Author: Denis Avetisyan
Researchers have created a new dataset of labeled emails to test the ability of advanced artificial intelligence to identify malicious messages and understand the emotional tactics used in online scams.
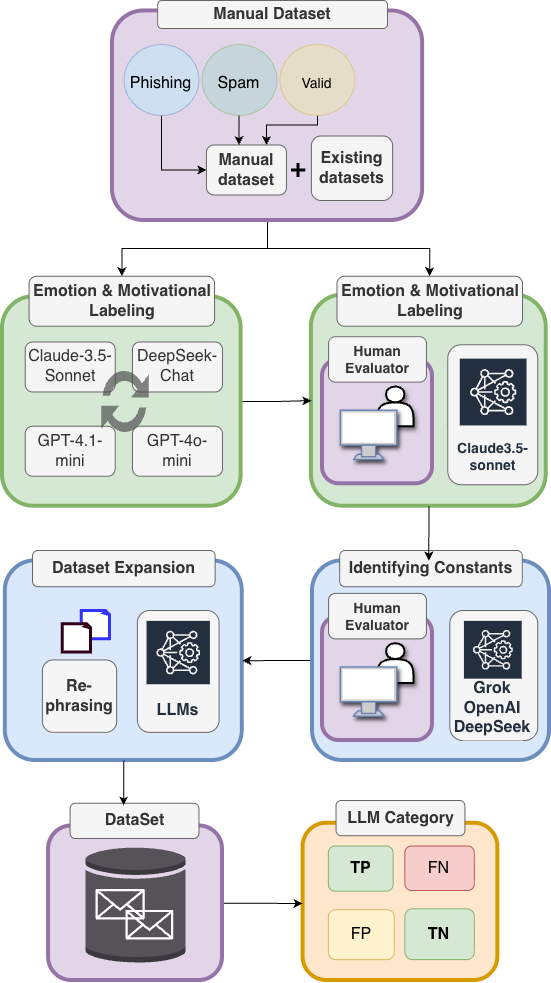
A richly annotated email dataset demonstrates that large language models excel at detecting phishing attempts and emotional cues, but struggle to differentiate between spam and legitimate content.
Despite advances in cybersecurity, distinguishing increasingly sophisticated phishing and spam emails remains a significant challenge. This is addressed in ‘Constructing and Benchmarking: a Labeled Email Dataset for Text-Based Phishing and Spam Detection Framework’, which introduces a new, richly annotated dataset designed to evaluate the performance of Large Language Models (LLMs) in identifying malicious intent and emotional manipulation within email content. Our findings demonstrate that state-of-the-art LLMs exhibit strong capabilities in detecting phishing attempts and recognizing emotional cues, even when emails are rephrased, yet consistently struggle with the nuanced distinction between spam and legitimate communications. Will these persistent limitations necessitate novel approaches to email filtering and user education to effectively mitigate evolving threats?
The Inevitable Erosion of Security: Confronting Evolving Threats
Contemporary email security systems, built upon decades of rule-based filtering and signature detection, are increasingly challenged by the ingenuity of malicious actors. These traditional methods, effective against mass-sent, poorly-crafted campaigns, falter when confronted with personalized attacks that mimic legitimate communication. Phishing emails now routinely bypass basic spam filters through techniques like URL shortening, image-based content designed to evade text analysis, and the incorporation of current events to appear timely and relevant. Furthermore, attackers are adept at utilizing compromised accounts to send emails with established reputations, effectively sidestepping reputation-based blocking systems. The escalating sophistication necessitates a shift beyond simple pattern matching towards more contextual and behavioral analysis to accurately identify and neutralize these evolving threats.
The proliferation of large language models (LLMs) has fundamentally altered the landscape of email-based threats, demanding a shift beyond traditional detection techniques. Attackers are now adept at crafting highly persuasive and contextually relevant phishing emails that bypass keyword-based filters, leveraging LLMs to generate realistic and grammatically correct content. This represents a significant challenge, as these models can dynamically tailor messages to specific targets, mimicking legitimate communication styles and evading detection based on superficial characteristics. Consequently, security systems must move beyond simply identifying malicious keywords and instead focus on a deeper understanding of email content – analyzing the intent, context, and subtle linguistic cues that differentiate genuine communication from sophisticated, LLM-generated attacks. This requires advanced analytical methods capable of discerning the how and why behind the message, rather than simply what it says.
Effective email classification transcends simple content analysis, demanding a comprehension of the communicative intent behind each message. Traditional methods often focus on keywords or sender reputation, proving insufficient against attackers who skillfully manipulate language or leverage compromised accounts. A truly robust system must assess how information is presented – the tone, style, and psychological cues employed – and, crucially, why a message was sent. This necessitates analyzing the underlying goals of the communication: is it seeking information, requesting action, attempting to deceive, or building rapport? By moving beyond surface-level features and delving into the pragmatics of language, email security can adapt to increasingly sophisticated threats that exploit the nuances of human interaction, recognizing malicious intent even when disguised within seemingly legitimate content.
Decoding Intent: LLM-Powered Analysis of Email Communication
Email classification is performed utilizing Large Language Models (LLMs), with Claude 3.5 Sonnet as the current implementation. This approach moves beyond traditional keyword-based methods to analyze email content for both emotional cues and motivational intent. Emotional analysis identifies the sender’s expressed sentiment, while motivational intent assessment determines the underlying purpose of the communication – such as requesting action, offering assistance, or attempting to persuade. Combining these two analytical dimensions enables a more nuanced understanding of email content and facilitates the detection of potentially malicious or harmful communications.
The identification of emotional cues and motivational intent within email content is a core component of malicious intent detection. This process analyzes textual data for indicators of manipulation, urgency, or threat, evaluating the sender’s attempt to elicit a specific response from the recipient. Emotional cues are identified through sentiment analysis and the detection of emotionally charged language, while motivational intent is determined by assessing the stated or implied goals of the communication – such as prompting immediate action, requesting sensitive information, or inducing a sense of fear or obligation. Discrepancies between stated intent and emotional tone, or the presence of manipulative language patterns, are flagged as potential indicators of malicious activity.
Reliable performance of our LLM-powered email analysis relies heavily on the quality of the training dataset. Dataset construction involved careful curation and labeling of email content to accurately represent the range of emotional cues and motivational intents indicative of malicious activity. This approach yielded a stable classification accuracy of approximately 66-67% when evaluated using Claude 3.5 Sonnet. The dataset’s size and representativeness are critical factors influencing the model’s ability to generalize and accurately classify unseen emails, and ongoing refinement of the dataset is planned to further improve performance.
Testing the Limits: Robustness Through Simulated Linguistic Drift
To evaluate the robustness of the email classification model, a content rephrasing technique was implemented. This involved systematically altering the phrasing of email content using large language models while deliberately maintaining the original semantic meaning. The purpose of this approach was to simulate paraphrasing attacks – attempts to evade detection by changing wording without altering the underlying intent of the email. By assessing model performance on these rephrased examples, we could determine its resilience to variations in linguistic expression and its ability to focus on the core message rather than specific keywords or phrasing.
Paraphrasing of the original email dataset was automated using large language models (LLMs), specifically GPT-4 and DeepSeek-Chat. These LLMs were prompted to generate variations of each email while preserving the original intent and semantic meaning. This process involved re-wording sentences, substituting synonyms, and altering sentence structure. The resulting paraphrased emails were then used as input to the Email Classification model, allowing for evaluation of performance on content that differed stylistically from the training data but retained the same underlying information.
Evaluation of the LLM-based Email Classification model involved assessing its performance on a dataset of rephrased emails generated using large language models. Analysis of this data revealed consistent accuracy rates of 66-67% on the paraphrased content, indicating the model’s ability to correctly classify emails despite alterations in phrasing while preserving semantic meaning. This sustained accuracy demonstrates a degree of robustness against paraphrasing attacks, suggesting the classification model is not overly reliant on specific word choices or sentence structures.
Quantifying Understanding: Validating Analysis with Jaccard Similarity
To ensure a robust and impartial assessment of emotional and motivational analyses, researchers employed Jaccard Similarity, a statistical measure quantifying the overlap between predicted labels and ground truth data. This metric, calculated as the size of the intersection divided by the size of the union of the predicted and actual label sets, provides a clear and objective indication of agreement – a value of 1 representing complete overlap, while 0 signifies no shared labels. By utilizing Jaccard Similarity, the evaluation moved beyond subjective interpretations, offering a quantifiable benchmark for comparing the performance of different large language models in discerning complex human sentiments and underlying motivations. This approach facilitated a rigorous determination of which models most accurately capture the nuances of emotional and motivational states, ultimately strengthening the validity of the findings.
The evaluation of large language models requires more than anecdotal evidence; a quantifiable method for comparing predicted outputs to established truths is essential. To this end, Jaccard Similarity served as a crucial metric, effectively measuring the overlap between the labels assigned by the models and the actual, ground-truth labels. This approach transforms subjective assessments into objective scores, allowing for a rigorous and statistically sound comparison of model performance. By calculating the size of the intersection divided by the size of the union of predicted and actual labels, researchers can precisely determine the degree of agreement, revealing which models demonstrate the strongest ability to accurately categorize emotional and motivational content. This focus on quantifiable overlap ensures that improvements in model performance are demonstrably measurable and not merely perceived.
Evaluations demonstrated that Claude 3.5 Sonnet excelled in discerning emotional and motivational nuances when compared to other large language models, including GPT-4o-mini, GPT-4.1-mini, and DeepSeek-Chat. The model achieved a Jaccard Similarity score of 0.60 for emotion labeling, indicating a substantial overlap between its predicted emotional states and the ground truth. Furthermore, Claude 3.5 Sonnet attained a 42% ‘close-enough’ accuracy in motivation labeling, signifying its capacity to approximate underlying motivational factors with greater precision than its counterparts. These results highlight the model’s potential for applications requiring accurate interpretation of complex human affective and motivational states.
The pursuit of robust email security, as detailed in this study, reveals a familiar pattern: systems built to withstand current threats inevitably face novel challenges. The researchers demonstrate LLMs’ proficiency in identifying malicious intent even through paraphrasing, yet their struggle with differentiating spam highlights an inherent limitation. As Claude Shannon observed, “The most important thing in communication is to convey the meaning, not just the message.” This dataset and the LLM evaluations demonstrate that detecting meaning-the underlying intent-is far more complex than simple content filtering. The decay isn’t a failure of the system, but a testament to the evolving nature of communication itself, and the constant need for adaptation.
What’s Next?
The pursuit of automated email security, as demonstrated by this work, inevitably encounters the limitations inherent in all systems. The capacity of large language models to identify malicious intent, even in paraphrased communications, is notable – a testament to pattern recognition rather than genuine understanding. Yet, the difficulty in consistently differentiating between unsolicited commercial communication and legitimate content suggests a fundamental blurring of boundaries, a decay of signal in the noise. Systems learn to age gracefully when their creators accept that perfect classification is an asymptotic goal, never fully realized.
Future efforts will likely focus on refining the nuances of legitimate communication, perhaps by incorporating behavioral models of sender and receiver. However, a more fruitful avenue may lie in accepting a degree of ‘false positive’ identification. Treating potentially unwanted communication with increased scrutiny – a gentle quarantine, if you will – may prove more effective than striving for absolute certainty. The cost of missed threats outweighs the inconvenience of cautious filtering.
Ultimately, this research reinforces a simple truth: cybersecurity is not a problem to be solved, but a process to be managed. Sometimes observing the process-cataloging the evolving tactics of deception and the subtle shifts in communication norms-is better than trying to speed it up. The system will adapt, and so must the defenses, but with a recognition that entropy is not an enemy, but an inherent property of the medium.
Original article: https://arxiv.org/pdf/2511.21448.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- EUR ZAR PREDICTION
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
2025-11-29 14:37