Author: Denis Avetisyan
A new framework leverages artificial intelligence to dynamically optimize resource allocation across distributed cloud environments, boosting performance and reducing waste.
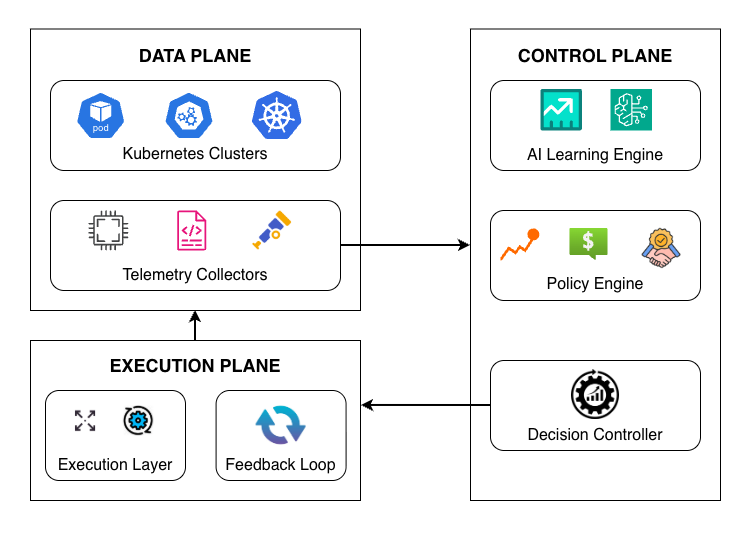
This review details an AI-driven approach to multi-cluster cloud resource optimization, incorporating predictive learning and policy-aware reasoning for improved efficiency and stability.
While multi-cluster cloud deployments offer scalability and resilience, existing resource management struggles to adapt to dynamic workloads efficiently. This paper, ‘AI-Driven Cloud Resource Optimization for Multi-Cluster Environments’, introduces a novel framework leveraging predictive learning and policy-aware decision-making to proactively optimize resource allocation across distributed cloud environments. Results demonstrate significant improvements in resource efficiency, stabilization during workload fluctuations, and reduced performance variability compared to conventional reactive approaches. Could intelligent, self-adaptive infrastructure management become the cornerstone of truly scalable and resilient cloud platforms?
The Inevitable Strain on Modern Infrastructure
Contemporary applications, increasingly architected with microservices, present a unique challenge to resource management due to their inherent volatility. Unlike monolithic applications with relatively predictable resource needs, microservices operate as independent, scalable units, experiencing fluctuating demands based on individual feature usage and user activity. This dynamic nature necessitates a departure from static provisioning; applications require the ability to rapidly scale individual services up or down, allocating resources precisely when and where they are needed. The ability to respond to these granular shifts in demand is not merely an optimization-it is a fundamental requirement for maintaining performance, ensuring responsiveness, and ultimately, delivering a seamless user experience in a continuously evolving digital landscape.
Single-cluster autoscaling, a cornerstone of earlier cloud resource management, often proves inadequate when faced with the intricacies of modern, distributed applications. This approach typically focuses on adjusting resources within a single Kubernetes cluster, failing to account for workloads that span multiple clusters or cloud regions. Consequently, it struggles to efficiently handle fluctuating demands across a broader infrastructure, leading to scenarios where some clusters are overprovisioned while others remain constrained. The rigidity of this method hinders the dynamic allocation needed for microservices architectures, where individual components require independent scaling and are geographically distributed for resilience and reduced latency. This inflexibility results in suboptimal resource utilization, increased operational costs, and a diminished capacity to respond swiftly to changing application requirements.
The inefficiencies inherent in traditional resource management directly translate into tangible setbacks for modern applications. When systems over-provision to anticipate peak loads, substantial computing resources remain idle during quieter periods – a clear economic waste. Conversely, under-provisioning manifests as increased latency, frustrating users and potentially impacting critical business functions. This performance degradation isn’t merely a technical issue; it actively stifles an organization’s agility, slowing down development cycles, hindering rapid experimentation, and ultimately diminishing its capacity for innovation. The inability to quickly adapt to changing demands creates a bottleneck, preventing businesses from capitalizing on emerging opportunities and maintaining a competitive edge in dynamic markets.
Orchestrating Resilience Across Distributed Systems
Modern applications increasingly leverage multi-cluster cloud environments to achieve enhanced scalability, resilience, and geographic distribution. Deploying workloads across multiple Kubernetes clusters-potentially spanning different cloud providers or regions-allows applications to dynamically scale beyond the capacity of a single cluster. This distributed architecture improves resilience by providing redundancy; if one cluster experiences an outage, traffic can be automatically routed to healthy clusters. Furthermore, deploying clusters closer to end-users via geographic distribution minimizes latency and improves application performance for a global user base. This approach requires careful consideration of data synchronization, network connectivity, and consistent application deployment strategies across all clusters.
Kubernetes functions as the central orchestration layer for containerized applications deployed across multiple clusters, automating deployment, scaling, and management. However, realizing the benefits of multi-cluster deployments necessitates intelligent resource management capabilities within Kubernetes. This includes features such as pod topology spread constraints, resource quotas enforced at the cluster level, and advanced scheduling algorithms to optimize workload placement based on resource availability, cost, and proximity to users. Without these mechanisms, workloads may be unevenly distributed, leading to resource contention, increased latency, and suboptimal utilization of available infrastructure, negating the advantages of a multi-cluster architecture.
Cross-cluster resource management involves the coordinated scheduling and allocation of compute, storage, and networking resources distributed across multiple Kubernetes clusters, potentially spanning different cloud providers or on-premise infrastructure. This capability moves beyond individual cluster limitations, enabling workloads to dynamically utilize available capacity wherever it exists. Effective cross-cluster management facilitates both horizontal scaling – increasing application capacity by distributing workloads – and disaster recovery/failover scenarios by automatically shifting operations to healthy clusters in the event of an outage. Implementation typically involves a central control plane or federation layer capable of monitoring resource availability across all connected clusters and making informed scheduling decisions based on defined policies and constraints, ultimately optimizing resource utilization and application availability.
Predictive Resource Allocation: Anticipating the Inevitable
AI-driven resource optimization employs machine learning algorithms to forecast future resource requirements within computing clusters. These techniques analyze historical data, including CPU utilization, memory consumption, and network I/O, to build predictive models of application behavior. Based on these predictions, the system proactively allocates resources – such as virtual machines, containers, or processing power – to meet anticipated demand before bottlenecks occur. This contrasts with reactive scaling, which responds to issues after they impact performance. The goal is to maintain optimal resource utilization, minimizing waste and reducing operational costs by preemptively adjusting resource allocation across the cluster based on projected workloads.
Resource optimization systems utilize telemetry data – including CPU usage, memory consumption, network I/O, and disk activity – to build behavioral models of applications. These models are then used to predict future resource demands based on observed patterns and trends. System modeling techniques, such as time-series analysis and regression, are applied to this data to forecast scaling requirements with increased accuracy. By proactively allocating resources – compute, storage, and network capacity – based on these predictions, the system minimizes idle resources and prevents performance bottlenecks, thereby maximizing overall resource utilization efficiency and reducing operational costs. The granularity of telemetry data and the complexity of the system models directly impact the precision of the forecasts and the effectiveness of the optimization process.
Workload prediction, anomaly detection, and reinforcement learning are integrated to establish a self-optimizing resource allocation system. Workload prediction algorithms, trained on historical telemetry, forecast future resource requirements for applications. Anomaly detection identifies deviations from expected behavior, triggering preemptive scaling or resource adjustments. Reinforcement learning then utilizes these observations to refine allocation policies over time, maximizing efficiency and minimizing waste by learning optimal strategies through trial and error; this iterative process allows the system to adapt to changing demands and continuously improve resource utilization without manual intervention.
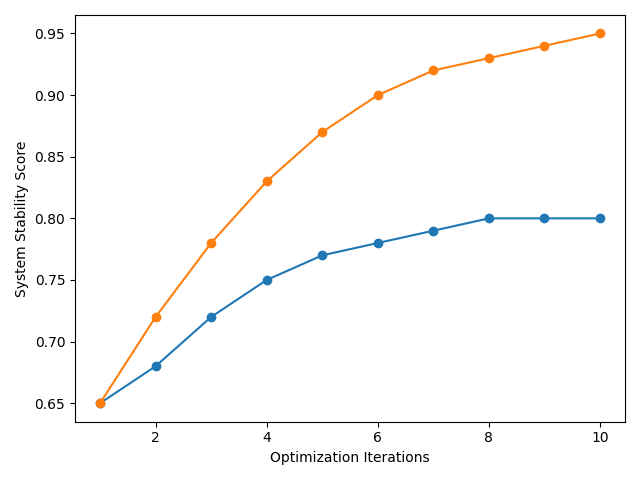
Toward Sustainable Systems: Resilience and Efficiency at Scale
AI-driven resource allocation represents a paradigm shift in cluster management, proactively addressing the challenges of fluctuating workloads and limited resources. This optimization intelligently distributes tasks and computational power across clusters, minimizing the time it takes for a system to respond to requests-reducing response latency. By anticipating demand and strategically positioning resources, the system avoids bottlenecks and ensures a more balanced workload distribution. This not only enhances overall performance but also improves the stability and efficiency of deployments, paving the way for reduced operational costs and a significantly improved user experience.
The system’s performance gains are significantly bolstered by implementing closed-loop control and localized execution strategies. This approach dynamically monitors resource demands within specific clusters and proactively allocates necessary resources to those locations, rather than relying on centralized provisioning. By continuously assessing and adjusting to real-time needs, the system minimizes bottlenecks and ensures optimal resource availability precisely where and when computations are occurring. This localized responsiveness not only accelerates processing speeds but also enhances the overall stability of deployments, as the system can swiftly adapt to fluctuating workloads and prevent cascading failures – a critical benefit for maintaining consistent user experiences and reducing operational expenses.
The newly developed framework demonstrably enhances operational efficiency through optimized resource allocation, achieving a 25% improvement in resource utilization. This isn’t merely about doing more with less; the system also achieves a significantly more balanced workload distribution across computing clusters, preventing bottlenecks and maximizing throughput. Consequently, response latency is reduced compared to traditional methods, fostering greater deployment stability and a noticeably improved user experience. These combined effects translate directly into reduced operational costs, allowing organizations to redirect resources towards innovation and gain a substantial competitive advantage in their respective fields. The system’s ability to dynamically adapt and respond to fluctuating demands ensures sustained performance and long-term cost savings.
The pursuit of optimized resource allocation, as detailed within this framework, inherently acknowledges the transient nature of efficiency. Any gains achieved are subject to inevitable decay, demanding continuous adaptation and refinement. This echoes Donald Knuth’s observation: “Premature optimization is the root of all evil.” The system presented doesn’t aim for a static, perfect state, but rather a dynamic equilibrium-a proactive approach to anticipating and mitigating the erosion of performance across multi-cluster cloud environments. It understands that improvements, like all systems, age and require vigilant monitoring and adjustment to maintain their effectiveness over time.
What Lies Ahead?
The presented framework, while demonstrating improvements in resource orchestration, merely addresses symptoms. Multi-cluster environments are not inherently stable; they are complex systems accruing entropy. The efficiency gains achieved through predictive learning will inevitably diminish as workload patterns shift and new, unforeseen demands emerge. The system does not prevent instability, but rather delays its manifestation – a temporary reprieve in the face of inevitable decay.
Future work should not focus solely on refining predictive accuracy. A more fruitful avenue lies in understanding the fundamental limits of optimization itself. Can a system truly adapt to novelty, or is it forever bound by the patterns of the past? Investigating the interplay between proactive resource allocation and reactive resilience – the capacity to gracefully degrade when predictions inevitably fail – seems a more pressing concern.
Ultimately, the pursuit of perfect optimization is a fallacy. Time is not a metric to be conquered, but the medium within which all systems exist and ultimately dissolve. The true measure of success will not be minimizing waste, but maximizing the lifespan – however brief – of functionality within a perpetually shifting landscape.
Original article: https://arxiv.org/pdf/2512.24914.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- INJ/USD
- STX/USD
- Gold Rate Forecast
- Lord Of The Flies Review: Near-Perfect Adaptation Is A Reminder Of Classic Novel’s Haunting Power
- Man pulls car with his manhood while on fire to raise awareness for prostate cancer
- Avengers: Doomsday Spoilers & Leaks Addressed By Director Joe Russo: “It’s Over-Policed”
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Spanish nuns are saving a breed of giant rabbits from extinction
- Cavaliers vs. Pistons Game 2 Results According to NBA 2K26
- The 10 Most Intense Stephen King Thriller Books of All Time
2026-01-03 18:05