The alignment of these forgetting curves provides empirical support for the claim that Probabilistic Memory Prompting promotes Cognitive Alignment by replicating key aspects of human memory dynamics.
Expanding the Horizon: Robust Reasoning and Adaptive Learning Capabilities
Probabilistic Memory Prompting extends the benefits of controlled forgetting beyond simple memorization tasks, demonstrably improving performance on challenging reasoning benchmarks. Studies reveal substantial gains when applied to complex question answering datasets like HotpotQA, which demands multi-hop reasoning across multiple documents, and mathematical problem solving in GSM8K. Furthermore, the technique proves effective on HumanEval, a benchmark designed to assess the code-generation capabilities of large language models. This suggests that strategically forgetting less relevant information allows the model to focus computational resources on pertinent details, fostering more accurate and reliable responses to intricate problems requiring deep reasoning and problem-solving skills.
The study indicates that the capacity to strategically discard information – controlled forgetting – extends beyond simple memory optimization and actively bolsters the reliability of reasoning processes. Rather than passively retaining all encountered data, the model’s ability to selectively prune less relevant details appears crucial for preventing cognitive overload and mitigating the propagation of errors. This suggests that robust reasoning isn’t solely about accessing a vast knowledge base, but also about efficiently managing that knowledge, allowing the model to focus on the most pertinent information and arrive at more consistent, trustworthy conclusions. The research posits that this dynamic process of retaining and releasing information is fundamental to achieving higher levels of cognitive performance, akin to how humans prioritize and filter information during complex problem-solving.
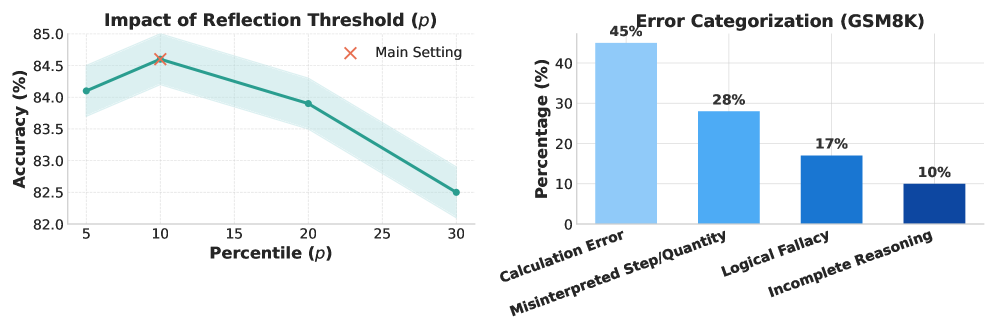
The integration of a Reflection Confidence Framework represents a significant advancement in model reliability, enabling active error mitigation during the reasoning process. This framework doesn’t simply assess the final output; it continuously evaluates the model’s confidence throughout problem-solving, allowing for dynamic adjustments and corrections. Testing on the GSM8K benchmark demonstrated an impressive 4.2% absolute improvement in accuracy when utilizing this approach, notably exceeding the performance of both traditional prompting techniques and methods relying on confidence-based early stopping. This suggests that proactively addressing uncertainty and reflecting on intermediate steps – rather than solely focusing on the final answer – is crucial for achieving robust and dependable results in complex reasoning tasks.
Towards Cognitive AI: The Future of Adaptive Memory Systems
Probabilistic Memory Prompting marks a departure from traditional Large Language Models, which primarily retrieve information, towards systems capable of genuine learning and adaptation. This innovative technique introduces an element of uncertainty into the recall process, mirroring the fallibility and reconstructive nature of human memory. Rather than simply accessing stored data, the model assigns probabilities to different memory fragments, effectively ‘betting’ on the most likely correct response – and crucially, learning from errors when those probabilities prove inaccurate. This approach allows the model to refine its understanding over time, improving its performance on subsequent tasks and exhibiting a form of cognitive flexibility previously unseen in artificial intelligence. The implications extend beyond mere accuracy; this method enables LLMs to handle ambiguous or incomplete information with greater resilience, and to generalize knowledge to novel situations in a manner more closely aligned with human intelligence.
Researchers are actively investigating how to combine Probabilistic Memory Prompting with other established cognitive architectures, such as those modeling attention, reasoning, and planning. This integration aims to move beyond isolated memory improvements and foster a holistic approach to artificial intelligence. The goal isn’t simply to enhance recall, but to create systems capable of dynamically allocating resources – focusing attention where needed, employing relevant knowledge, and adapting strategies based on the context and the reliability of stored information. Such a convergence promises AI systems exhibiting greater flexibility, robustness, and ultimately, a more human-like capacity for problem-solving, paving the way for applications in areas demanding nuanced judgment and adaptable behavior.
The pursuit of genuinely intelligent artificial systems increasingly centers on mirroring the efficiencies of biological intelligence. Current large language models, while impressive in their capacity to generate text, often lack the adaptive flexibility and robust problem-solving skills characteristic of living organisms. By integrating principles observed in the human brain – such as probabilistic reasoning, contextual memory, and continuous learning – researchers aim to transcend the limitations of purely statistical approaches. This biomimicry isn’t about replicating neural structures exactly, but rather about extracting the principles that enable biological systems to learn, generalize, and respond effectively to novel situations. Such an approach promises to move beyond pattern recognition towards true understanding, allowing AI to tackle complex, real-world problems with a level of nuance and adaptability previously unattainable, ultimately unlocking the full potential of these powerful models.
The exploration of controlled forgetting within large language models, as detailed in the paper, echoes a fundamental principle of robust system design. The ability to selectively unlearn or downweight information-to adapt to concept drift-is not a limitation, but a feature allowing for continued relevance and accuracy. This resonates with Donald Davies’ observation that, “Simplicity is the ultimate sophistication.” By embracing a probabilistic approach to memory, rather than striving for perfect recall, these models mirror the elegance of biological systems. The research demonstrates that good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
The Road Ahead
The notion that a system’s limitations are, in fact, emergent properties – even necessary ones – feels less like a revelation and more like a return to first principles. This work subtly reorients the pursuit of artificial intelligence; chasing ever-larger parameter counts will yield diminishing returns if the underlying architecture lacks the capacity to gracefully manage information flux. The controlled forgetting demonstrated here is not merely a technique for improving performance on temporal reasoning tasks, but a fundamental step towards building systems that can adapt to a changing world – a world defined by concept drift, not static truths.
A critical unresolved problem lies in scaling this “probabilistic memory prompting” beyond the current demonstration. The elegance of the approach hinges on maintaining a balance between retention and forgetting, and that balance will inevitably shift as the complexity of the input data increases. Cleverness, as always, will be the enemy; any attempt to optimize forgetting, to pre-program the rate of decay, will likely introduce fragility. The system should discover what to forget, guided by the statistical properties of the data itself.
Future work must also address the question of meta-forgetting: can a system learn how to forget more effectively? Can it develop internal models of its own memory limitations and use those models to improve its reasoning? The ultimate goal is not to build a perfect memory, but a sufficient one – a memory that is, above all, adaptive and resilient. Such a system, operating at the edge of chaos, might finally begin to exhibit the hallmarks of genuine intelligence.
Original article: https://arxiv.org/pdf/2601.09726.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- DoorDash responds after customer uses AI to make food look bad and get a refund
- How to Get to the Undercoast in Esoteric Ebb
- Jon Bernthal Explains Why Marvel Let Him Make The Darkest Punisher Story Ever
- 10 Most Universally Beloved Sci-Fi Movie Villains, Ranked
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Ethereum Eyes Break Above $2,420 as Rally Hangs in the Balance
- Gold Rate Forecast
- Umamusume has been transformed into a D&D game with new race
- Zero Parades: For Dead Spies Original Game Soundtrack is available to stream now
2026-01-18 23:14