Author: Denis Avetisyan
A new framework leverages the power of artificial intelligence to create challenging and realistic driving scenarios, helping to validate the safety of self-driving systems.

This work introduces a method combining large language models and conditional variational autoencoders to generate diverse safety-critical scenarios for robust autonomous driving validation.
Robust validation of autonomous driving systems demands exposure to rare, yet critical, events largely absent in real-world datasets. This limitation motivates the work presented in ‘Learning from Risk: LLM-Guided Generation of Safety-Critical Scenarios with Prior Knowledge’, which introduces a novel framework integrating a conditional variational autoencoder with a large language model to generate diverse and realistic traffic scenarios. By leveraging LLMs to dynamically guide scenario creation based on risk assessment and prior knowledge, the approach demonstrably increases coverage of challenging events and improves the fidelity of simulated traffic distributions. Could this knowledge-driven approach redefine safety validation protocols and accelerate the deployment of truly robust autonomous vehicles?
The Inherent Limitations of Empirical Validation
Autonomous vehicle development currently depends on extensive real-world driving data, with datasets like NuScenes and HighD serving as foundational resources for training and validation. However, these datasets inherently struggle with the “long tail” of infrequent but potentially catastrophic events – scenarios like a child darting into the road, an unusual vehicle malfunction, or extremely rare weather conditions. While capturing millions of miles of driving provides a broad base of operational data, it statistically underrepresents these critical edge cases, meaning a system trained solely on this data may perform well in typical situations but fail unpredictably when confronted with the unexpected. This limitation necessitates supplementary validation techniques capable of proactively addressing these rare occurrences, as simply accumulating more real-world data offers diminishing returns in improving safety and reliability in the face of the long tail.
The pursuit of safer autonomous vehicles often centers on data – yet simply amassing greater quantities of real-world driving footage presents significant limitations. While seemingly intuitive, this approach quickly becomes computationally prohibitive, demanding ever-increasing storage and processing power. More critically, even enormous datasets struggle to represent the sheer diversity of possible driving scenarios, particularly the infrequent but potentially catastrophic events that define the “long tail” of risk. A system trained solely on observed data may perform well in common situations, but remains vulnerable when confronted with novel or rare hazards not adequately represented in its training material. This highlights a fundamental challenge: achieving true robustness requires more than just more data; it demands a strategic approach to scenario selection and generation.
Current autonomous vehicle validation techniques often fall short because they react to existing data rather than actively seeking out system vulnerabilities. Traditional methods rely on replaying recorded scenarios or slightly perturbing them, which fails to efficiently expose edge cases and rarely challenges the core decision-making processes of the autonomous system. This reactive approach means critical weaknesses – those concerning unusual combinations of events or unforeseen environmental conditions – remain hidden until encountered in real-world operation. Consequently, developers struggle to build truly robust systems capable of handling the unpredictable nature of driving, as the validation process isn’t designed to proactively stress-test the vehicle’s perception, planning, and control algorithms against specifically engineered, challenging scenarios that target known or suspected limitations.

Constructing Simulated Realities: CVAE and Graph Neural Networks
A conditional variational autoencoder (CVAE) serves as the primary component for generating base traffic scenarios. The CVAE is a generative model that learns the underlying distribution of observed traffic data, specifically trajectories and agent interactions. By conditioning the CVAE on specific parameters – such as road network information or high-level behavioral goals – the model can generate new, plausible scenarios that adhere to the learned distribution. This allows for the creation of diverse and realistic traffic simulations without requiring manual scenario design. The CVAE outputs a probabilistic representation of the scenario, enabling sampling and variation in generated scenarios.
The integration of a graph neural network (GNN) with the conditional variational autoencoder (CVAE) facilitates the modeling of complex relationships within the driving environment. The GNN processes agent interactions and contextual elements-such as relative positions, velocities, and lane connectivity-as nodes and edges within a graph structure. This graph-based representation is then used to encode contextual information, providing the CVAE with a more comprehensive understanding of the scenario beyond individual agent states. This allows the CVAE to generate scenarios that accurately reflect realistic multi-agent behaviors and environmental dependencies, improving the fidelity of the generated traffic simulations.
Evaluation of the integrated conditional variational autoencoder (CVAE) and graph neural network (GNN) demonstrates a high degree of accuracy in reconstructing driving scenarios. Quantitative analysis on the highD and nuScenes datasets yields a reconstruction error of less than $0.5 \text{ m}^2$. This metric, representing the average squared difference between predicted and actual agent positions, indicates that the generated scenarios closely reflect the original data distributions and maintain fidelity in representing complex interactions within the driving environment. The low reconstruction error confirms the model’s capacity to effectively learn and reproduce realistic traffic situations.

Intelligent Amplification of Risk with Linguistic Guidance
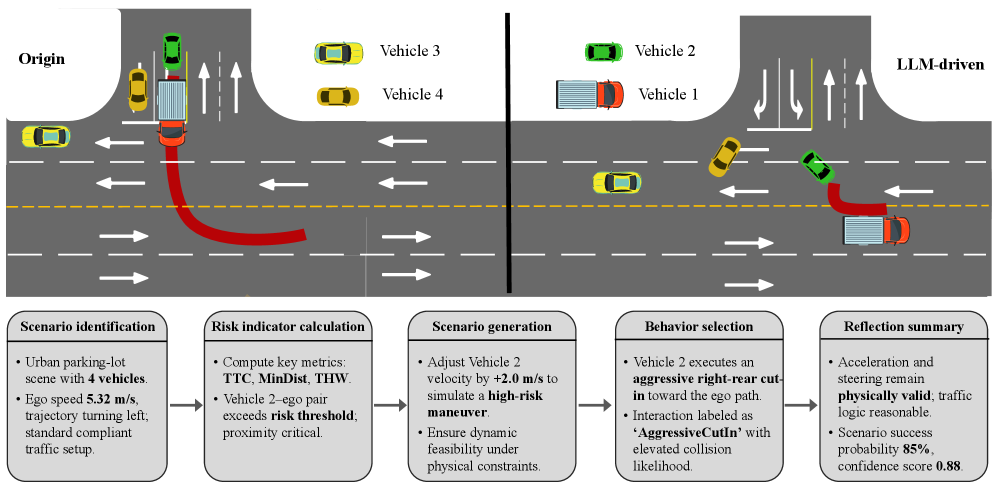
The Conditional Variational Autoencoder (CVAE) framework is augmented with a large language model (LLM) to enhance scenario generation for autonomous systems. This integration allows for the interpretation of scene semantics, enabling the LLM to analyze potential risks present within a generated or real-world driving context. Crucially, the LLM dynamically adjusts the loss functions of the CVAE during scenario creation, focusing the generative process on amplifying specific risk factors. This adaptive loss weighting ensures the generated scenarios prioritize and emphasize potentially hazardous situations, improving the robustness of testing and validation procedures.
The system utilizes a large language model (LLM) integrated with a Physics-Based Risk Model to proactively identify and accentuate potentially dangerous scenarios. This model is parameterized by computed risk indicators, specifically Time-To-Collision (TTC), Time-Headway (THW), and Time-Loss-Control (TLC). These indicators provide quantitative measures of risk, allowing the LLM to assess the severity of developing situations. By continuously monitoring $TTC$, $THW$, and $TLC$, the model can dynamically adjust scenario generation to focus on amplifying conditions where these risk indicators suggest an elevated probability of hazardous events, thereby improving the realism and effectiveness of testing for critical driving scenarios.
Evaluation demonstrates that the proposed system achieves 22.8% coverage of long-tail traffic events, representing a 5.8 percentage point improvement over the 17% coverage achieved by the baseline system. Specifically, the system generates aggressive cut-in scenarios with a success probability of 85%. Scenario success is determined by the ability of the system to consistently identify and recreate potentially hazardous situations, thereby enhancing the robustness of testing and validation procedures for autonomous vehicle systems. These metrics indicate a statistically significant improvement in the identification and reproduction of rare but critical driving scenarios.

Robust Validation Through Comprehensive Simulation
The adversarial scenario generation pipeline is engineered for direct integration with leading high-fidelity simulation platforms, notably CARLA Simulator and SMARTS Simulator. This deliberate design choice enables the creation of realistic and challenging driving conditions within virtual environments that accurately mimic real-world complexities. By operating seamlessly within these simulators, the pipeline facilitates large-scale, automated testing of autonomous vehicle systems, offering a controlled and repeatable means of evaluating performance across a diverse range of potentially hazardous situations. The ability to run countless simulations quickly and reliably is crucial for identifying edge cases and vulnerabilities before deployment, ultimately bolstering the safety and dependability of self-driving technology.
The capacity for large-scale testing represents a pivotal advancement in autonomous vehicle development. Traditional methods often rely on limited real-world mileage or painstakingly crafted scenarios, hindering comprehensive validation. Utilizing simulation environments enables the generation of countless driving situations, far exceeding what is practically achievable on physical roads. This controlled and repeatable process is crucial for identifying edge cases and vulnerabilities in autonomous systems. By subjecting algorithms to a diverse range of simulated challenges – from typical commutes to rare and hazardous events – developers can rigorously assess performance and build confidence in the safety and reliability of self-driving technology. The ability to consistently recreate specific conditions also facilitates targeted debugging and iterative improvement, accelerating the path towards deployment of robust autonomous vehicles.
The generated long-tail scenarios demonstrate a strong level of realism and statistical alignment with real-world driving data. Achieving a confidence score of 0.88 signifies a high degree of certainty in the authenticity and relevance of these simulated events. Further substantiating this fidelity, Kullback-Leibler (KL) Divergence values, which measure the difference between the distribution of accelerations in the generated scenarios and those observed in actual driving, ranged from 1.08 to 2.75. These values indicate a close match in acceleration patterns, suggesting the scenarios effectively capture the nuances of human driving behavior and provide a robust basis for evaluating the performance of autonomous systems under challenging and uncommon conditions. This distributional fidelity is critical for ensuring that validation testing translates effectively to real-world safety and reliability.
The pursuit of robust autonomous systems demands a meticulous approach to validation, recognizing that comprehensive testing relies on exposure to a diverse range of challenging scenarios. This work, integrating LLMs and CVAEs for safety-critical scenario generation, aligns with a fundamental principle of mathematical rigor. As Barbara Liskov stated, “Programs must be correct, not just work.” The framework doesn’t merely aim to produce scenarios; it strives to generate them based on prior knowledge and inherent risks, ensuring a logical completeness in the validation suite. This is vital to bridge the sim-to-real gap and guarantee system reliability, not just observed functionality. The emphasis on generating rare, yet crucial, events exemplifies a commitment to thoroughness, mirroring the need for provable correctness in algorithmic design.
What Remains Constant?
The pursuit of robust autonomous systems hinges on exhaustive validation, and this work rightly identifies the scarcity of truly critical scenarios as a fundamental impediment. The integration of Large Language Models with generative models offers a pragmatic, if not entirely satisfying, approach. However, let N approach infinity – what remains invariant? The statistical guarantee of completeness. Generating more scenarios, even those informed by prior knowledge, does not address the core issue: the impossibility of exhaustively enumerating all potential edge cases within a complex, dynamic environment.
Future efforts must move beyond simply increasing scenario diversity. A more fruitful avenue lies in formal verification techniques, perhaps leveraging LLMs not for scenario generation, but for the automated construction of provably safe operational boundaries. The current reliance on simulation, even ‘sim-to-real’ transfer, remains an approximation. A truly elegant solution will not merely demonstrate performance on a vast dataset, but mathematically guarantee system behavior under all foreseeable – and unforeseeable – conditions.
The question, then, is not whether these systems can ‘learn’ from risk, but whether they can be constructed with inherent, verifiable safety. The elegance of a solution is not measured by its empirical success, but by the purity of its underlying logic. Until that logical foundation is established, the pursuit of ever-more-realistic scenarios remains a computationally expensive, and ultimately incomplete, exercise.
Original article: https://arxiv.org/pdf/2511.20726.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Brent Oil Forecast
- Infinity Nikki Candlelight Reverie Challenge and Rewards Guide
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
- 10 Indie Games that Really Felt Like the Start of a New Era
2025-11-28 10:00