Author: Denis Avetisyan
A new modeling approach identifies and addresses critical performance bottlenecks in neuromorphic accelerators, paving the way for more efficient and scalable brain-inspired hardware.
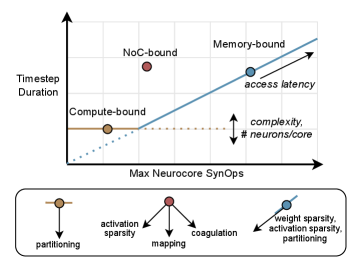
This review introduces a ‘floorline model’ to guide optimization strategies focused on sparsity and partitioning for improved performance and energy efficiency in event-driven neuromorphic systems.
Despite the promise of event-driven computation, realizing the full potential of neuromorphic accelerators remains hampered by poorly understood performance limitations. This paper, ‘Modeling and Optimizing Performance Bottlenecks for Neuromorphic Accelerators’, presents the first comprehensive analysis of these bottlenecks across three distinct accelerator architectures-Brainchip AKD1000, Synsense Speck, and Intel Loihi 2-identifying memory, compute, and traffic-bound regimes. Through a novel ‘floorline model’, we demonstrate that conventional sparsity metrics are often misleading, and propose a sparsity-aware partitioning methodology yielding up to 3.86x runtime improvement and 3.38x energy reduction at iso-accuracy. Can these insights pave the way for a new generation of workload optimization techniques tailored to the unique characteristics of neuromorphic computing?
The Inevitable Limitations of Time: Beyond the Von Neumann Machine
Traditional computer architectures are fundamentally built upon the principle of time-multiplexing, where a single processor rapidly switches between tasks to create the illusion of parallelism. This approach, however, proves inefficient when dealing with sparse, event-driven data – information that arrives irregularly and infrequently, such as signals from many sensors or the output of spiking neural networks. Because the processor must constantly cycle, even when no data is present, significant energy is wasted, and latency increases. This contrasts sharply with the brain, which processes information only when and where it is needed. The inherent inefficiency of time-multiplexing creates a computational bottleneck for applications requiring real-time processing of asynchronous data streams, hindering advancements in areas like low-power artificial intelligence, robotics, and always-on sensory devices.
The constraints of traditional computing architectures significantly impede advancements in fields reliant on efficient data handling, particularly low-power artificial intelligence and real-time sensory processing. Current systems, designed for sequential task completion, struggle with the asynchronous and sparse nature of data from sources like image sensors or microphones, leading to substantial energy waste and latency. This creates a critical bottleneck for “edge applications”-devices that perform data analysis locally, such as autonomous vehicles, wearable health monitors, and smart cameras-where immediate responses and extended battery life are paramount. The inability to efficiently process information at the source necessitates reliance on cloud computing, introducing communication delays and privacy concerns; thus, overcoming these limitations is essential for realizing the full potential of pervasive, intelligent devices.

Embracing Sparsity: The Architecture of Absence
Neuromorphic accelerators achieve efficiency gains by exploiting sparsity in both the weights and activations of neural networks. Traditional deep learning models often contain a high proportion of zero-valued parameters and outputs; neuromorphic designs are specifically engineered to avoid performing computations on these zero values. This is accomplished through specialized hardware and data representations that minimize both the number of arithmetic operations and the volume of data transferred between processing elements. By focusing computation only on non-zero elements, energy consumption and latency are significantly reduced compared to conventional architectures which process all values regardless of significance. The degree of sparsity directly impacts the potential for optimization; higher sparsity levels generally correlate with greater efficiency improvements in these accelerators.
Conventional computing architectures are predicated on dense matrix operations and regular dataflow, requiring substantial energy expenditure even when processing data with inherent redundancy. Neuromorphic computing, by contrast, explicitly exploits data sparsity, necessitating a departure from these established principles. This shift demands architectural redesigns that prioritize efficient handling of irregular, event-driven data streams, moving away from the von Neumann bottleneck and towards massively parallel, asynchronous processing models. Traditional optimization techniques focused on maximizing clock speeds and memory bandwidth are less relevant; instead, designs must focus on minimizing access to zero-valued weights and activations, and reducing communication overhead associated with sparse data representations. This fundamentally alters metrics for performance evaluation, emphasizing energy efficiency and throughput for sparse workloads rather than peak floating-point operations.
Spatially-expanded designs are critical for efficiently processing sparse data in neuromorphic systems. These architectures deviate from conventional von Neumann bottlenecks by distributing processing elements across a larger area, allowing for concurrent handling of numerous sparse events. This parallelization minimizes latency and maximizes throughput, as multiple events can be processed simultaneously rather than sequentially. The physical distribution of processing elements reduces the need for extensive data movement, further decreasing energy consumption and improving performance, particularly when dealing with highly sparse datasets where the majority of weights and activations are zero.
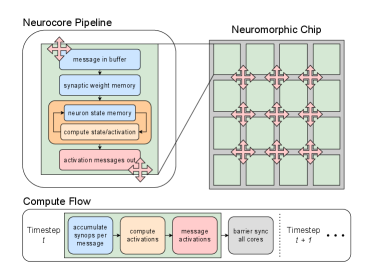
The Neurocore and the Map: Architecting Parallelism
The neurocore represents a foundational processing element designed for neural network acceleration by tightly integrating three core components: computation, memory, and communication. This integration minimizes data movement and latency, critical for performance in deep learning workloads. Computation is typically handled by an array of processing elements optimized for matrix operations. On-chip memory, comprising both static and dynamic RAM, provides fast access to weights and activations, avoiding reliance on slower off-chip memory. Finally, a dedicated communication fabric, often employing a crossbar or mesh network, facilitates data exchange between the processing elements and other neurocores, enabling parallel processing and scalability. The neurocore’s architecture is therefore characterized by its holistic approach to these three elements, differing from traditional CPU/GPU designs which maintain separation.
Achieving high throughput in neural network acceleration necessitates the strategic partitioning of network layers and their subsequent mapping to available neurocores. This process involves decomposing a neural network into sub-graphs, where each sub-graph can be processed by one or more neurocores in parallel. Effective partitioning minimizes inter-neurocore communication, reducing latency and maximizing computational parallelism. Mapping algorithms consider factors such as layer dependencies, neurocore resource availability (compute, memory), and communication bandwidth to optimize resource utilization and minimize overall execution time. Suboptimal partitioning and mapping can lead to communication bottlenecks and underutilization of available compute resources, significantly degrading performance.
Network-on-Chip (NoC) infrastructure is essential for facilitating high-bandwidth, low-latency communication between neurocores in a many-core system. Traditional bus-based interconnects become bottlenecks as the number of cores increases; NoCs address this by employing a packet-switched network topology. This allows for multiple simultaneous data transfers between neurocores, increasing overall throughput and reducing communication delays. Common NoC topologies include mesh, torus, and butterfly networks, each offering trade-offs between complexity, area, and performance. The bandwidth of an NoC is determined by the link width, clock frequency, and the number of concurrent data transfers supported. Efficient NoC design also incorporates techniques like virtual channels and adaptive routing to mitigate congestion and ensure quality of service.
Beyond the Roofline: Modeling Sparse Computation
Traditional performance modeling, particularly the Roofline model, proves inadequate when applied to neuromorphic computing systems due to fundamental architectural differences. The Roofline, designed for conventional von Neumann architectures, relies on assessing performance limitations based on arithmetic intensity – the ratio of operations to memory accesses. Neuromorphic systems, however, operate on sparse, event-driven principles, where computation is triggered by asynchronous events rather than clock cycles. This sparsity dramatically alters the relationship between operations and memory accesses, rendering the standard Roofline inaccurate. Accurately characterizing performance therefore necessitates models that account for the unique bottlenecks of neuromorphic computation, such as the overhead associated with event filtering, address decoding for sparse memory accesses, and the communication costs within massively parallel networks of neurons and synapses. Extending or developing new models is crucial for guiding the design and optimization of these emerging computational paradigms, enabling researchers to effectively explore the performance space and unlock the full potential of neuromorphic hardware.
Neuromorphic computing, with its sparse, event-driven nature, presents unique performance challenges that traditional performance models fail to adequately address. The ‘Floorline’ model emerges as a critical tool for understanding these limitations, focusing on the bottlenecks arising from memory access, computational throughput, and inter-core communication. Unlike the ‘Roofline’ model which defines an optimistic upper bound, the Floorline model establishes a pessimistic lower bound on performance, dictated by the system’s practical constraints when handling sparse data. It specifically quantifies how the rate of events – the signals driving computation – impacts the ability to fetch synaptic weights, accumulate activations, and transfer data between processing elements. By analyzing these fundamental limits, researchers can pinpoint areas for optimization in neuromorphic architectures and algorithms, ultimately guiding the development of more efficient and scalable systems that fully leverage the benefits of sparsity.
The efficiency of neuromorphic computing hinges critically on the performance of synaptic operations, specifically the fetching of synaptic weights and their subsequent accumulation during neural processing. Unlike conventional systems that rely on dense matrix operations, neuromorphic architectures operate on sparse, event-driven data, making weight access a significant bottleneck. Minimizing the energy and time required for these operations demands careful optimization strategies, including data layout techniques that reduce memory access latency and specialized hardware designs that accelerate accumulation. The computational cost is directly proportional to the number of synaptic operations performed; therefore, reducing the precision of weights, employing efficient data compression schemes, and optimizing memory hierarchy are all vital considerations for maximizing throughput and minimizing energy consumption in these emerging systems.
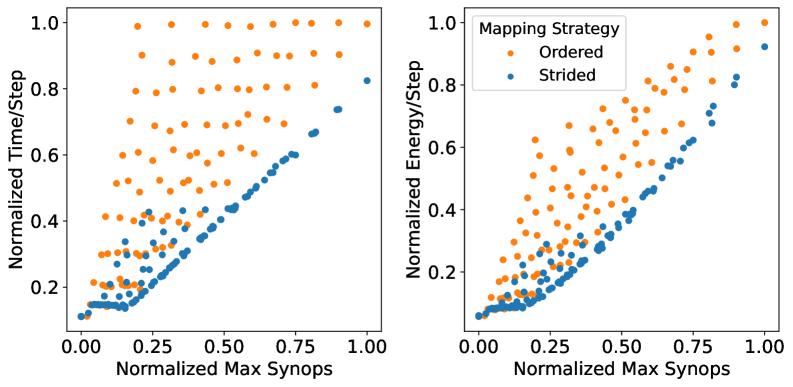
A novel two-stage optimization framework significantly enhances the performance of neuromorphic computing systems. This approach achieves up to a 3.86x reduction in runtime and a 3.38x improvement in energy efficiency when deployed on neuromorphic accelerators. The framework begins with sparsity-aware training, strategically reducing the number of synaptic connections to minimize computational demands. This is then coupled with a floorline-informed partitioning strategy, meticulously mapping the sparse network onto the accelerator’s resources to alleviate memory and communication bottlenecks – critical limitations in event-driven neuromorphic architectures. By jointly optimizing both the network’s structure and its physical implementation, this methodology unlocks substantial gains in both speed and power consumption, paving the way for more efficient and scalable neuromorphic applications.

From Theory to Silicon: Accelerators and the Promise of Intelligent Systems
Neuromorphic computing, inspired by the human brain, is moving beyond theoretical potential with the emergence of dedicated hardware platforms. Systems like Intel’s Loihi 2, the collaborative Speck chip, and the AKD1000 demonstrate the feasibility of accelerating a widening range of workloads using brain-inspired architectures. These platforms aren’t limited to specific tasks; they’ve been successfully applied to areas as diverse as audio processing and autonomous vehicle control, suggesting a versatility previously unseen in specialized accelerators. The existence of these functional systems provides a crucial validation of neuromorphic principles, shifting the focus from ‘if it can be done’ to ‘how best to deploy’ this promising new computing paradigm, and paving the way for energy-efficient solutions across numerous applications.
Neuromorphic computing is transitioning from theoretical promise to practical application, as demonstrated by advancements in areas like audio processing and autonomous systems. The S5 algorithm, implemented on Intel’s Loihi 2 platform, showcases the potential for dramatically improved audio denoising – a critical function for hearing aids, voice assistants, and communication devices. Simultaneously, the PilotNet application, also running on Loihi 2, demonstrates the feasibility of using neuromorphic hardware for the computationally intensive task of autonomous vehicle control, specifically image processing for navigation. These applications aren’t simply proofs of concept; they represent tangible steps toward deploying energy-efficient, biologically-inspired computing in real-world scenarios, paving the way for more responsive and adaptable intelligent systems.
Recent evaluations demonstrate substantial performance gains through optimization of neuromorphic hardware. Specifically, the AKD1000 platform achieved up to a 4.29x reduction in runtime and a 4.36x improvement in energy efficiency when processing certain workloads. Loihi 2, another leading neuromorphic processor, exhibited notable enhancements as well, delivering a 1.83x runtime improvement and a 1.52x reduction in energy consumption through similar optimization strategies. These results highlight the potential for neuromorphic computing to offer significant advantages in both speed and power efficiency, paving the way for deployment in resource-constrained applications and beyond.
The future of neuromorphic computing hinges on sustained advancements across multiple fronts. Current research isn’t simply about building faster chips, but refining the entire computational ecosystem. Innovations in chip architecture, such as exploring novel spiking neuron models and on-chip learning capabilities, promise to push the boundaries of performance. Simultaneously, sophisticated mapping strategies – algorithms that translate complex problems into a format suitable for neuromorphic hardware – are crucial for maximizing efficiency. Perhaps most importantly, the development of user-friendly software tools and compilers will lower the barrier to entry, allowing a wider range of researchers and developers to harness the potential of these brain-inspired computers and expand their applicability beyond specialized domains, ultimately leading to widespread adoption and transformative applications.

The pursuit of optimized neuromorphic architectures, as detailed in this study, reveals a recurring truth: systems evolve, they are not engineered into perfection. The paper’s exploration of sparsity and partitioning to overcome performance bottlenecks echoes a fundamental principle of complex systems. As Linus Torvalds observed, “Talk is cheap. Show me the code.” This isn’t merely a call for implementation, but an acknowledgement that theoretical models, like the ‘floorline model’ presented, must be validated by practical application. Belief in a flawless design is, ultimately, a denial of the inevitable entropy inherent in any complex system, especially one navigating the challenges of event-driven computing and activation sparsity.
The Horizon Recedes
The pursuit of efficiency in neuromorphic computation, as exemplified by this work, inevitably reveals not solutions, but shifting bottlenecks. Sparsity, partitioning-these are levers pulled on a complex system, momentarily easing pressure in one area only to reveal constraint elsewhere. The ‘floorline model’ offers a valuable, if transient, snapshot of performance limits, yet it is a frozen compromise. Technologies change, dependencies remain. Each optimization, however clever, introduces new forms of entanglement, new points of failure obscured by layers of abstraction.
The focus on activation sparsity and event-driven computation rightly highlights the potential for power reduction. However, the true challenge lies not merely in minimizing activity, but in managing the consequences of that minimization. What is lost in the transition to extreme sparsity? What emergent behaviors are suppressed? The architecture isn’t structure-it’s a prophecy of future failure, and a system built on brittle optimization will inevitably fracture along predictable lines.
Future work will undoubtedly refine these models, explore novel partitioning schemes, and chase ever-elusive gains in performance. But a more fruitful path may lie in accepting the inherent limitations of these substrates, and shifting the focus from optimization to resilience. For systems aren’t tools-they’re ecosystems, and the most valuable innovation may be the ability to adapt, not to control.
Original article: https://arxiv.org/pdf/2511.21549.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
2025-11-30 22:40