Author: Denis Avetisyan
A new approach harnesses the power of artificial intelligence to accurately identify and analyze roadside infrastructure, paving the way for proactive maintenance and improved urban planning.

This review details a framework utilizing large vision-language models, retrieval-augmented generation, and schema-guided reasoning for comprehensive roadside infrastructure perception.
While smart city initiatives increasingly rely on automated infrastructure monitoring, general-purpose models often lack the precision needed for detailed roadside asset analysis. This work, ‘Unleashing the Capabilities of Large Vision-Language Models for Intelligent Perception of Roadside Infrastructure’, introduces a domain-adapted framework that transforms large vision-language models into specialized agents capable of accurately detecting and reasoning about complex infrastructure attributes. By integrating efficient fine-tuning with a knowledge-grounded retrieval mechanism, our approach achieves state-of-the-art performance on a new, comprehensive dataset. Could this framework pave the way for more proactive and cost-effective urban infrastructure management?
The Inevitable Complexity of Roadside Perception
Conventional object detection systems face significant hurdles when applied to roadside environments due to the inherent diversity and intricacy of the infrastructure. Roadside objects – traffic signs, lane markings, guardrails, and even vegetation – exhibit substantial variation in appearance based on factors like lighting, weather, viewpoint, and degree of occlusion. This variability extends to the objects themselves; a stop sign may be new and brightly colored, or faded and partially obscured by foliage. Furthermore, the complexity arises from the sheer number of potential objects within a single visual frame, often overlapping or appearing in unpredictable arrangements. These challenges frequently lead to inaccurate detections, false positives, and ultimately, a compromised ability for autonomous systems to reliably interpret their surroundings and navigate safely.
Current approaches to roadside perception frequently rely on meticulously labeled datasets – a significant bottleneck in real-world application. These systems, while achieving high accuracy on familiar objects and environments within the training data, exhibit a pronounced fragility when confronted with unforeseen circumstances or slight variations in attributes. A traffic sign obscured by foliage, a road marking faded by weather, or even a novel type of construction barrier can easily confound these algorithms, leading to perception failures. This limitation stems from the fact that most methods learn to recognize specific instances rather than underlying characteristics, hindering their ability to generalize to the infinite diversity of roadside environments and ultimately demanding continuous and costly data re-labeling efforts for even minor changes.
The reliable operation of autonomous vehicles and the advancement of intelligent transportation systems fundamentally depend on accurate roadside perception. These systems require a detailed and continuously updated understanding of the surrounding environment – not just identifying objects like pedestrians and vehicles, but also interpreting lane markings, traffic signals, and even temporary construction zones. Current limitations in perceiving these dynamic elements necessitate solutions that move beyond static recognition; robust algorithms must adapt to varying lighting conditions, weather patterns, and the inherent unpredictability of roadside infrastructure. Consequently, research focuses on developing adaptable perception systems capable of generalizing from limited data and maintaining safety and efficiency in real-world driving scenarios, ultimately paving the way for truly driverless technology and smarter roadways.

Vision-Language Models: A Step Towards Contextual Understanding
Vision-Language Models (VLMs) achieve multimodal understanding by integrating computer vision techniques with natural language processing. These models typically employ architectures that process visual input, such as images or video frames, using convolutional neural networks (CNNs) to extract visual features. Simultaneously, textual data is processed using transformer networks to generate contextual embeddings. These embeddings from both modalities are then fused, allowing the model to reason about the content of an image in relation to descriptive language. This combined processing enables VLMs to not only identify what objects are present in a scene but also to interpret how those objects are perceived – their attributes, relationships, and the overall context of the visual information.
Qwen-VL and similar vision-language models demonstrate advanced scene understanding capabilities by generating descriptions that extend beyond simple object categorization. These models can identify and articulate detailed attributes of detected objects, including color, material, spatial relationships, and contextual characteristics. For example, instead of simply identifying a “chair,” Qwen-VL can specify “a red, wooden chair positioned next to a glass table.” This granular level of description is achieved through the model’s training on large datasets of image-text pairs, enabling it to associate visual features with specific descriptive terms and generate comprehensive, structured scene representations suitable for applications requiring precise environmental understanding.
LoRA, or Low-Rank Adaptation, is a parameter-efficient fine-tuning technique for Vision-Language Models (VLMs) that significantly reduces computational cost and storage requirements. Instead of updating all model parameters during task-specific training, LoRA introduces trainable low-rank matrices that are added to the existing weights of the VLM. This approach drastically reduces the number of trainable parameters – often by over 90% – while achieving performance comparable to full fine-tuning. The resulting LoRA modules are small and can be easily swapped to adapt a single base VLM to multiple tasks without the need to duplicate the entire model, facilitating efficient task switching and deployment.
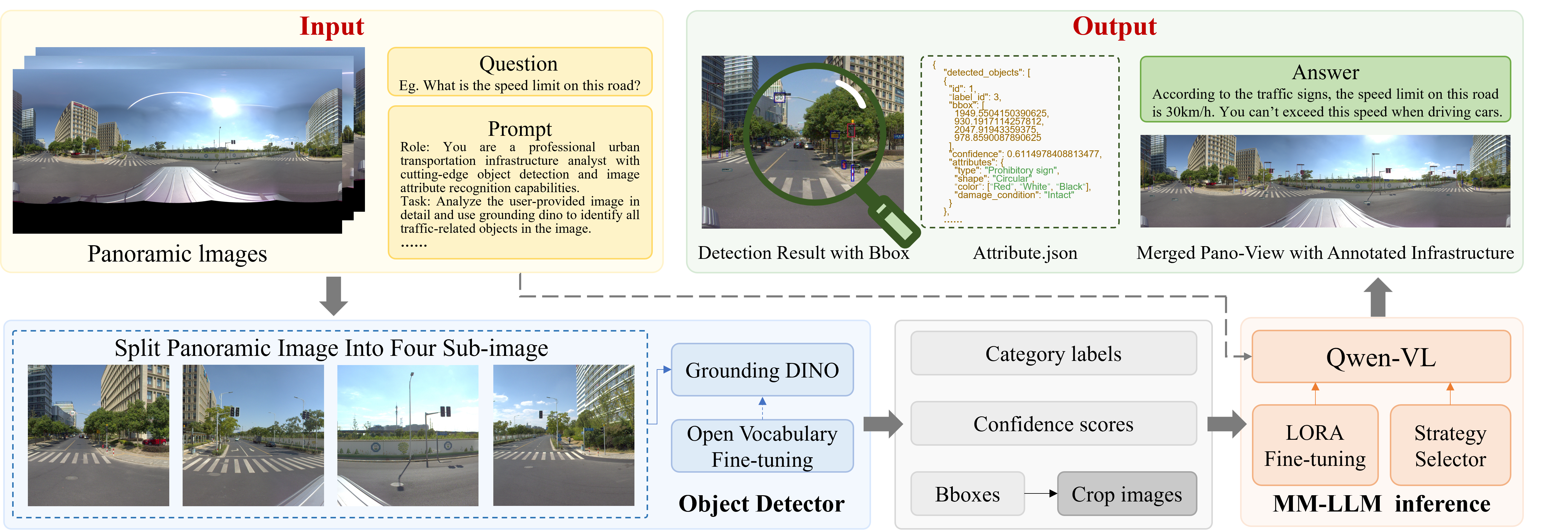
Data and Knowledge: The Foundation of Robust Perception
Training Visual Language Models (VLMs), such as Qwen-VL, on extensive roadside datasets is fundamental to developing robust feature representations. These datasets provide the necessary scale and diversity for the VLM to learn discriminative features relevant to infrastructure components, traffic signals, and road markings. The process involves exposing the model to a vast number of images depicting various roadside elements under diverse conditions – including variations in lighting, weather, and occlusion. This large-scale training enables the VLM to generalize effectively to unseen data and reliably identify and categorize roadside objects, ultimately improving the accuracy and consistency of automated infrastructure monitoring systems.
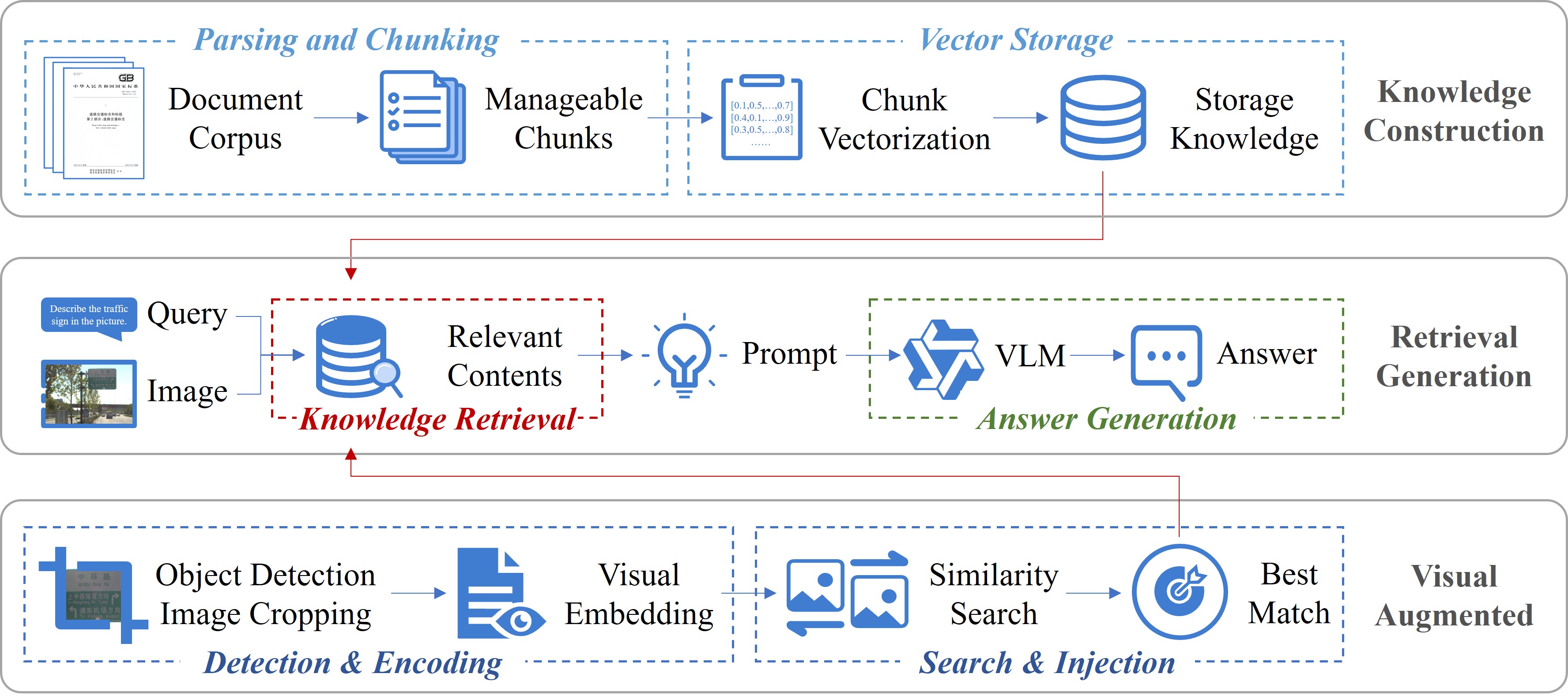
Retrieval-Augmented Generation (RAG) extends the capabilities of Vision-Language Models (VLMs) by enabling access to and incorporation of information from external Textual Knowledge Bases. This process involves retrieving relevant textual data based on the visual input, and then using this retrieved knowledge to augment the VLM’s reasoning and generation processes. By combining visual perception with external knowledge, RAG allows the VLM to move beyond its pre-trained knowledge and address scenarios requiring specific or up-to-date information, improving performance in tasks such as infrastructure monitoring and attribute recognition where adherence to standards, like GB 5768.2-2022, is critical.
Retrieval-Augmented Generation (RAG) enhances the accuracy of Visual Language Models (VLMs) by supplementing visual input with relevant information retrieved from external knowledge sources. This process utilizes both visual exemplars – example images with associated data – and textual data, such as the GB 5768.2-2022 standard for traffic sign recognition. By accessing and incorporating this external knowledge, the VLM can resolve ambiguities present in visual data and improve performance on tasks requiring specific, codified information; for instance, correctly identifying a traffic sign based on the precise wording of the governing standard rather than solely relying on its visual appearance. This combination of visual and textual input significantly improves the model’s ability to generalize and provide accurate structured perception in complex scenarios.
Open-Set Continued Pre-training addresses the challenge of incrementally expanding a Visual Language Model’s (VLM) attribute recognition capabilities without causing catastrophic forgetting of previously learned attributes. This technique allows Grounding DINO to be exposed to new attribute classes during training, effectively increasing its vocabulary and recognition scope. Unlike traditional fine-tuning, which can overwrite existing knowledge, Open-Set Continued Pre-training employs strategies such as regularization and replay buffers to preserve performance on known attributes while simultaneously learning to identify novel ones. The process involves presenting the model with a mix of previously seen and new attributes, enabling it to generalize its feature representations and maintain accuracy across a dynamic set of classes without requiring retraining on the entire dataset.
Evaluations performed on the Shanghai dataset demonstrate the framework achieves 95.5% attribute accuracy, representing a substantial advancement in structured perception capabilities for automated infrastructure monitoring applications. This metric indicates the system’s ability to correctly identify and categorize a high percentage of relevant attributes within complex visual scenes. The achieved accuracy level suggests a robust performance in tasks such as identifying specific infrastructure components, assessing their condition, and extracting relevant data for maintenance and management purposes. This performance is a key indicator of the system’s readiness for real-world deployment in automated infrastructure inspection and analysis workflows.
Validation, Performance, and the Inevitable Next Steps
Rigorous quantitative evaluation served as a cornerstone in validating the efficacy of this approach, employing established metrics such as Mean Average Precision (mAP) and Intersection over Union (IoU). These metrics provide a standardized and objective assessment of the system’s ability to accurately identify and localize objects within complex visual scenes. Specifically, mAP quantifies the precision of object detection across different recall levels, while IoU measures the overlap between predicted bounding boxes and ground truth annotations – higher scores in both indicate improved performance. The consistent achievement of strong results across these key indicators confirms the model’s capability to reliably perform object detection tasks, providing a solid foundation for further development and real-world applications.
Evaluations reveal the system’s substantial capability in roadside scene understanding, achieving a Mean Average Precision (mAP) of 83.1 and a Mean Average Recall (mAR) of 60.6 on the specialized roadside object detection task. These metrics indicate a high degree of accuracy in identifying relevant objects within complex roadside environments, suggesting the model effectively distinguishes between various elements such as traffic signs, pedestrians, and vehicles. The strong performance highlights the system’s potential for applications requiring detailed environmental awareness, and underscores the effectiveness of the chosen approach in addressing the unique challenges posed by roadside scenarios.
The model’s achievement of a 47.6 mean Average Precision (mAP) score on the challenging COCO dataset signifies a notable level of robustness beyond its specialized roadside object detection capabilities. This benchmark, established through evaluation on a diverse range of common objects, indicates the system’s capacity to generalize its learned features and perform accurately even with objects and scenes outside of its primary training domain. Such adaptability is crucial for real-world applications, as autonomous systems often encounter varied and unpredictable environments, and demonstrates the potential for broader deployment beyond specific, narrowly defined tasks. The COCO mAP score thus serves as strong evidence of the model’s overall perceptual intelligence and its ability to reliably identify objects in complex visual scenarios.
The architecture leverages a Retrieval-Augmented Generation approach, but crucially extends it to incorporate both visual and textual information streams. Rather than relying solely on text-based knowledge retrieval, the system analyzes both the textual query and relevant images captured from the roadside environment. This dual-modality allows for a more comprehensive understanding of the context, enabling the model to retrieve more pertinent information and generate more accurate responses. By effectively fusing visual cues – such as road signs, traffic signals, and pedestrian locations – with textual descriptions, the system significantly enhances its ability to interpret complex scenarios and improve overall performance in tasks requiring contextual awareness and detailed environmental understanding.
Continued development centers on enriching the system’s knowledge repository with a broader range of scenarios and contextual information, aiming to enhance its adaptability to previously unseen environments and challenging conditions. Researchers are also prioritizing improved generalization capabilities, allowing the model to perform reliably across varied geographical locations, weather patterns, and traffic densities. A crucial next step involves transitioning from research prototypes to real-time implementation, exploring methods for efficient processing and integration into the complex systems required for autonomous vehicle navigation, ultimately paving the way for safer and more reliable self-driving technologies.

The pursuit of elegant solutions for roadside infrastructure perception feels…familiar. This paper details a retrieval-augmented generation framework, attempting to bridge the gap between vision and language, a problem that’s haunted engineers for decades. It’s a clever application of large vision-language models, certainly, but one suspects the first production deployment will reveal edge cases the researchers hadn’t conceived of. As Geoffrey Hinton once observed, “I’m suspicious of things that look too good.” The framework’s reliance on accurate attribute recognition – a core concept of this work – will undoubtedly be tested by real-world ambiguity. It’s not a matter of if something breaks, but when, and likely in the most inconvenient way possible.
What’s Next?
The elegant coupling of vision-language models with retrieval mechanisms feels…predictable. It addresses the immediate need for attribute recognition in roadside infrastructure, certainly, but it also highlights a familiar pattern: chasing open-vocabulary detection with ever-larger models. The current framework will inevitably encounter edge cases-poor lighting, unusual obstructions, the delightful chaos of real-world damage-and those will demand further scaling, further refinement. It’s not a problem to solve, merely a cost of operation.
The schema-guided reasoning is a useful constraint, but constraints always become bottlenecks. The system performs well within the defined schema, but the world rarely adheres to pre-defined categories. Future iterations will likely require a more fluid, adaptable schema-or, more realistically, a tolerance for ambiguity. The pursuit of perfect categorization feels increasingly…quixotic.
The true test won’t be accuracy on curated datasets. It will be the system’s resilience in the face of prolonged deployment, the slow accumulation of technical debt as infrastructure ages, and the constant need to patch against unforeseen interactions. This isn’t a step towards intelligent perception, it’s a meticulously crafted illusion of competence. And illusions, as anyone who’s managed production knows, require constant maintenance.
Original article: https://arxiv.org/pdf/2601.10551.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- 8 Movie Trilogies That Are More Rewatchable Than The Lord of the Rings
- 10 Most Universally Beloved Sci-Fi Movie Villains, Ranked
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Jon Bernthal Explains Why Marvel Let Him Make The Darkest Punisher Story Ever
- Prime Video Has Officially Found The Next Game Of Thrones
- YouTuber arrested after viral AI bodycam videos spark real police complaints
2026-01-18 18:26