Author: Denis Avetisyan
As large language models become increasingly integrated into critical applications, ensuring factual accuracy and mitigating the risk of fabricated information is paramount.
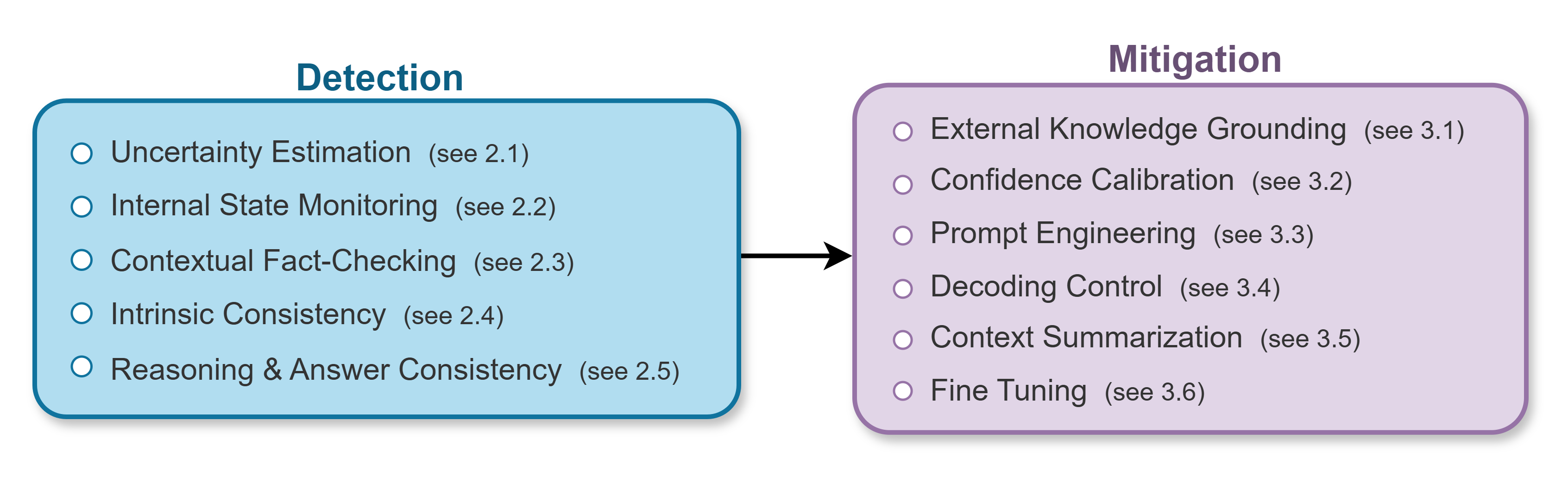
This review proposes a tiered framework for systematically detecting, analyzing, and reducing hallucinations in large language models through root cause analysis and continuous improvement.
Despite the transformative potential of large language models in high-stakes domains, their propensity to generate factually incorrect or unsupported content-known as hallucination-presents a significant reliability challenge. This paper, ‘Hallucination Detection and Mitigation in Large Language Models’, introduces a comprehensive framework for managing these hallucinations through root cause analysis and a continuous improvement cycle. By categorizing hallucination sources and integrating multi-faceted detection with stratified mitigation strategies, we demonstrate a tiered architecture capable of progressively enhancing trustworthiness. Can this systematic approach unlock the full potential of generative AI in regulated environments demanding consistently reliable outputs?
Deconstructing the Oracle: Unveiling the Illusion of Language Models
Large language models, while exhibiting an impressive ability to generate human-quality text, are susceptible to producing outputs disconnected from factual accuracy – a phenomenon increasingly referred to as ‘hallucination’. This isn’t a matter of deliberate deception, but rather a consequence of how these models learn; they excel at identifying patterns and relationships within vast datasets, and then statistically predicting the most likely continuation of a given text. However, this process doesn’t inherently involve verifying the truthfulness of the generated content. Consequently, a model can confidently articulate plausible-sounding statements that are entirely fabricated or contradict established knowledge. The frequency and subtlety of these hallucinations pose a significant challenge, as they can be difficult for even discerning human readers to detect, potentially leading to the propagation of misinformation and eroding trust in the technology.
The tendency of large language models to “hallucinate” – generating outputs that deviate from established facts or logical coherence – isn’t a simple bug, but a consequence of their foundational design. These models learn by identifying statistical patterns in massive datasets, prioritizing fluency and plausibility over truthfulness. This approach means they excel at producing text that sounds correct, but lack an inherent mechanism to verify its accuracy. Consequently, even highly sophisticated LLMs can confidently present fabricated information, misattribute sources, or construct internally inconsistent narratives. This unreliability poses a significant obstacle to widespread adoption, particularly in contexts where precision is paramount, such as medical diagnosis, legal reasoning, or scientific research, ultimately eroding user trust and hindering the practical utility of these powerful tools.
The successful integration of Large Language Models into critical applications-spanning healthcare, finance, and legal services-hinges decisively on mitigating the challenge of factual inaccuracies. While these models excel at generating human-quality text, their propensity for ‘hallucinations’-fabricating information or presenting falsehoods-directly impedes their deployment in contexts where reliability is paramount. Without substantial improvements in truthfulness and consistency, the potential benefits of LLMs – enhanced efficiency, automated reasoning, and novel insights – remain largely unrealized. Consequently, ongoing research focused on refining model architectures, improving training datasets, and implementing robust verification mechanisms is not merely an academic pursuit, but a fundamental requirement for unlocking the transformative power of these technologies and fostering public trust in their outputs.
Dissecting the Source: Uncovering the Roots of LLM Illusion
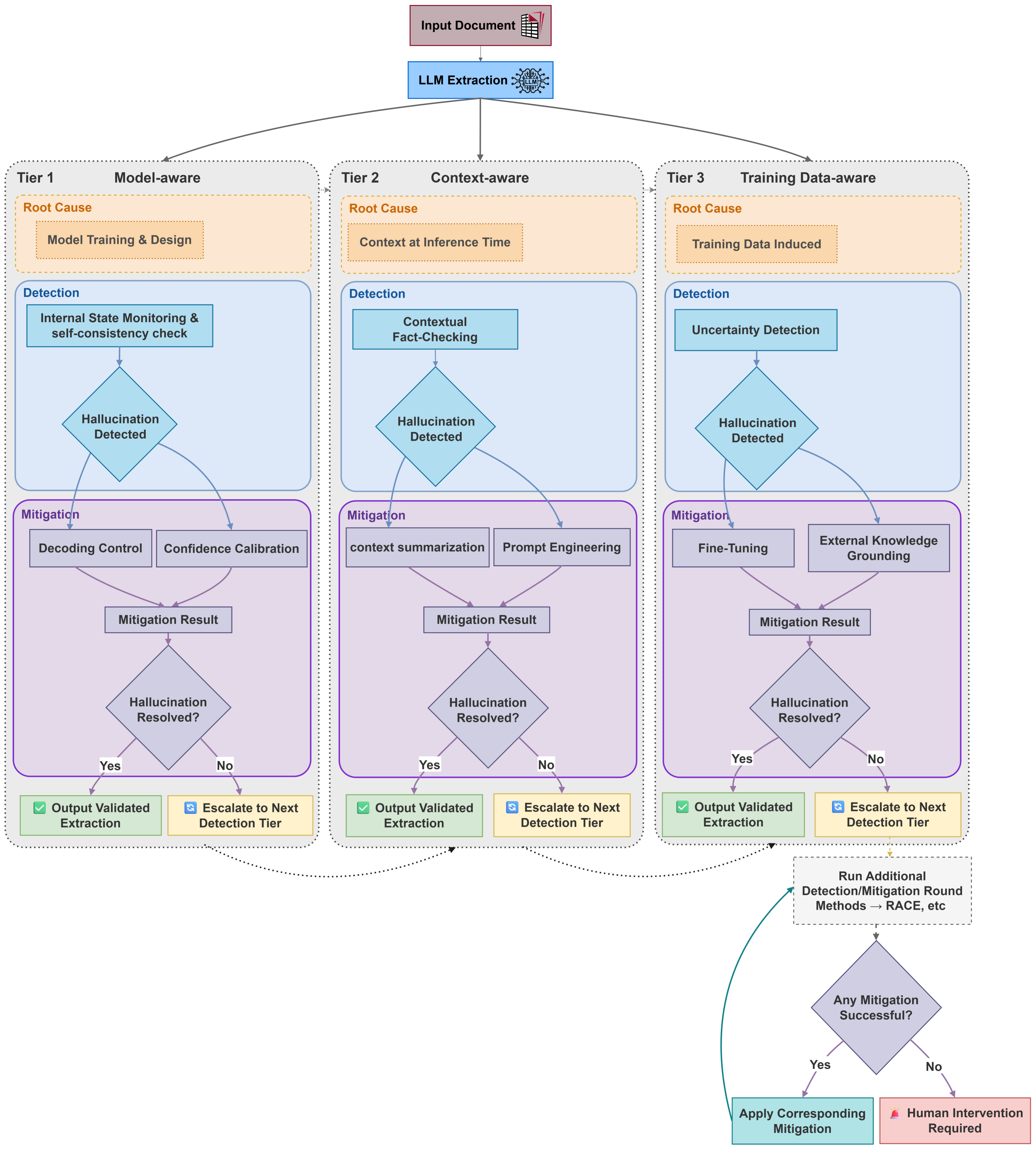
Large Language Model (LLM) hallucinations – the generation of factually incorrect or nonsensical information – are attributable to three core problem areas. Data-Level Issues stem from imperfections within the training corpus, including inherent biases and knowledge gaps that lead to skewed or incomplete representations. Model-Level Issues relate to limitations in the LLM’s architecture or training methodologies, hindering its ability to accurately model complex relationships and perform robust reasoning. Finally, Context-Level Issues arise when the input provided to the model is ambiguous, incomplete, or lacks sufficient detail, compelling the LLM to extrapolate information and potentially generate inaccurate responses.
Data-level issues contributing to LLM hallucinations stem from inherent limitations within the training corpus. These limitations manifest as both biases – systematic errors introduced by imbalanced or prejudiced data representation – and gaps, which represent a lack of information regarding specific topics or relationships. Consequently, the LLM develops a skewed or incomplete knowledge representation, meaning its internal understanding of the world is not fully accurate or comprehensive. This flawed knowledge base then directly contributes to the generation of factually incorrect or nonsensical outputs, as the model relies on this compromised data to formulate responses. The prevalence of biased or incomplete data directly correlates with the frequency and severity of hallucinations.
Model-level issues contributing to LLM hallucinations stem from inherent limitations in the model’s architecture and training methodologies. Specifically, while large language models excel at pattern recognition and statistical correlations within the training data, they often struggle with abstract reasoning, causal inference, and the application of common sense knowledge. This is partially attributable to the finite parameter space of the model, which restricts its ability to fully represent the complexity of real-world relationships. Furthermore, training processes focused on next-token prediction, while effective for generating coherent text, do not explicitly optimize for factual accuracy or logical consistency. Consequently, the model may generate plausible-sounding but ultimately incorrect statements when confronted with novel or ambiguous prompts, demonstrating a disconnect between linguistic fluency and genuine understanding.
Context-level issues contributing to LLM hallucinations stem from deficiencies in the input provided to the model. When a prompt lacks sufficient detail, presents ambiguous phrasing, or omits crucial information, the LLM attempts to infer the missing elements. This inference isn’t based on verified knowledge, but rather on statistical probabilities derived from the training data; therefore, the completed information may be factually incorrect or nonsensical. The severity of this issue is directly correlated to the complexity of the missing context and the model’s inability to reliably request clarification or acknowledge uncertainty when faced with incomplete input.
Shadow Detection: Methods for Exposing LLM Fabrications
Factual Consistency Checks are a critical component of hallucination detection, operating by verifying statements generated by a large language model (LLM) against established external knowledge sources. This process typically involves retrieving relevant information from databases, knowledge graphs, or the web, and then comparing the LLM’s output for factual alignment. Discrepancies identified through this comparison indicate potential hallucinations. Automated methods utilize techniques like question answering and natural language inference to assess consistency, while human evaluation can provide a higher degree of accuracy, particularly for nuanced or complex claims. The effectiveness of Factual Consistency Checks is dependent on the quality and coverage of the external knowledge sources used, as well as the sophistication of the comparison algorithms employed.
Reasoning Validation techniques evaluate the internal consistency and logical flow of a large language model’s (LLM) response generation. The RACE (Reasoning Ability Evaluation) Framework is one such method, designed to assess an LLM’s capacity for multi-step reasoning. RACE operates by presenting the model with questions requiring justification, then analyzing the provided reasoning chain for logical fallacies, unsupported assertions, or inconsistencies between premises and conclusions. Evaluation metrics focus on whether the model correctly identifies relevant information, applies appropriate reasoning rules, and arrives at a logically sound answer, independent of factual correctness. These methods aim to distinguish between responses that appear plausible but are based on flawed reasoning, and those grounded in coherent thought processes, providing a critical layer of hallucination detection beyond simple fact-checking.
Uncertainty Estimation techniques assess the reliability of large language model outputs by quantifying the model’s confidence in its predictions. These methods operate on the principle that a well-calibrated model will assign high probabilities to correct answers and low probabilities to incorrect ones. Techniques include Monte Carlo Dropout, which performs multiple inferences with randomly dropped neurons to generate a distribution of outputs; Deep Ensembles, which train multiple models and use the variance of their predictions as a measure of uncertainty; and methods based on the model’s softmax layer, such as temperature scaling, to calibrate the predicted probabilities. High uncertainty scores flag potentially hallucinated content, prompting further verification or rejection of the output, while low uncertainty indicates a higher degree of confidence in the prediction’s accuracy.
A tiered detection architecture addresses hallucination mitigation through layered verification. At the model level, internal states and attention mechanisms are monitored for anomalies indicative of fabrication. Data-level checks involve validating the source information used by the model, confirming its reliability and identifying potential biases or inaccuracies. Context-level scrutiny examines the prompt and surrounding conversation to ensure the model’s response aligns with the established discourse and doesn’t introduce extraneous or contradictory information. This multi-level approach increases the probability of identifying hallucinations as it doesn’t rely on a single point of failure, offering a more robust defense against inaccurate or misleading outputs.
Rewriting Reality: Strategies for Constraining LLM Fabrication
Prompt engineering focuses on crafting input queries to elicit desired responses from large language models. The effectiveness of a prompt is directly correlated with its clarity, specificity, and the inclusion of relevant contextual information. Ambiguous or overly broad prompts can lead to unpredictable outputs and increased instances of hallucination. Conversely, well-defined prompts that explicitly state the desired format, length, and focus of the response, along with any necessary background details, guide the model towards generating more accurate and reliable text. Techniques include providing examples of desired outputs (few-shot learning), specifying the role the model should assume, and utilizing keywords relevant to the intended topic.
Model fine-tuning involves continuing the training process of a pre-trained large language model (LLM) on a smaller, task-specific dataset. This process adjusts the model’s existing weights to better align with the nuances of the target domain, improving both factual accuracy and reasoning capabilities. The effectiveness of fine-tuning is heavily dependent on the quality and relevance of the curated dataset; datasets must be meticulously prepared, free from errors, and representative of the desired output distribution. Techniques like low-rank adaptation (LoRA) can further optimize the process by reducing the number of trainable parameters, making fine-tuning more efficient and less resource-intensive. Properly executed fine-tuning can significantly reduce the occurrence of hallucinations by reinforcing correct associations and minimizing the model’s reliance on potentially inaccurate pre-training data.
External knowledge grounding addresses the limitations of Large Language Models (LLMs) by supplementing their pre-trained parameters with information retrieved from external sources during inference. This process typically involves retrieving relevant documents or data entries from a knowledge base – such as a vector database, API, or structured database – based on the user’s query. The retrieved information is then incorporated into the prompt or used to condition the model’s output, providing it with access to factual data beyond its training corpus. This allows the LLM to generate responses grounded in verified information, reducing reliance on potentially inaccurate or fabricated content and improving the overall reliability and trustworthiness of its outputs. Retrieval methods include dense vector search, keyword search, and graph traversal, each suited to different data structures and query types.
Temperature scaling and Top-p sampling are post-processing techniques used to refine the probability distribution of a language model’s output. Temperature scaling adjusts the model’s confidence by dividing the logits (raw prediction scores) by a temperature value; higher temperatures increase randomness, while lower temperatures make the model more deterministic. Top-p sampling, also known as nucleus sampling, dynamically selects the smallest set of tokens whose cumulative probability exceeds a probability p, and then redistributes the probability mass among only those tokens. This prevents the model from considering low-probability, potentially nonsensical tokens, thereby reducing the occurrence of hallucinations and improving output coherence. Both techniques aim to calibrate the model’s output without altering the underlying model weights.
The Perpetual Refinement: Towards Trustworthy Language Models
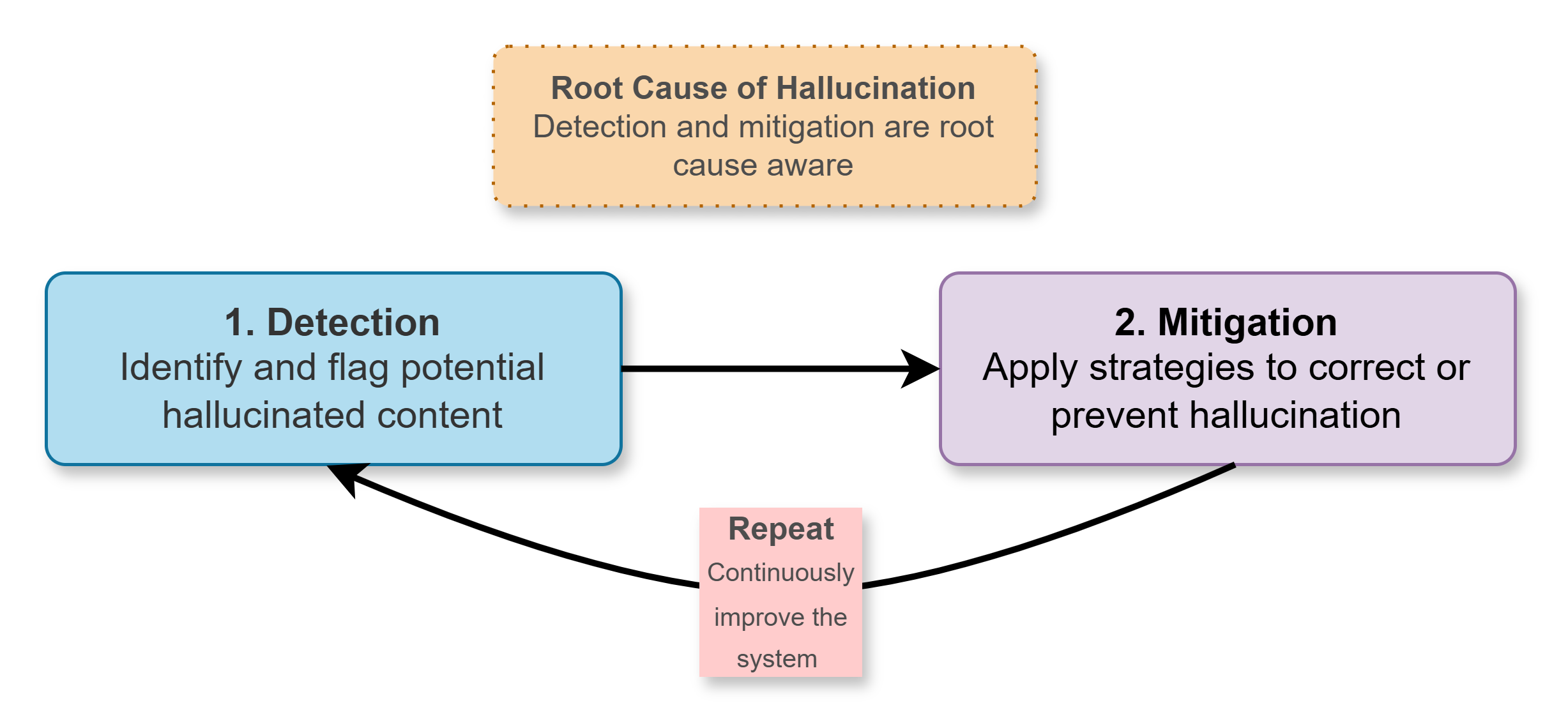
The persistent issue of hallucinations – where large language models generate factually incorrect or nonsensical outputs – necessitates a fundamentally iterative approach to development. Establishing a continuous improvement cycle is paramount, moving beyond one-time training and evaluation towards ongoing refinement. This cycle demands systematic detection of these erroneous outputs, not just through automated metrics, but also via human evaluation and adversarial testing. Once identified, mitigation strategies – ranging from data augmentation and fine-tuning to architectural modifications – can be implemented. Critically, the effectiveness of these strategies must be rigorously validated, and the insights gleaned fed back into the cycle to further refine both the model itself and the processes used to build and assess it. This commitment to continuous learning is not merely about reducing errors; it is about building trust and unlocking the true potential of these powerful technologies.
A robust approach to building reliable large language models necessitates a continuous improvement cycle centered on identifying and correcting inaccuracies. This cycle begins with systematic hallucination detection, employing techniques to pinpoint instances where the model generates factually incorrect or nonsensical outputs. Following detection, targeted mitigation strategies – such as reinforcement learning from human feedback or knowledge retrieval augmentation – are implemented to address the root causes of these errors. Crucially, the effectiveness of each mitigation isn’t assumed, but rigorously validated through evaluation metrics and benchmark datasets. The insights gleaned from this validation then feed back into the model and the refinement of the entire process, creating an iterative loop that progressively enhances the model’s trustworthiness and reduces the occurrence of hallucinations over time.
The pursuit of genuinely reliable large language models hinges on moving beyond one-time fixes and embracing a continuous improvement cycle. This isn’t simply about reducing errors, but establishing a dynamic system where systematic detection of inaccuracies – or hallucinations – informs the implementation of mitigation strategies. Critically, these strategies aren’t deployed in isolation; their effectiveness is rigorously validated, and the resulting data feeds back into further model refinement and process optimization. This iterative loop promises to unlock the full potential of LLMs, transforming them from promising technologies into dependable tools applicable across diverse fields, from scientific discovery and complex data analysis to personalized education and accessible information services. A commitment to continuous improvement isn’t merely a technical necessity; it’s the key to building user trust and realizing the transformative power of these powerful systems.
To bolster the reliability of large language models, ensemble agreement filtering presents a powerful technique wherein multiple independent models address the same prompt. Rather than relying on a single model’s output, this method assesses the degree of consensus among the ensemble; responses exhibiting strong agreement are considered more trustworthy, while divergent answers trigger further scrutiny or rejection. This approach significantly diminishes the impact of individual model errors or ‘hallucinations’, as a single flawed response is less likely to dominate when contrasted with corroborating outputs. By effectively averaging out individual inconsistencies, ensemble filtering doesn’t merely identify potential inaccuracies, but actively builds a more robust and dependable system for generating information.
The pursuit of reliable large language models necessitates a willingness to dissect and understand failure, not simply avoid it. This framework, with its emphasis on root cause analysis and a continuous improvement cycle, embodies that principle. It acknowledges that hallucinations aren’t merely bugs to be patched, but symptoms of deeper systemic issues. As Edsger W. Dijkstra stated, “Testing can be used to show the presence of bugs, but it can never prove their absence.” The tiered architecture proposed isn’t about building a perfect system, but about creating a robust process for identifying and mitigating the inevitable imperfections, turning potential failures into opportunities for refinement and a greater understanding of the model’s internal logic. This aligns with the core idea that managing hallucinations requires a systematic approach, not a superficial fix.
Beyond Truth: The Road Ahead
The presented framework, while a pragmatic step toward managing the inevitable confabulations of large language models, merely illuminates the edges of a far deeper problem. Treating ‘hallucination’ as a bug to be squashed assumes a model should reflect an external reality-a notion worth questioning. The pursuit of ‘truth’ in these systems risks imposing human biases onto entities fundamentally divorced from genuine understanding. Future work must actively probe the utility of untruth – what novel outputs, currently labeled as errors, might reveal about the model’s internal logic, or even unlock unforeseen problem-solving approaches.
A tiered architecture for detection and mitigation is a logical starting point, but it inherently relies on defining ‘ground truth’ – a notoriously fluid concept. The continuous improvement cycle, likewise, presumes a stable target. The real challenge lies in building models that are consistently unreliable in predictable ways, allowing for the development of tools that exploit, rather than suppress, their inherent tendencies. Consider a system designed to creatively misinform – the potential is arguably greater than that of a flawlessly ‘accurate’ one.
Ultimately, the field needs to move beyond simply minimizing errors and begin exploring the very nature of knowledge representation within these systems. The black box is opening, but the contents are less about mimicking human cognition and more about discovering a fundamentally different form of intelligence-one that operates by principles we have yet to fully grasp, and may not even recognize as ‘intelligent’ in the traditional sense.
Original article: https://arxiv.org/pdf/2601.09929.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Jon Bernthal Explains Why Marvel Let Him Make The Darkest Punisher Story Ever
- Olympian Says Heated Rivalry Tugged At His Heartstrings
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Dutton Ranch Review: Paramount+’s New Western Takes All The Best Parts Of Yellowstone & Makes Them Better
- ETH Holders Cash In: Is the Party Over, or Just Getting Started?
- Oh My God, It’s Her?
2026-01-16 07:36